Last updated on January 7, 2026
AWS Data Pipeline Cheat Sheet
- AWS Data Pipeline is no longer available to new customers, but existing pipelines continue to run and can be managed by current users.
- A web service for scheduling regular data movement and data processing activities in the AWS cloud. Data Pipeline integrates with on-premise and cloud-based storage systems.
- A managed ETL (Extract-Transform-Load) service.
- Native integration with S3, DynamoDB, RDS, EMR, EC2, and Redshift.

Features
- You can quickly and easily provision pipelines that remove the development and maintenance effort required to manage your daily data operations, letting you focus on generating insights from that data.
- Data Pipeline provides built-in activities for common actions such as copying data between Amazon Amazon S3 and Amazon RDS or running a query against Amazon S3 log data.
- Data Pipeline supports JDBC, RDS, and Redshift databases.
Components
- A pipeline definition specifies the business logic of your data management.
- A pipeline schedules and runs tasks by creating EC2 instances to perform the defined work activities.
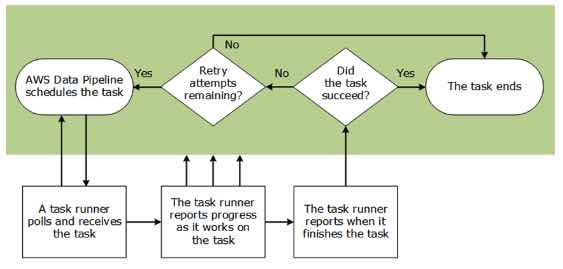
- Task Runner polls for tasks and then performs those tasks. For example, Task Runner could copy log files to S3 and launch EMR clusters. Task Runner is installed and runs automatically on resources created by your pipeline definitions. You can write a custom task runner application, or you can use the Task Runner application that is provided by Data Pipeline.
Pipeline Definition
- From your pipeline definition, Data Pipeline determines the tasks, schedules them, and assigns them to task runners.
- If a task is not completed successfully, Data Pipeline retries the task according to your instructions and, if necessary, reassigns it to another task runner. If the task fails repeatedly, you can configure the pipeline to notify you.
- A pipeline definition can contain the following types of components
- Data Nodes – The location of input data for a task or the location where output data is to be stored.
- Activities – A definition of work to perform on a schedule using a computational resource and typically input and output data nodes.
- Preconditions – A conditional statement that must be true before an action can run. There are two types of preconditions:
- System-managed preconditions are run by the Data Pipeline web service on your behalf and do not require a computational resource.
- User-managed preconditions only run on the computational resource that you specify using the runsOn or workerGroup fields. The workerGroup resource is derived from the activity that uses the precondition.
- Scheduling Pipelines – Defines the timing of a scheduled event, such as when an activity runs. There are three types of items associated with a scheduled pipeline:
- Pipeline Components – Specify the data sources, activities, schedule, and preconditions of the workflow.
- Instances – Data Pipeline compiles the running pipeline components to create a set of actionable instances. Each instance contains all the information for performing a specific task.
- Attempts – To provide robust data management, Data Pipeline retries a failed operation. It continues to do so until the task reaches the maximum number of allowed retry attempts.
- Resources – The computational resource that performs the work that a pipeline defines.
- Actions – An action that is triggered when specified conditions are met, such as the failure of an activity.
- Schedules – Define when your pipeline activities run and the frequency with which the service expects your data to be available. All schedules must have a start date and a frequency.
Task Runners
- When Task Runner is installed and configured, it polls Data Pipeline for tasks associated with pipelines that you have activated.
- When a task is assigned to Task Runner, it performs that task and reports its status back to Data Pipeline.
AWS Data Pipeline vs Amazon Simple WorkFlow
- Both services provide execution tracking, handling retries and exceptions, and running arbitrary actions.
- AWS Data Pipeline is specifically designed to facilitate the specific steps that are common across a majority of data-driven workflows.
AWS Data Pipeline Pricing
- You are billed based on how often your activities and preconditions are scheduled to run and where they run (AWS or on-premises).
Note: If you are studying for the AWS Certified Data Analytics Specialty exam, we highly recommend that you take our AWS Certified Data Analytics – Specialty Practice Exams and read our Data Analytics Specialty exam study guide.

AWS Data Pipeline Cheat Sheet References:
https://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide
https://aws.amazon.com/datapipeline/pricing/
https://aws.amazon.com/datapipeline/faqs/
🌸 25% OFF All Reviewers on our International Women’s Month Sale Extension! Save 10% OFF All Subscription Plans & 5% OFF Store Credits/Gift Cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin


Written by: Jon Bonso
Jon Bonso is the co-founder of Tutorials Dojo, an EdTech startup and an AWS Digital Training Partner that provides high-quality educational materials in the cloud computing space. He graduated from Mapúa Institute of Technology in 2007 with a bachelor's degree in Information Technology. Jon holds 10 AWS Certifications and is also an active AWS Community Builder since 2020.



