Last updated on December 9, 2025
Here are 10 AWS Certified DevOps Engineer Professional DOP-C02 practice exam questions to help you gauge your readiness for the actual exam.
Question 1
An application is hosted in an Auto Scaling group of Amazon EC2 instances with public IP addresses in a public subnet. The instances are configured with a user data script which fetch and install the required system dependencies of the application from the Internet upon launch. A change was recently introduced to prohibit any Internet access from these instances to improve the security but after its implementation, the instances could not get the external dependencies anymore. Upon investigation, all instances are properly running but the hosted application is not starting up completely due to the incomplete installation.
Which of the following is the MOST secure solution to solve this issue and also ensure that the instances do not have public Internet access?
- Download all of the external application dependencies from the public Internet and then store them to an S3 bucket. Set up a VPC endpoint for the S3 bucket and then assign an IAM instance profile to the instances in order to allow them to fetch the required dependencies from the bucket.
- Deploy the Amazon EC2 instances in a private subnet and associate Elastic IP addresses on each of them. Run a custom shell script to disassociate the Elastic IP addresses after the application has been successfully installed and is running properly.
- Use a NAT gateway to disallow any traffic to the VPC which originated from the public Internet. Deploy the Amazon EC2 instances to a private subnet then set the subnet’s route table to use the NAT gateway as its default route.
- Set up a brand new security group for the Amazon EC2 instances. Use a whitelist configuration to only allow outbound traffic to the site where all of the application dependencies are hosted. Delete the security group rule once the installation is complete. Use AWS Config to monitor the compliance.
Question 2
A DevOps engineer has been tasked to implement a reliable solution to maintain all of their Windows and Linux servers both in AWS and in on-premises data center. There should be a system that allows them to easily update the operating systems of their servers and apply the core application patches with minimum management overhead. The patches must be consistent across all levels in order to meet the company’s security compliance.
Which of the following is the MOST suitable solution that you should implement?
- Configure and install AWS Systems Manager agent on all of the EC2 instances in your VPC as well as your physical servers on-premises. Use the Systems Manager Patch Manager service and specify the required Systems Manager Resource Groups for your hybrid architecture. Utilize a preconfigured patch baseline and then run scheduled patch updates during maintenance windows.
- Configure and install the AWS OpsWorks agent on all of your EC2 instances in your VPC and your on-premises servers. Set up an OpsWorks stack with separate layers for each OS then fetch a recipe from the Chef supermarket site (supermarket.chef.io) to automate the execution of the patch commands for each layer during maintenance windows.
- Develop a custom python script to install the latest OS patches on the Linux servers. Set up a scheduled job to automatically run this script using the cron scheduler on Linux servers. Enable Windows Update in order to automatically patch Windows servers or set up a scheduled task using Windows Task Scheduler to periodically run the python script.
- Store the login credentials of each Linux and Windows servers on the AWS Systems Manager Parameter Store. Use Systems Manager Resource Groups to set up one group for your Linux servers and another one for your Windows servers. Remotely login, run, and deploy the patch updates to all of your servers using the credentials stored in the Systems Manager Parameter Store and through the use of the Systems Manager Run Command.
Correct Answer: 1
AWS Systems Manager Patch Manager automates the process of patching managed instances with both security-related and other types of updates. You can use the Patch Manager to apply patches for both operating systems and applications. (On Windows Server, application support is limited to updates for Microsoft applications.) You can patch fleets of Amazon EC2 instances or your on-premises servers and virtual machines (VMs) by operating system type. This includes supported versions of Windows Server, Ubuntu Server, Red Hat Enterprise Linux (RHEL), SUSE Linux Enterprise Server (SLES), CentOS, Amazon Linux, and Amazon Linux 2. You can scan instances to see only a report of missing patches, or you can scan and automatically install all missing patches.

Patch Manager uses patch baselines, which include rules for auto-approving patches within days of their release, as well as a list of approved and rejected patches. You can install patches on a regular basis by scheduling patching to run as a Systems Manager maintenance window task. You can also install patches individually or to large groups of instances by using Amazon EC2 tags. You can add tags to your patch baselines themselves when you create or update them.
A resource group is a collection of AWS resources that are all in the same AWS Region and that match criteria provided in a query. You build queries in the AWS Resource Groups (Resource Groups) console or pass them as arguments to Resource Groups commands in the AWS CLI.
With AWS Resource Groups, you can create a custom console that organizes and consolidates information based on criteria that you specify in tags. After you add resources to a group you created in Resource Groups, use AWS Systems Manager tools such as Automation to simplify management tasks on your resource group. You can also use the resource groups you create as the basis for viewing monitoring and configuration insights in Systems Manager.
Hence, the correct answer is: Configure and install AWS Systems Manager agent on all of the EC2 instances in your VPC as well as your physical servers on-premises. Use the Systems Manager Patch Manager service and specify the required Systems Manager Resource Groups for your hybrid architecture. Utilize a preconfigured patch baseline and then run scheduled patch updates during maintenance windows.
The option which uses an AWS OpsWorks agent is incorrect because the OpsWorks service is primarily used for application deployment and not for applying application patches or upgrading the operating systems of your servers.
The option which uses a custom python script is incorrect because this solution entails a high management overhead since you need to develop a new script and maintain a number of cron schedulers in your Linux servers and Windows Task Scheduler jobs on your Windows servers.
The option which uses the AWS Systems Manager Parameter Store is incorrect because this is not a suitable service to use to handle the patching activities of your servers. You have to use AWS Systems Manager Patch Manager instead.
References:
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-patch.html
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-resource-groups.html
Check out this AWS Systems Manager Cheat Sheet:
https://tutorialsdojo.com/aws-systems-manager/
Question 3
A fast-growing company has multiple AWS accounts which are consolidated using AWS Organizations and they expect to add new accounts soon. As the DevOps engineer, you were instructed to design a centralized logging solution to deliver all of their VPC Flow Logs and CloudWatch Logs across all of their sub-accounts to their dedicated Audit account for compliance purposes. The logs should also be properly indexed in order to perform search, retrieval, and analysis.
Which of the following is the MOST suitable solution that you should implement to meet the above requirements?
- In the Audit account, launch a new Lambda function which will send all VPC Flow Logs and CloudWatch Logs to an Amazon OpenSearch cluster. Use a CloudWatch subscription filter in the sub-accounts to stream all of the logs to the Lambda function in the Audit account.
- In the Audit account, create a new stream in Kinesis Data Streams and a Lambda function that acts as an event handler to send all of the logs to the Amazon OpenSearch cluster. Create a CloudWatch subscription filter and use Kinesis Data Streams to stream all of the VPC Flow Logs and CloudWatch Logs from the sub-accounts to the Kinesis data stream in the Audit account.
- In the Audit account, create an Amazon SQS queue that will push all logs to an Amazon OpenSearch cluster. Use a CloudWatch subscription filter to stream both VPC Flow Logs and CloudWatch Logs from their sub-accounts to the SQS queue in the Audit account.
- In the Audit account, launch a new Lambda function which will push all of the required logs to a self-hosted OpenSearch cluster in a large EC2 instance. Integrate the Lambda function to a CloudWatch subscription filter to collect all of the logs from the sub-accounts and stream them to the Lambda function deployed in the Audit account.

Correct Answer: 2
You can load streaming data into your Amazon OpenSearch Service domain from many different sources in AWS. Some sources, like Amazon Data Firehose and Amazon CloudWatch Logs, have built-in support for Amazon OpenSearch Service (successor to Amazon ElasticSearch). Others, like Amazon S3, Amazon Kinesis Data Streams, and Amazon DynamoDB, use AWS Lambda functions as event handlers. The Lambda functions respond to new data by processing it and streaming it to your domain.

You can use subscriptions to get access to a real-time feed of log events from CloudWatch Logs and have it delivered to other services such as an Amazon Kinesis stream, Amazon Data Firehose stream, or AWS Lambda for custom processing, analysis, or loading to other systems. To begin subscribing to log events, create the receiving source, such as a Kinesis stream, where the events will be delivered. A subscription filter defines the filter pattern to use for filtering which log events get delivered to your AWS resource, as well as information about where to send matching log events to.
You can collaborate with an owner of a different AWS account and receive their log events on your AWS resources, such as an Amazon Kinesis stream (this is known as cross-account data sharing). For example, this log event data can be read from a centralized Amazon Kinesis stream to perform custom processing and analysis. Custom processing is especially useful when you collaborate and analyze data across many accounts. For example, a company’s information security group might want to analyze data for real-time intrusion detection or anomalous behaviors so it could conduct an audit of accounts in all divisions in the company by collecting their federated production logs for central processing.
A real-time stream of event data across those accounts can be assembled and delivered to the information security groups, who can use Kinesis to attach the data to their existing security analytic systems. Kinesis streams are currently the only resource supported as a destination for cross-account subscriptions.
Hence, the correct solution is: In the Audit account, create a new stream in Kinesis Data Streams and a Lambda function that acts as an event handler to send all of the logs to the Amazon OpenSearch cluster. Create a CloudWatch subscription filter and use Kinesis Data Streams to stream all of the VPC Flow Logs and CloudWatch Logs from the sub-accounts to the Kinesis data stream in the Audit account.
The option that says: In the Audit account, launch a new Lambda function that will send all VPC Flow Logs and CloudWatch Logs to an Amazon OpenSearch cluster. Use a CloudWatch subscription filter in the sub-accounts to stream all of the logs to the Lambda function in the Audit account is incorrect. Launching a Kinesis data stream is a more suitable option than just a Lambda function that will accept the logs from other accounts and send them to Amazon OpenSearch.
The option that says: In the Audit account, create an Amazon SQS queue that will push all logs to an Amazon OpenSearch cluster. Use a CloudWatch subscription filter to stream both VPC Flow Logs and CloudWatch Logs from their sub-accounts to the SQS queue in the Audit account is incorrect because the CloudWatch subscription filter doesn’t directly support SQS. You should use a Kinesis Data Stream, Kinesis Firehose or Lambda function.
The option that says: In the Audit account, launch a new Lambda function, which will push all of the required logs to a self-hosted OpenSearch cluster in a large EC2 instance. Integrate the Lambda function to a CloudWatch subscription filter to collect all of the logs from the sub-accounts and stream them to the Lambda function deployed in the Audit account is incorrect. It is better to use Amazon OpenSearch Service instead of launching a self-hosted OpenSearch cluster. Launching a Kinesis data stream is a more suitable option than just a Lambda function that will accept the logs from other accounts and send them to Amazon OpenSearch Service.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs//CrossAccountSubscriptions.html
https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/es-aws-integrations.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs//SubscriptionFilters.html#FirehoseExample
Check out this Amazon CloudWatch Cheat Sheet:
https://tutorialsdojo.com/amazon-cloudwatch/
Question 4
A startup prioritizes a serverless approach, using AWS Lambda for new workloads to analyze performance and identify bottlenecks. The startup aims to transition to self-managed services on top of Amazon EC2 later if it is more cost-effective. To do this, a solution for granular monitoring of every component of the call graph, including services and internal functions, for all requests, is required. In addition, the startup wants engineers and other stakeholders to be notified of performance irregularities as soon as such irregularities arise.
Which option will meet these requirements?
-
Create an internal extension and instrument Lambda workloads into X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant EventBridge rules and CloudWatch alarms.
-
Consolidate workflows spanning multiple Lambda functions into 1 function per workflow. Create an external extension and enable AWS X-Ray active tracing to instrument functions into segments. Assign an execution role allowing X-Ray actions. Enable X-Ray insights and set up appropriate Amazon EventBridge rules and Amazon CloudWatch alarms.
-
Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable Amazon CloudWatch Logs insights. Configure relevant Amazon EventBridge rules and CloudWatch alarms.
-
Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms.
Correct Answer: 4
AWS X-Ray is a service that analyzes the execution and performance behavior of distributed applications. Traditional debugging methods don’t work so well for microservice-based applications, in which there are multiple, independent components running on different services. X-Ray enables rapid diagnosis of errors, slowdowns, and timeouts by breaking down application latency.
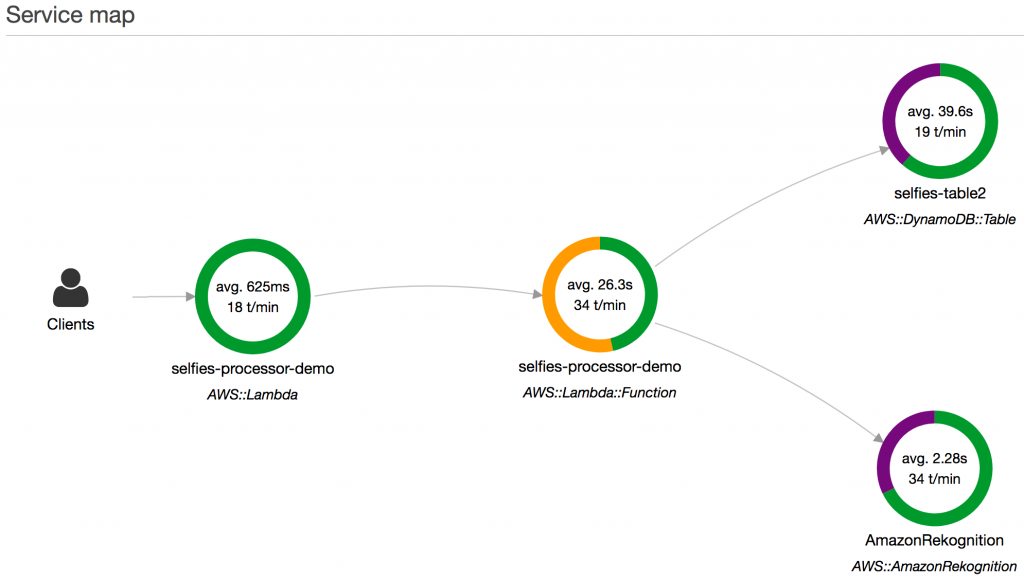
Insights is a feature of X-Ray that records performance outliers and tracks their impact until resolved. With insights, issues can be identified where they are occurring and what is causing them, and be triaged with the appropriate severity. Insights notifications are sent as the issue changes over time and can be integrated with your monitoring and alerting solution using Amazon EventBridge.
With an external AWS Lambda Extension using the telemetry API and X-Ray active tracing enabled, workflows are broken down into segments corresponding to the unit of work each Lambda function does. This can even be further broken down into subsegments by instrumenting calls to dependencies and related work, such as when a Lambda function requires data from DynamoDB and additional logic to process the response.
Lambda extensions come in two flavors: external and internal. The main difference is that an external extension runs in a separate process and can run longer to clean up after the Lambda function terminates, whereas an internal one runs in-process.
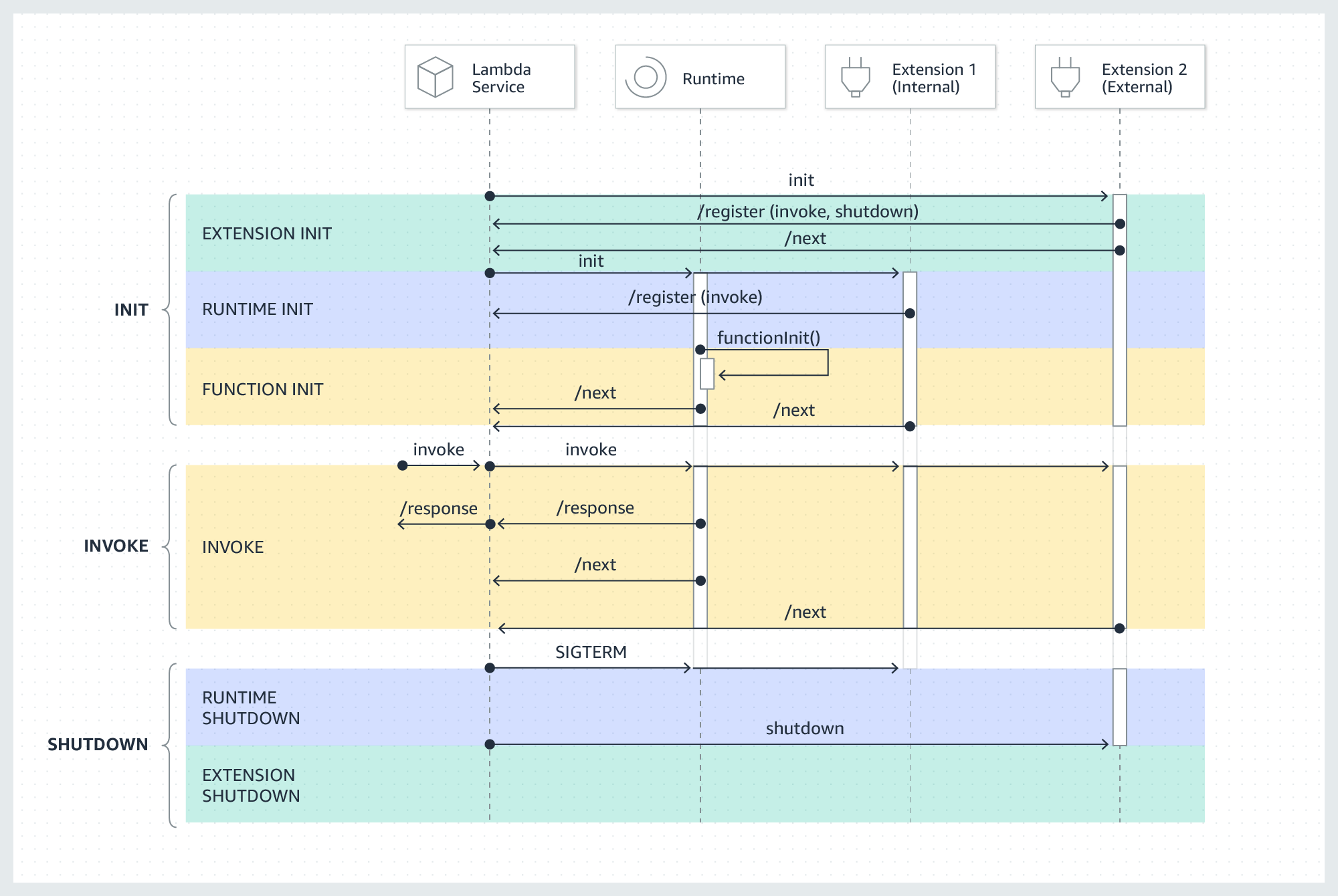
Hence, the correct answer is: Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms.
The option that says: Create an internal extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms is incorrect. An internal Lambda extension only works in-process. In the scenario, since X-Ray is the solution chosen for tracing and the X-Ray daemon runs as a separate process, an implementation based on an internal Lambda extension will not work.
The option that says: Consolidate workflows spanning multiple Lambda functions into 1 function per workflow. Create an external extension and enable AWS X-Ray active tracing to instrument functions into segments. Assign an execution role allowing X-Ray actions. Enable X-Ray insights and set up appropriate Amazon EventBridge rules and Amazon CloudWatch alarms is incorrect. Aside from adding unnecessary engineering work, this primarily prevents the reuse of functions in different workflows and increases the chance of undesirable duplication. Use X-Ray groups instead to group traces from individual workflows.
The option that says: Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable Amazon CloudWatch Logs insights. Configure relevant Amazon EventBridge rules and CloudWatch alarms is incorrect. Although Cloudwatch Logs insights and X-Ray insights both analyze and surface emergent issues from data, they do it on very different types of data — logs and traces, respectively. As logs do not have graph-like relationships of trace segments/spans, they may require more work or data to surface the same issues.
References:
https://docs.aws.amazon.com/lambda/latest/dg/services-xray.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-console-groups.html
https://docs.aws.amazon.com/lambda/latest/dg/lambda-extensions.html
Check out this AWS X-Ray Cheat Sheet:
Question 5
A DevOps engineer has been tasked with implementing configuration management for the company’s infrastructure in AWS. To adhere to the company’s strict security policies, the solution must include a near real-time dashboard that displays the compliance status of the systems and can detect any violations.
Which solution would be able to meet the above requirements?
- Use AWS Service Catalog to create the required resource configurations for its compliance posture. Monitor the compliance and violations of its cloud resources using a custom CloudWatch dashboard with an integrated Amazon SNS to send notifications.
- Use AWS Config to record all configuration changes and store the data reports to Amazon S3. Use Amazon QuickSight to analyze the dataset.
- Tag all the resources and use Trusted Advisor to monitor both the compliant and non-compliant resources. Use the AWS Management Console to monitor the status of the compliance posture.
-
Use Amazon Inspector to monitor the compliance posture of the systems and store the reports in Amazon CloudWatch Logs. Use a CloudWatch dashboard with a custom metric filter to monitor and view all of the specific compliance requirements.
Correct Answer: 2
AWS Config provides you a visual dashboard to help you quickly spot non-compliant resources and take appropriate action. IT Administrators, Security Experts, and Compliance Officers can see a shared view of your AWS resources compliance posture.
When you run your applications on AWS, you usually use AWS resources, which you must create and manage collectively. As the demand for your application keeps growing, so does your need to keep track of your AWS resources.

To exercise better governance over your resource configurations and to detect resource misconfigurations, you need fine-grained visibility into what resources exist and how these resources are configured at any time. You can use AWS Config to notify you whenever resources are created, modified, or deleted without having to monitor these changes by polling the calls made to each resource.
You can use AWS Config rules to evaluate the configuration settings of your AWS resources. When AWS Config detects that a resource violates the conditions in one of your rules, AWS Config flags the resource as non-compliant and sends a notification. AWS Config continuously evaluates your resources as they are created, changed, or deleted.
Hence, the correct answer is: Use AWS Config to record all configuration changes and store the data reports to Amazon S3. Use Amazon QuickSight to analyze the dataset.
The option that says: Use AWS Service Catalog to create the required resource configurations for its compliance posture. Monitor the compliance and violations of its cloud resources using a custom CloudWatch dashboard with an integrated Amazon SNS to send notifications is incorrect. Although AWS Service Catalog can be used for resource configuration, it is not typically capable of detecting violations of your AWS configuration rules.
The option that says: Tag all the resources and use Trusted Advisor to monitor both the compliant and non-compliant resources. Use the AWS Management Console to monitor the status of the compliance posture is incorrect because the Trusted Advisor service is not suitable for configuration management and automatic violation detection. You should use AWS Config instead.
The option that says: Use Amazon Inspector to monitor the compliance posture of the systems and store the reports in Amazon CloudWatch Logs. Use a CloudWatch dashboard with a custom metric filter to monitor and view all of the specific compliance requirements is incorrect because the Amazon Inspector service is primarily used to help you check for unintended network accessibility of your Amazon EC2 instances and for vulnerabilities on those EC2 instances.
References:
https://docs.aws.amazon.com/config/latest/developerguide/WhatIsConfig.html
https://docs.aws.amazon.com/quicksight/latest/user/QS-compliance.html
https://aws.amazon.com/config/features/
Check out this AWS Config Cheat Sheet:
https://tutorialsdojo.com/aws-config/
Question 6
A recent production incident has caused a data breach in one of the company’s flagship applications, which is hosted in an Auto Scaling group of Amazon EC2 instances. In order to prevent this from happening again, a DevOps engineer was tasked to implement a solution that would automatically terminate any instance in production that was manually logged into via SSH. All of the EC2 instances that are being used by the application already have an Amazon CloudWatch Logs agent installed.
Which of the following is the MOST automated solution that the DevOps engineer should implement?
-
Set up and integrate a CloudWatch Logs subscription with AWS Step Functions to add a special
FOR_DELETIONtag to the specific EC2 instance that had an SSH login event. Create an Amazon EventBridge rule to trigger a second AWS Lambda function everyday at 12 PM that will terminate all of the EC2 instances with this tag. - Set up a CloudWatch Alarm that will be triggered when an SSH login event occurs and configure it also to send a notification to an Amazon SNS topic once the alarm is triggered. Instruct the Support and Operations team to subscribe to the SNS topic and then manually terminate the detected EC2 instance as soon as possible.
- Set up a CloudWatch Alarm that will be triggered when there is an SSH login event and configure it to send a notification to an Amazon Simple Queue Service (Amazon SQS) queue. Launch a group of EC2 worker instances to consume the messages from the SQS queue and terminate the detected EC2 instances.
-
Set up a CloudWatch Logs subscription with an AWS Lambda function which is configured to add a
FOR_DELETIONtag to the EC2 instance that produced the SSH login event. Run another Lambda function every day using the Amazon EventBridge rule to terminate all EC2 instances with the custom tag for deletion.
Correct Answer: 4
You can use subscriptions to get access to a real-time feed of log events from CloudWatch Logs and have it delivered to other services such as an Amazon Kinesis stream, Amazon Data Firehose stream, or AWS Lambda for custom processing, analysis, or loading to other systems. To begin subscribing to log events, create the receiving source, such as a Kinesis stream, where the events will be delivered. A subscription filter defines the filter pattern to use for filtering which log events get delivered to your AWS resource, as well as information about where to send matching log events to.
CloudWatch Logs also produces CloudWatch metrics about the forwarding of log events to subscriptions. You can use a subscription filter with Kinesis, Lambda, or Data Firehose.
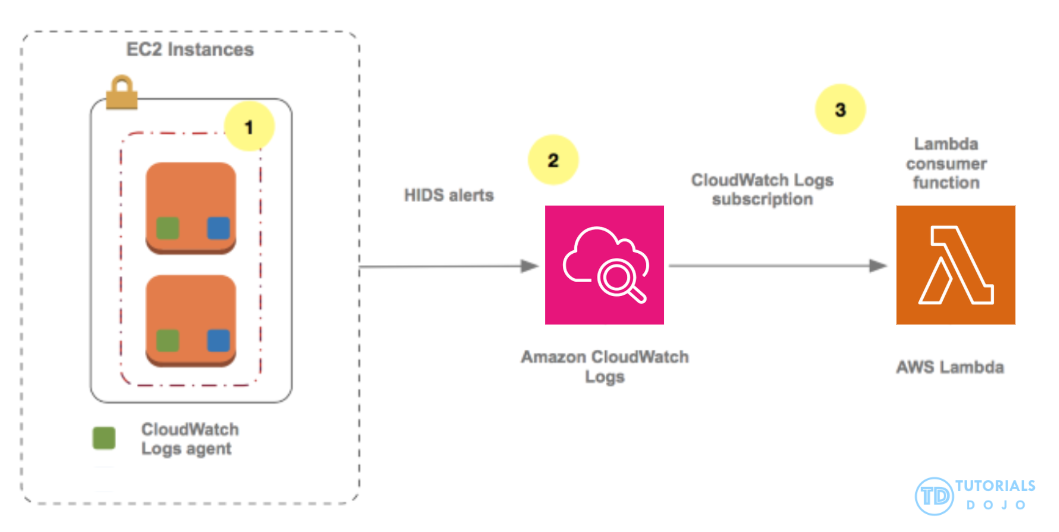
Hence, the correct answer is: Set up a CloudWatch Logs subscription with an AWS Lambda function which is configured to add a FOR_DELETION tag to the EC2 instance that produced the SSH login event. Run another Lambda function every day using the Amazon EventBridge rule to terminate all EC2 instances with the custom tag for deletion.
The option that says: Set up and integrate a CloudWatch Logs subscription with AWS Step Functions to add a special FOR_DELETION tag to the specific EC2 instance that had an SSH login event. Create an Amazon EventBridge rule to trigger a second AWS Lambda function everyday at 12 PM that will terminate all of the EC2 instances with this tag is incorrect because a CloudWatch Logs subscription cannot be directly integrated with an AWS Step Functions application.
The option that says: Set up a CloudWatch Alarm that will be triggered when an SSH login event occurs and configure it also to send a notification to an Amazon SNS topic once the alarm is triggered. Instruct the Support and Operations team to subscribe to the SNS topic and then manually terminate the detected EC2 instance as soon as possible is incorrect. Although you can configure your Amazon CloudWatch Alarms to send a notification to SNS, this solution simply involves a manual process. Remember that the scenario is asking for an automated system for this scenario.
The option that says: Set up a CloudWatch Alarm that will be triggered when there is an SSH login event and configure it to send a notification to an Amazon Simple Queue Service (Amazon SQS) queue. Launch a group of EC2 worker instances to consume the messages from the SQS queue and terminate the detected EC2 instances is incorrect because using SQS as well as worker instances is unnecessary since you can simply use Lambda functions for processing. In addition, Amazon CloudWatch Alarms can only send notifications to SNS and not SQS.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/SubscriptionFilters.html#LambdaFunctionExample
https://aws.amazon.com/blogs/security/how-to-monitor-and-visualize-failed-ssh-access-attempts-to-amazon-ec2-linux-instances/
https://docs.aws.amazon.com/AmazonCloudWatch/latest/events/Create-CloudWatch-Events-Scheduled-Rule.html
Check out this Amazon CloudWatch Cheat Sheet:
Question 7
A startup’s application is running in a single AWS region and utilizes Amazon DynamoDB as its backend.
The application is growing in popularity, and the startup just signed a deal to offer the application in other regions. The startup is looking for a solution that will satisfy the following requirements:
-
DynamoDB table must be available in all three regions to deliver low-latency data access.
-
When the table is updated in one Region, the change must seamlessly propagate to the other regions.
Which of the following solutions will meet the requirements with the LEAST operational overhead?
- Create DynamoDB global tables, then configure a primary table in one region and a read replica in the other regions.
- Provision a multi-Region, multi-active DynamoDB global table that includes the three Regions.
- Create DynamoDB tables in each of the three regions. Set up each table to use the same name.
- Provision three DynamoDB tables, one for each required region. Synchronize data changes among the tables using AWS SDK.
Correct Answer: 2

Amazon DynamoDB global tables are a fully managed, multi-Region, and multi-active database option that delivers fast and localized read and write performance for massively scaled global applications. Global tables provide automatic multi-active replication to AWS Regions worldwide. They enable you to deliver low-latency data access to your users no matter where they are located.

In this scenario, DynamoDB global tables provide a fully managed solution for deploying a multi-Region, multi-active database without having to build and maintain your own replication solution. You can specify the AWS Regions where you want the tables to be available, and DynamoDB will propagate ongoing data changes to all of them.
Hence, the correct answer is: Provision a multi-Region, multi-active DynamoDB global table that includes the three Regions.
The option that says: Provision three DynamoDB tables, one for each required region. Synchronize data changes among the tables using AWS SDK is incorrect because it would add unnecessary operational overhead to develop and manage a synchronization process across the tables.
The option that says: Create DynamoDB tables in each of the three regions. Set up each table to use the same name is incorrect because using a different table in each region would necessitate an additional replication solution.
The option that says: Create DynamoDB global tables, then configure a primary table in one region and a read replica in the other regions is incorrect because global tables do not have read replicas.
References:
https://aws.amazon.com/dynamodb/global-tables/
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GlobalTables.html
Check out this Amazon DynamoDB Cheat Sheet:
https://tutorialsdojo.com/amazon-dynamodb/
Question 8
Due to regional growth, an e-commerce company has decided to expand its global operations. The app’s REST API web services run in an Auto Scaling group of Amazon EC2 instances across multiple Availability Zones behind an Application Load Balancer. The application uses a single Amazon Aurora MySQL database instance in the AWS Region where it is based.
The company aims to consolidate and store product catalog data into a single data source across all regions. To comply with data privacy regulations, personal information, purchases, and financial data must be stored within each respective region.
Which of the following options can meet the above requirements and entail the LEAST amount of change to the application?
- Set up a new Amazon Redshift database to store the product catalog. Launch a new set of Amazon DynamoDB tables to store their customers’ personal information and financial data.
- Set up an Amazon DynamoDB global table to store the product catalog data of the e-commerce website. Use regional DynamoDB tables to store their customers’ personal information and financial data.
- Set up multiple read replicas in your Aurora cluster to store the product catalog data. Launch an additional local Aurora instance in each AWS Region to store customers’ personal information and financial data.
- Set up multiple read replicas in your Aurora cluster to store the product catalog data. Launch a new Amazon DynamoDB global table for storing their customers’ personal information and financial data.
Correct Answer: 3
Amazon Aurora is a fully managed relational database service that provides high performance and availability. It is compatible with MySQL and PostgreSQL and is designed to offer the speed and reliability of commercial databases while keeping the simplicity and cost-effectiveness of open-source databases. Aurora includes features such as automated backups, snapshots, and seamless scaling, making it a strong solution for modern applications. One of its key features is the ability to create read replicas, allowing for scaling of read operations across multiple Availability Zones and regions. This is especially beneficial for global applications that need low-latency access to data.

Aurora Global Database lets you create read replicas in multiple AWS Regions with replication latency typically under one second. This allows a single database to serve users worldwide with low latency and provides resilience in case of regional failures. However, Aurora Global Database replicates all data across regions, which may conflict with data privacy rules requiring certain data to stay within specific regions.
To meet these data sovereignty requirements, organizations can use Aurora Global Database for shared data like product catalogs, while deploying separate local Aurora clusters in each region to store sensitive personal and financial data.
Hence, the correct answer is: Set up multiple read replicas in your Aurora cluster to store the product catalog data. Launch an additional local Aurora instance in each AWS Region to store customers’ personal information and financial data.
The option that says: Set up a new Amazon Redshift database to store the product catalog. Launch a new set of Amazon DynamoDB tables to store their customers’ personal information and financial data is incorrect because this solution only entails a significant overhead of refactoring your application to use Redshift instead of Aurora. Moreover, Redshift is primarily used as a data warehouse solution and is not suitable for OLTP or e-commerce websites.
The option that says: Set up an Amazon DynamoDB global table to store the product catalog data of the e-commerce website. Use regional DynamoDB tables to store their customers’ personal information and financial data is incorrect. Although the use of Global and Regional DynamoDB is acceptable, this solution still entails a lot of changes to the application. There is no assurance that the application can work with a NoSQL database, and even so, you have to implement a series of code changes in order for this solution to work.
The option that says: Set up multiple read replicas in your Aurora cluster to store the product catalog data. Launch a new Amazon DynamoDB global table for storing their customers’ personal information and financial data is incorrect. Although the use of Read Replicas is appropriate, this solution simply requires you to do a lot of code changes since you will use a different database to store your regional data.
References:
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database.html#aurora-global-database.advantages
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Replication.CrossRegion.html
Check out this Amazon Aurora Cheat Sheet:
https://tutorialsdojo.com/amazon-aurora/
Question 9
A company plans to implement a monitoring system to track the cost-effectiveness of its Amazon EC2 resources across multiple AWS accounts. All existing resources are appropriately tagged to reflect the corresponding environment, department, and business unit for cost allocation purposes.
The company has instructed its DevOps engineer to automate infrastructure cost optimization across various shared environments and accounts, including detecting EC2 instances with low utilization.
Which is the MOST suitable solution that the DevOps engineer should implement in this scenario?
- Develop a custom shell script on an EC2 instance that runs periodically to report the instance utilization of all instances and store the result in an Amazon DynamoDB table. Use an Amazon QuickSight dashboard with DynamoDB as the source data to monitor and identify the underutilized EC2 instances. Integrate QuickSight and AWS Lambda to trigger an EC2 termination command for the underutilized instances.
- Set up an Amazon CloudWatch dashboard for EC2 instance tags based on the environment, department, and business unit to track the instance utilization. Create a trigger using an Amazon EventBridge rule and AWS Lambda to terminate the underutilized EC2 instances.
- Utilize AWS Trusted Advisor through a Business Support plan and integrate it with Amazon EventBridge to detect EC2 instances with low utilization. Set up an AWS Lambda function to filter the Trusted Advisor data using environment, department, and business unit tags. Create another Lambda trigger to terminate the underutilized instances.
- Set up an AWS Systems Manager to track the utilization of all of your EC2 instances and report underutilized instances to Amazon CloudWatch. Filter the data in CloudWatch based on tags for each environment, department, and business unit. Create triggers in CloudWatch that will invoke an AWS Lambda function that will terminate underutilized EC2 instances.
Correct Answer: 3
AWS Trusted Advisor draws upon best practices learned from serving hundreds of thousands of AWS customers. Trusted Advisor inspects your AWS environment, and then makes recommendations when opportunities exist to save money, improve system availability and performance, or help close security gaps. All AWS customers have access to five Trusted Advisor checks. Customers with a Business or Enterprise support plan can view all Trusted Advisor checks.
AWS Trusted Advisor is integrated with the Amazon EventBridge and Amazon CloudWatch services. You can use Amazon EventBridge to detect and react to changes in the status of Trusted Advisor checks and you can use Amazon CloudWatch to create alarms on Trusted Advisor metrics for check status changes, resource status changes, and service limit utilization.

You can use Amazon EventBridge to detect and react to changes in the status of Trusted Advisor checks. Then, based on the rules that you create, EventBridge invokes one or more target actions when a check status changes to the value you specify in a rule. Depending on the type of status change, you might want to send notifications, capture status information, take corrective action, initiate events, or take other actions.
Hence, the correct answer is: Utilize AWS Trusted Advisor through a Business Support plan and integrate it with Amazon EventBridge to detect EC2 instances with low utilization. Set up an AWS Lambda function to filter the Trusted Advisor data using environment, department, and business unit tags. Create another Lambda trigger to terminate the underutilized instances.
The option that says: Develop a custom shell script on an EC2 instance that runs periodically to report the instance utilization of all instances and store the result in an Amazon DynamoDB table. Use an Amazon QuickSight dashboard with DynamoDB as the source data to monitor and identify the underutilized EC2 instances. Integrate QuickSight and AWS Lambda to trigger an EC2 termination command for the underutilized instances is incorrect because it takes time to build a custom shell script to track the EC2 instance utilization. A more suitable way is to just use AWS Trusted Advisor instead.
The option that says: Set up an Amazon CloudWatch dashboard for EC2 instance tags based on the environment, department, and business unit to track the instance utilization. Create a trigger using an Amazon EventBridge rule and AWS Lambda to terminate the underutilized EC2 instances is incorrect because CloudWatch alone can’t provide the instance utilization of all of your EC2 servers. You have to use AWS Trusted Advisor to get this specific data.
The option that says: Set up an AWS Systems Manager to track the utilization of all of your EC2 instances and report underutilized instances to Amazon CloudWatch. Filter the data in CloudWatch based on tags for each environment, department, and business unit. Create triggers in CloudWatch that will invoke an AWS Lambda function that will terminate underutilized EC2 instances is incorrect because the Systems Manager service is primarily used to manage your EC2 instances. It doesn’t provide an easy way to provide the list of under or over-utilized EC2 instances like what Trusted Advisor can.
References:
https://docs.aws.amazon.com/awssupport/latest/user/cloudwatch-events-ta.html
https://docs.aws.amazon.com/awssupport/latest/user/trustedadvisor.html
https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
Check out this AWS Trusted Advisor Cheat Sheet:
https://tutorialsdojo.com/aws-trusted-advisor/
Question 10
A company has several legacy systems which use both on-premises servers as well as EC2 instances in AWS. The cluster nodes in AWS are configured to have a local IP address and a fixed hostname in order for the on-premises servers to communicate with them. There is a requirement to automate the configuration of the cluster which consists of 10 nodes to ensure high availability across three Availability Zones. There should also be a corresponding elastic network interface in a specific subnet for each Availability Zone. Each of the cluster node’s local IP address and hostname must be static and should not change even if the instance reboots or gets terminated.
Which of the following solutions below provides the LEAST amount of effort to automate this architecture?
- Launch an Elastic Beanstalk application with 10 EC2 instances, each has a corresponding ENI, hostname, and AZ as input parameters. Use the Elastic Beanstalk health agent daemon process to configure the hostname of the instance and attach a specific ENI based on the current environment.
- Set up a CloudFormation child stack template which launches an Auto Scaling group consisting of just one EC2 instance then provide a list of ENIs, hostnames, and the specific AZs as stack parameters. Set both the
MinSizeandMaxSizeparameters of the Auto Scaling group to 1. Add a user data script that will attach an ENI to the instance once launched. Use CloudFormation nested stacks to provision a total of 10 nodes needed for the cluster, and deploy the stack using a master template. - Use a DynamoDB table to store the list of ENIs and hostnames subnets which will be used by the cluster. Set up a single AWS CloudFormation template to manage an Auto Scaling group with a minimum and maximum size of 10. Maintain the assignment of each local IP address and hostname of the instances by using Systems Manager.
- Develop a custom AWS CLI script to launch the EC2 instances, each with an attached ENI, a unique name and placed in a specific AZ. Replace the missing EC2 instance by running the script via AWS CloudShell in the event that one of the instances in the cluster got rebooted or terminated.
Correct Answer: 2
A stack is a collection of AWS resources that you can manage as a single unit. In other words, you can create, update, or delete a collection of resources by creating, updating, or deleting stacks. All the resources in a stack are defined by the stack’s AWS CloudFormation template. A stack, for instance, can include all the resources required to run a web application, such as a web server, a database, and networking rules. If you no longer require that web application, you can simply delete the stack, and all of its related resources are deleted.
AWS CloudFormation ensures all stack resources are created or deleted as appropriate. Because AWS CloudFormation treats the stack resources as a single unit, they must all be created or deleted successfully for the stack to be created or deleted. If a resource cannot be created, AWS CloudFormation rolls the stack back and automatically deletes any resources that were created. If a resource cannot be deleted, any remaining resources are retained until the stack can be successfully deleted.

Nested stacks are stacks created as part of other stacks. You create a nested stack within another stack by using the AWS::CloudFormation::Stack resource.
As your infrastructure grows, common patterns can emerge in which you declare the same components in multiple templates. You can separate out these common components and create dedicated templates for them. Then use the resource in your template to reference other templates, creating nested stacks.
For example, assume that you have a load balancer configuration that you use for most of your stacks. Instead of copying and pasting the same configurations into your templates, you can create a dedicated template for the load balancer. Then, you just use the resource to reference that template from within other templates.
By setting up both the MinSize and MaxSize parameters of the Auto Scaling group to 1, you can ensure that your EC2 instance can recover again in the event of systems failure with exactly the same parameters defined in the CloudFormation template. This is one of the Auto Scaling strategies which provides high availability with the least possible cost. In this scenario, there is no mention about the scalability of the solution but only its availability.
Hence, the correct answer is to: Set up a CloudFormation child stack template which launches an Auto Scaling group consisting of just one EC2 instance then provide a list of ENIs, hostnames and the specific AZs as stack parameters. Set both the MinSize and MaxSize parameters of the Auto Scaling group to 1. Add a user data script that will attach an ENI to the instance once launched. Use CloudFormation nested stacks to provision a total of 10 nodes needed for the cluster, and deploy the stack using a master template.
The option that launches an Elastic Beanstalk application with 10 EC2 instances is incorrect because this involves a lot of manual configuration, which will make it hard for you to replicate the same stack to another AWS region. Moreover, the Elastic Beanstalk health agent is primarily used to monitor the health of your instances and can’t be used to configure the hostname of the instance nor attach a specific ENI.
The option that uses a DynamoDB table to store the list of ENIs and hostnames subnets is incorrect because you cannot maintain the assignment of the individual local IP address and hostname for each instance using Systems Manager.
The option that develops a custom AWS CLI script to launch the EC2 instances then run it via AWS CloudShell is incorrect because this is not an automated solution. AWS CloudShell may provide an easy and secure way of interacting with AWS resources via browser-based shell but executing a script on this is still a manual process. A better way to meet this requirement is to use CloudFormation.
References:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-cfn-nested-stacks.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/stacks.html
https://aws.amazon.com/cloudshell/
Check out this AWS CloudFormation Cheat Sheet:
https://tutorialsdojo.com/aws-cloudformation/
For more practice questions like these and to further prepare you for the actual AWS Certified DevOps Engineer Professional DOP-C02 exam, we recommend that you take our top-notch AWS Certified DevOps Engineer Professional Practice Exams, which have been regarded as the best in the market.
Also check out our AWS Certified DevOps Engineer Professional DOP-C02 Exam Study Guide here.
🔥 $0.99 NEW Study Guide eBook – Claude Certified Associate – Foundations CCAO-F

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





