Last updated on February 23, 2026
Here are 10 AWS Certified Security Specialty SCS-C03 practice exam questions to help you gauge your readiness for the actual exam.
Question 1
A leading hospital has a web application hosted in AWS that will store sensitive Personally Identifiable Information (PII) of its patients in an Amazon S3 bucket. Both the master keys and the unencrypted data should never be sent to AWS to comply with the strict compliance and regulatory requirements of the company.
Which S3 encryption technique should the Security Engineer implement?
- Implement an Amazon S3 client-side encryption with a KMS key.
- Implement an Amazon S3 client-side encryption with a client-side master key.
- Implement an Amazon S3 server-side encryption with a KMS managed key.
- Implement an Amazon S3 server-side encryption with customer provided key.
Correct Answer: 2
Client-side encryption is the act of encrypting data before sending it to Amazon S3. To enable client-side encryption, you have the following options:
– Use an AWS KMS key.
– Use a client-side master key.
When using an AWS KMS key to enable client-side data encryption, you provide an AWS KMS key ID (KeyId) to AWS. On the other hand, when you use client-side master key for client-side data encryption, your client-side master keys and your unencrypted data are never sent to AWS. It’s important that you safely manage your encryption keys because if you lose them, you can’t decrypt your data.
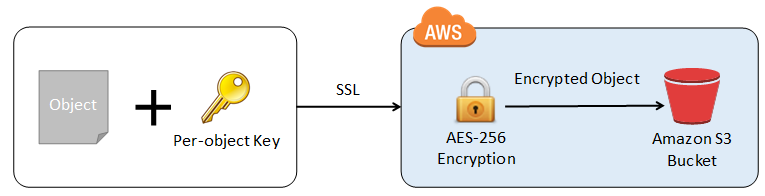
This is how client-side encryption using client-side master key works:
When uploading an object – You provide a client-side master key to the Amazon S3 encryption client. The client uses the master key only to encrypt the data encryption key that it generates randomly. The process works like this:
1. The Amazon S3 encryption client generates a one-time-use symmetric key (also known as a data encryption key or data key) locally. It uses the data key to encrypt the data of a single Amazon S3 object. The client generates a separate data key for each object.
2. The client encrypts the data encryption key using the master key that you provide. The client uploads the encrypted data key and its material description as part of the object metadata. The client uses the material description to determine which client-side master key to use for decryption.
3. The client uploads the encrypted data to Amazon S3 and saves the encrypted data key as object metadata (x-amz-meta-x-amz-key) in Amazon S3.
When downloading an object – The client downloads the encrypted object from Amazon S3. Using the material description from the object’s metadata, the client determines which master key to use to decrypt the data key. The client uses that master key to decrypt the data key and then uses the data key to decrypt the object.
Hence, the correct answer is: Implementing an Amazon S3 client-side encryption with a client-side master key.
Implementing an Amazon S3 client-side encryption with a KMS key is incorrect because in client-side encryption with a KMS key, you provide an AWS KMS key ID (KeyId) to AWS. The scenario clearly indicates that both the master keys and the unencrypted data should never be sent to AWS.
Implementing an Amazon S3 server-side encryption with a KMS key is incorrect because the scenario mentioned that the unencrypted data should never be sent to AWS, which means that you have to use client-side encryption in order to encrypt the data first before sending to AWS. In this way, you can ensure that there are no unencrypted data being uploaded to AWS. In addition, the master key used by Server-Side Encryption with AWS KMS–Managed Keys (SSE-KMS) is uploaded and managed by AWS, which directly violates the requirement of not uploading the master key.
Implementing an Amazon S3 server-side encryption with customer provided key is incorrect because, just as mentioned above, you have to use client-side encryption in this scenario instead of server-side encryption. For the S3 server-side encryption with customer-provided key (SSE-C), you actually provide the encryption key as part of your request to upload the object to S3. Using this key, Amazon S3 manages both the encryption (as it writes to disks) and decryption (when you access your objects).
References:
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingClientSideEncryption.html
Check out this AWS Key Management Service Cheat Sheet:
https://tutorialsdojo.com/aws-key-management-service-aws-kms/
Tutorials Dojo’s AWS Certified Security – Specialty Exam Study Guide:
https://tutorialsdojo.com/aws-certified-security-specialty-exam-study-path/
Question 2
An enterprise monitoring application collects data and generates audit logs of all operational activities of the company’s AWS Cloud infrastructure. The IT Security team requires that the application retain the logs for 5 years before the data can be deleted.
How can the Security Engineer meet the above requirement?
- Use Amazon S3 Glacier to store the audit logs and apply a Vault Lock policy.
- Use Amazon EBS Volumes to store the audit logs and take automated EBS snapshots every month using Amazon Data Lifecycle Manager.
- Use Amazon S3 to store the audit logs and enable Multi-Factor Authentication Delete (MFA Delete) for additional protection.
- Use Amazon EFS to store the audit logs and enable Network File System version 4 (NFSv4) file-locking mechanism.
Correct Answer: 1
An Amazon S3 Glacier (Glacier) vault can have one resource-based vault access policy and one Vault Lock policy attached to it. A Vault Lock policy is a vault access policy that you can lock. Using a Vault Lock policy can help you enforce regulatory and compliance requirements. Amazon S3 Glacier provides a set of API operations for you to manage the Vault Lock policies.

As an example of a Vault Lock policy, suppose that you are required to retain archives for one year before you can delete them. To implement this requirement, you can create a Vault Lock policy that denies users permissions from deleting an archive until the archive has existed for one year. You can test this policy before locking it down. After you lock the policy, it becomes immutable. For more information about the locking process, see Amazon S3 Glacier Vault Lock. If you want to manage other user permissions that can be changed, you can use the vault access policy
Amazon S3 Glacier supports the following archive operations: Upload, Download, and Delete. Archives are immutable and cannot be modified. Hence, the correct answer is: Use Amazon S3 Glacier to store the audit logs and apply a Vault Lock policy.
The option that says: Use Amazon EBS Volumes to store the audit logs and take automated EBS snapshots every month using Amazon Data Lifecycle Manager is incorrect because this is not a suitable and secure solution. Anyone who has access to the EBS Volume can simply delete and modify the audit logs. Snapshots can be deleted too.
The option that says: Use Amazon S3 to store the audit logs and enable Multi-Factor Authentication Delete (MFA Delete) for additional protection is incorrect because this would still not meet the requirement. If someone has access to the S3 bucket and also has the proper MFA privileges then the audit logs can be edited.
The option that says: Use Amazon EFS to store the audit logs and enable Network File System version 4 (NFSv4) file-locking mechanism is incorrect because the data integrity of the audit logs can still be compromised if it is stored in an EFS volume with Network File System version 4 (NFSv4) file-locking mechanism and hence, not suitable as storage for the files. Although it will provide some sort of security, the file lock can still be overridden and the audit logs might be edited by someone else.
References:
https://docs.aws.amazon.com/amazonglacier/latest/dev/vault-lock.html
https://docs.aws.amazon.com/amazonglacier/latest/dev/vault-lock-policy.html
https://aws.amazon.com/blogs/aws/glacier-vault-lock/
Check out this Amazon S3 Glacier Cheat Sheet:
https://tutorialsdojo.com/amazon-glacier/
Question 3
For data privacy, a healthcare company has been asked to comply with the Health Insurance Portability and Accountability Act (HIPAA) in handling static user documents. They instructed their Security Engineer to ensure that all of the data being backed up or stored on Amazon S3 are durably stored and encrypted.
Which combination of actions should the Engineer implement to meet the above requirement? (Select TWO.)
- Encrypt the data locally first using your own encryption keys before sending the data to Amazon S3. Send the data over HTTPS.
- Instead of using an S3 bucket, move and store the data on Amazon EBS volumes in two AZs with encryption enabled.
- Instead of using an S3 bucket, migrate and securely store the data in an encrypted RDS database.
- Enable Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) on the S3 bucket with AES-256 encryption.
- Enable Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) on the S3 bucket with AES-128 encryption.

Correct Answer: 1,4
Server-side encryption is about data encryption at rest—that is, Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers and decrypts it for you when you access it. As long as you authenticate your request and you have access permissions, there is no difference in the way you access encrypted or unencrypted objects. For example, if you share your objects using a pre-signed URL, that URL works the same way for both encrypted and unencrypted objects.

You have three mutually exclusive options depending on how you choose to manage the encryption keys:
- Use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
- Use Server-Side Encryption with AWS KMS Keys (SSE-KMS)
- Use Server-Side Encryption with Customer-Provided Keys (SSE-C)
Using client-side encryption and Amazon S3-Managed Keys (SSE-S3) can satisfy the requirement in the scenario. Client-side encryption is the act of encrypting data before sending it to Amazon S3 while SSE-S3 uses AES-256 encryption. Hence, the correct answers are:
– Encrypt the data locally first using your own encryption keys before sending the data to Amazon S3. Send the data over HTTPS.
– Enable Server-Side Encryption with Amazon S3-Managed Keys(SSE-S3) on the S3 bucket with AES-256 encryption.
The option that says: Instead of using an S3 bucket, move and store the data on Amazon EBS volumes in two AZs with encryption enabled is incorrect because Amazon S3 is more durable than EBS volumes. Objects stored in Amazon S3 can durably withstand the failures of two or more AZs.
The option that says: Instead of using an S3 bucket, migrate and securely store the data in an encrypted RDS database is incorrect because an Amazon RDS database is not a suitable data storage for storing static documents.
The option that says: Enable Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) on the S3 bucket with AES-128 encryption is incorrect as Amazon S3 doesn’t provide AES-128 encryption, only AES-256.
References:
http://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingClientSideEncryption.html
Check out this Amazon S3 Cheat Sheet:
Question 4
A multinational company is developing a sophisticated web application that requires integration with multiple third-party APIs. The company’s unique keys for each API are hardcoded inside an AWS CloudFormation template.
The security team requires that the keys be passed into the template without exposing their values in plaintext. Moreover, the keys must be encrypted at rest and in transit.
Which of the following provides the HIGHEST level of security while meeting these requirements?
- Use AWS Systems Manager Parameter Store to store the API keys. Then, reference them in the AWS CloudFormation templates using
!GetAtt AppKey.Value - Use AWS Systems Manager Parameter Store to store the API keys as
SecureStringparameters. Then, reference them in the AWS CloudFormation templates using{{resolve:ssm:AppKey}} - Utilize AWS Secrets Manager to store the API keys. Then, reference them in the AWS CloudFormation templates using
{{resolve:secretsmanager:AppKey:SecretString:password}} - Use an Amazon S3 bucket to store the API keys. Then, create a custom AWS Lambda function to read the keys from the S3 bucket. Reference the keys in the AWS CloudFormation templates using a custom resource that invokes the Lambda function.
Correct Answer: 3
AWS Secrets Manager is an AWS service that makes it easier for you to manage secrets. Secrets can be database credentials, passwords, third-party API keys, and even arbitrary text. You can store and control access to these secrets centrally by using the Secrets Manager console, the Secrets Manager command line interface (CLI), or the Secrets Manager API and SDKs. Secrets Manager enables you to replace hardcoded credentials in your code, with an API call to Secrets Manager to retrieve the secret programmatically. This helps ensure that the secret will not be compromised by someone examining your code, because the secret simply isn’t there. Also, you can configure Secrets Manager to automatically rotate the secret for you according to a schedule that you specify. This enables you to replace long-term secrets with short-term ones, which helps to significantly reduce the risk of compromise.

AWS CloudFormation Dynamic References is a feature that allows you to specify external values that are stored and managed in other services, such as the Systems Manager Parameter Store and AWS Secrets Manager, in your stack templates.
When you use a dynamic reference, CloudFormation retrieves the value of the specified reference when necessary during stack and change set operations. This provides a compact, powerful way for you to manage sensitive data like API keys, without exposing them in plaintext.
CloudFormation currently supports the following dynamic reference patterns:
ssm: for plaintext values stored in AWS Systems Manager Parameter Store.
ssm-secure: for secure strings stored in AWS Systems Manager Parameter Store.
secretsmanager: for entire secrets or secret values stored in AWS Secrets Manager.
Dynamic references adhere to the following pattern: {{resolve:<service>:<parameter-name>}}. Here, <service> specifies the service in which the value is stored and managed. The <parameter-name> is the name of the parameter stored in the specified service.
Hence, the correct answer is: Utilize AWS Secrets Manager to store the API keys. Then, reference them in the AWS CloudFormation templates using {{resolve:secretsmanager:AppKey:SecretString:password}}The option that says: Use AWS Systems Manager Parameter Store to store the API keys. Then, reference them in the AWS CloudFormation templates using !GetAtt AppKey.Value is incorrect because while the AWS Systems Manager Parameter Store can be used to store plaintext or encrypted strings, including API keys, the Fn::ImportValue or!ImportValue intrinsic functions are primarily used to import values from other stacks, not to retrieve values from the Parameter Store.
The option that says: Use AWS Systems Manager Parameter Store to store the API keys as SecureString parameters. Then, reference them in the AWS CloudFormation templates using {{resolve:ssm:AppKey}} is incorrect. While AWS Systems Manager Parameter Store is a valid option for storing configuration data and secrets, it still doesn’t provide the same level of features as AWS Secrets Manager, such as automatic secret rotation. The dynamic reference {{resolve:ssm:AppKey}} is used to retrieve parameter values from the AWS Systems Manager Parameter Store, but they do not provide the same level of security as AWS Secrets Manager.
The option that says: Use an Amazon S3 bucket to store the API keys. Then, create a custom AWS Lambda function to read the keys from the S3 bucket. Reference the keys in the AWS CloudFormation templates using a custom resource that invokes the Lambda function is incorrect. While S3 does support encryption at rest, it doesn’t automatically encrypt the data in transit within AWS services. S3 is designed for object storage and not for storing sensitive data like API keys, and it can be challenging to manage access controls for individual keys on S3. Moreover, the use of a custom Lambda function introduces extra overhead and potential security considerations. Therefore, this approach may not meet the requirements outlined in the question. It’s generally more secure and efficient to use services specifically designed for storing sensitive data, such as AWS Secrets Manager or AWS Systems Manager Parameter Store. These services integrate directly with AWS CloudFormation, simplifying the process and enhancing security.
References:
https://docs.aws.amazon.com/secretsmanager/latest/userguide/intro.html
https://docs.aws.amazon.com/secretsmanager/latest/userguide/create_secret.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html
Check out this AWS Secrets Manager Cheat Sheet:
https://tutorialsdojo.com/aws-secrets-manager/
Question 5
A company is looking to store its confidential financial files in AWS, which are accessed every week. A Security Engineer was instructed to set up the storage system, which uses envelope encryption and automates key rotation. It should also provide an audit trail that shows who used the encryption key and by whom for security purposes.
Which of the following should the Engineer implement to satisfy the requirement with the LEAST amount of cost? (Select TWO.)
- Store the confidential financial files in Amazon S3.
- Store the confidential financial files in the Amazon S3 Glacier Deep Archive.
- Enable Server-Side Encryption with Customer-Provided Keys (SSE-C).
- Enable Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3).
- Enable Server-Side Encryption with AWS KMS Keys (SSE-KMS).
Correct Answer: 1,5
Server-side encryption is the encryption of data at its destination by the application or service that receives it. AWS Key Management Service (AWS KMS) is a service that combines secure, highly available hardware and software to provide a key management system scaled for the cloud. Amazon S3 uses AWS KMS keys to encrypt your Amazon S3 objects.
A KMS key is a logical representation of a cryptographic key. The KMS keys include metadata, such as the key ID, creation date, description, and key state. The KMS keys also contain the key material used to encrypt and decrypt data. You can use a KMS key to encrypt and decrypt up to 4 KB (4096 bytes) of data. Typically, you use a KMS key to generate, encrypt, and decrypt the data keys that you use outside of AWS KMS to encrypt your data. This strategy is known as envelope encryption.
You have three mutually exclusive options depending on how you choose to manage the encryption keys:
Use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) – Each object is encrypted with a unique key. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. Amazon S3 server-side encryption uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data.
Use Server-Side Encryption with KMS key Stored in AWS KMS keys (SSE-KMS) – Similar to SSE-S3, but with some additional benefits and charges for using this service. There are separate permissions for the use of a KMS key that provides added protection against unauthorized access of your objects in Amazon S3. SSE-KMS also provides you with an audit trail that shows when your KMS keys were used and by whom. Additionally, you can create and manage customer-managed keys or use AWS managed KMS keys that are unique to you, your service, and your Region.
Use Server-Side Encryption with Customer-Provided Keys (SSE-C) – You manage the encryption keys and Amazon S3 manages the encryption, as it writes to disks, and decryption when you access your objects.
In the scenario, the company needs to store financial files in AWS which are accessed every week and the solution should use envelope encryption. This requirement can be fulfilled by using an Amazon S3 configured with Server-Side Encryption with AWS KMS Keys (SSE-KMS). The image below shows how to enable server-side encryption with SSE-KMS in Amazon S3 Console. This option will automatically encrypt new objects stored in an S3 bucket.

Hence, the correct answers are:
– Store the confidential financial files in Amazon S3
– Enable Server-Side Encryption with AWS KMS Keys (SSE-KMS).
The option that says: Store the confidential financial files in the S3 Amazon Glacier Deep Archive is incorrect. Although this provides the most cost-effective storage solution, it is not the appropriate service to use if the files being stored are frequently accessed every week.
The option that says: Enable Server-Side Encryption with Customer-Provided Keys (SSE-C) is incorrect because although SSE-C allows for tracking usage through AWS CloudTrail, it typically requires manual management of encryption keys and does not support automated key rotation. Therefore, it is less convenient than SSE-KMS.
The option that says: Enable Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) is incorrect because SSE-S3 provides server-side encryption, but it does not primarily offer advanced key management features, such as automated key rotation and detailed audit trails.
References:
https://docs.aws.amazon.com/AmazonS3/latest/dev/serv-side-encryption.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingKMSEncryption.html
https://docs.aws.amazon.com/kms/latest/developerguide/services-s3.html
Check out this Amazon S3 Cheat Sheet:
Question 6
A company is expanding its operations and setting up new teams in different regions around the world. The company is using AWS for its development environment. There’s a strict policy that only approved software can be used when launching EC2 instances.
In addition to enforcing the policy, the company also wants to ensure that the solution is cost-effective, does not significantly increase the launch time of the EC2 instances, and is easy to manage and maintain. The company also wants to ensure that the solution is scalable and can easily accommodate the addition of new software to the approved list or the removal of software from it.
Which of the following solutions would be the most effective considering all the requirements?
- Use a portfolio in the AWS Service Catalog that includes EC2 products with the right AMIs, each containing only the approved software. Ensure that developers have access only to this Service Catalog portfolio when they need to launch a product in the software development account.
- Set up an Amazon EventBridge rule that triggers whenever any EC2 RunInstances API event occurs in the software development account. Specify AWS Systems Manager Run Command as a target of the rule. Configure Run Command to run a script that installs all approved software onto the instances that the developers launch.
- Use AWS Systems Manager State Manager to create an association that specifies the approved software. The association will automatically install the software when an EC2 instance is launched.
- Use AWS Config to monitor the EC2 instances and send alerts when unapproved software is detected. The alerts can then be used to manually remove the software.
Correct Answer: 1
AWS Service Catalog allows organizations to create and manage catalogs of IT services that are approved for use on AWS. These IT services can include everything from virtual machine images, servers, software, and databases to complete multi-tier application architectures. AWS Service Catalog allows you to centrally manage deployed IT services and your applications, resources, and metadata.
With AWS Service Catalog, you define your own catalog of AWS services and AWS Marketplace software and make them available for your organization. Then, end users can quickly discover and deploy IT services using a self-service portal.

Hence, the correct answer is: Use a portfolio in the AWS Service Catalog that includes EC2 products with the right AMIs, each containing only the approved software. Ensure that developers have access only to this Service Catalog portfolio when they need to launch a product in the software development account. By using the AWS Service Catalog, you can organize your existing service offerings into portfolios, each of which can be assigned to specific AWS accounts or IAM users. This allows you to centrally manage commonly deployed IT services and helps you achieve consistent governance and meet your compliance requirements while enabling users to quickly deploy only the approved IT services they need.
The option that says: Set up an Amazon EventBridge rule that triggers whenever any EC2 RunInstances API event occurs in the software development account. Specify AWS Systems Manager Run Command as a target of the rule. Configure Run Command to run a script that installs all approved software onto the instances that the developers launch is incorrect. While Amazon EventBridge and AWS Systems Manager Run Command can be used to automate the installation of approved software onto the instances that the developers launch, this solution does not prevent developers from installing unapproved software. Moreover, it could potentially increase the launch time of the EC2 instances, and any changes to the approved software list would require updating the script used by Run Command, which could be time-consuming and error-prone.
The option that says: Use AWS Systems Manager State Manager to create an association that specifies the approved software. The association will automatically install the software when an EC2 instance is launched is incorrect. AWS Systems Manager State Manager can automate the process of keeping your EC2 instances in a desired state (for example, installing software), but it does not prevent developers from installing unapproved software. Moreover, any changes to the approved software list would require updating the State Manager association, which could be time-consuming and error-prone.
The option that says: Use AWS Config to monitor the EC2 instances and send alerts when unapproved software is detected. The alerts can then be used to manually remove the software is incorrect. AWS Config can monitor the configurations of your AWS resources, but it does not have the capability to detect or remove unapproved software on EC2 instances. Moreover, this solution involves manual intervention (removing the unapproved software when an alert is received), which is not ideal for scalability and ease of management.
References:
https://aws.amazon.com/servicecatalog/faqs/
https://docs.aws.amazon.com/servicecatalog/
Check out this AWS Service Catalog Cheat Sheet:
Question 7
A company migrated the DNS records of one of its domains to Amazon Route 53 and enabled logging for public DNS queries. After a week, log data was accumulating quickly, raising concerns about high storage costs over time. The company already uses AWS Cost Anomaly Detection to monitor unexpected spending patterns. To further reduce long-term storage expenses, logs older than one month must be automatically deleted.
Which action will resolve the problem most cost-effectively?
- Configure a retention policy in an Amazon CloudWatch Logs to delete logs older than 1 month.
- Change the destination of the DNS query logs to Amazon S3 Glacier Deep Archive.
- Configure Amazon CloudWatch Logs to export log data to an Amazon S3 bucket. Set an S3 lifecycle policy that deletes objects older than 1 month.
- Create a scheduled job using an AWS Lambda function to export logs from Amazon CloudWatch Logs to an Amazon S3 bucket. Set an S3 lifecycle policy that deletes objects older than 1 month.

Correct Answer: 1
A
Amazon Route 53 sends query logs directly to CloudWatch Logs; the logs are never accessible through Route 53. Instead, you use CloudWatch Logs to view logs in near real-time, search and filter data, and export logs to Amazon S3.

By default, CloudWatch Logs stores query logs indefinitely, which could potentially lead to uncontrolled increases in the cost of storing logs. By setting a retention policy in CloudWatch Logs, you can ensure that log data is only stored for a specific period of time and that it is automatically deleted when it reaches the end of that period. This can help you control storage costs and manage your log data more effectively.
Hence, the correct answer is: Configure a retention policy in an Amazon CloudWatch Logs to delete logs older than 1 month.
The option that says: Change the destination of the DNS query logs to Amazon S3 Glacier Deep Archive is incorrect. This is not possible since Route 53 sends query logs to CloudWatch Logs only.
The option that says: Configure Amazon CloudWatch Logs to export log data to an Amazon S3 bucket. Set an S3 lifecycle policy that deletes objects older than 1 month is incorrect. This is unnecessary since the deletion of logs older than 1 month can be done through the CloudWatch Logs retention policy. Exporting logs to S3 is often used to retain log data in Amazon S3 and reduce storage costs. Take note that you won’t be able to use CloudWatch Logs tools (like CloudWatch Insights) to analyze logs stored in S3.
The option that says: Create a scheduled job using an AWS Lambda function to export logs from Amazon CloudWatch Logs to an Amazon S3 bucket. Set an S3 lifecycle policy that deletes objects older than 1 month is incorrect. Although this could work, this option simply involves unnecessary steps that the CloudWatch Logs retention policy could simplify.
References:
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/query-logs.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/S3Export.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
Check out this Amazon CloudWatch cheat sheet:
https://tutorialsdojo.com/amazon-cloudwatch/
Question 8
A data security company is experimenting on various security features that they can implement on their Elastic Load Balancers such as Server Order Preference, Predefined Security Policy, Perfect Forward Secrecy, and many others. The company is planning to use the Perfect Forward Secrecy feature to provide additional safeguards to their architecture against the eavesdropping of encrypted data through the use of a unique random session key. This feature also prevents the decoding of captured data, even if the secret long-term key is compromised.
Which AWS services can offer SSL/TLS cipher suites for Perfect Forward Secrecy?
- Amazon EC2 and Amazon S3
- AWS CloudTrail and Amazon CloudWatch
- Amazon CloudFront and Elastic Load Balancers
- Amazon API Gateway and AWS Lambda
Correct Answer: 3
Elastic Load Balancing uses a Secure Socket Layer (SSL) negotiation configuration, known as a security policy, to negotiate SSL connections between a client and the load balancer. A security policy is a combination of SSL protocols, SSL ciphers, and the Server Order Preference option.
Perfect Forward Secrecy is a feature that provides additional safeguards against the eavesdropping of encrypted data through the use of a unique random session key. This prevents the decoding of captured data, even if the secret long-term key is compromised.

CloudFront and Elastic Load Balancing are the two AWS services that support Perfect Forward Secrecy.
Hence, the correct answer is: Amazon CloudFront and Elastic Load Balancers.
Amazon EC2 and S3, AWS CloudTrail and CloudWatch, and Amazon API Gateway and AWS Lambda are incorrect since these services do not use Perfect Forward Secrecy. SSL/TLS is commonly used when you have sensitive data traveling through the public network.
References:
https://aws.amazon.com/about-aws/whats-new/2014/02/19/elastic-load-balancing-perfect-forward-secrecy-and-more-new-security-features/
https://d1.awsstatic.com/whitepapers/Security/Secure_content_delivery_with_CloudFront_whitepaper.pdf
Check out these AWS Elastic Load Balancing (ELB) and Amazon CloudFront Cheat Sheets:
https://tutorialsdojo.com/aws-elastic-load-balancing-elb/
https://tutorialsdojo.com/amazon-cloudfront/
Question 9
A Cloud Security Engineer is validating network controls in an AWS VPC. From an authorized corporate laptop with a public IP address of 112.237.99.166, the engineer sends an ICMP ping to an Amazon EC2 instance with a private IP address of 172.31.17.140. The ping request is sent successfully, but the reply does not reach the laptop.
To investigate, the team reviews the VPC Flow Logs for the EC2 instance and observes the following entries:
2 123456789010 eni-1235b8ca 112.237.99.166 172.31.17.140 0 0 1 4 336 1432917027 1432917142
ACCEPT OK
2 123456789010 eni-1235b8ca 172.31.17.140 112.237.99.166 0 0 1 4 336 1432917094 1432917142
REJECT OK
What is the MOST likely root cause of this issue?
- The security group has an inbound rule that allows ICMP traffic, but does not have an outbound rule to explicitly allow outgoing ICMP traffic.
- The network ACL permits inbound ICMP traffic but blocks outbound ICMP traffic.
- The security group’s inbound rules do not allow ICMP traffic.
- The Network ACL does not permit inbound ICMP traffic.
Correct Answer: 2
If you’re using flow logs to diagnose overly restrictive or permissive security group rules or network ACL rules, then be aware of the statefulness of these resources. Security groups are stateful — this means that responses to allowed traffic are also allowed, even if the rules in your security group do not permit it. Conversely, network ACLs are stateless; therefore, responses to allowed traffic are subject to network ACL rules.

For example, you use the ping command from your home computer (IP address is 203.0.113.12) to your instance (the network interface’s private IP address is 172.31.16.139). Your security group’s inbound rules allow ICMP traffic and the outbound rules do not allow ICMP traffic; however, because security groups are stateful, the response ping from your instance is allowed. Your network ACL permits inbound ICMP traffic but does not permit outbound ICMP traffic. Because network ACLs are stateless, the response ping is dropped and does not reach your home computer.
In a flow log, this is displayed as two flow log records:
– An ACCEPT record for the originating ping that was allowed by both the network ACL and the security group, and therefore was allowed to reach your instance.
2 123456789010 eni-1235b8ca 203.0.113.12 172.31.16.139 0 0 1 4 336 1432917027 1432917142 ACCEPT OK
A REJECT record for the response ping that the network ACL denied.
2 123456789010 eni-1235b8ca 172.31.16.139 203.0.113.12 0 0 1 4 336 1432917094 1432917142 REJECT OK
A flow log record is a space-separated string that has the following format:
<version> <account-id> <interface-id> <srcaddr> <dstaddr> <srcport> <dstport> <protocol> <packets> <bytes> <start> <end> <action> <log-status>In this scenario, the ping command from your home computer to your EC2 instance failed, and there are two VPC Flow logs provided in the scenario. The logs basically mean that the first one is the record of the traffic flow that goes from your home computer to your EC2 instance, and the latter is the record of the traffic flow that goes back from the EC2 instance back to your home computer.
Apparently, the first one is an ACCEPT record and the second one is a REJECT record, which means that the incoming traffic was successfully accepted by your EC2 instance, but the response, or the outgoing traffic, was rejected by either your security group or network ACL.
Hence, the correct answer is: The network ACL permits inbound ICMP traffic but blocks outbound ICMP traffic.
The option that says: The security group has an inbound rule that allows ICMP traffic but does not have an outbound rule to explicitly allow outgoing ICMP traffic is incorrect because security groups are stateful. Hence, the response ping from your EC2 instance will still be allowed without explicitly allowing outgoing ICMP traffic.
The options that say: The security group’s inbound rules do not allow ICMP traffic and The network ACL does not permit inbound ICMP traffic are both incorrect because the first flow log clearly shows that the incoming traffic was successfully accepted by your EC2 instance which is why the issue lies on the outgoing traffic. The second flow log shows that the response, or the outgoing traffic, was rejected by either your security group or network ACL.
References:
https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs.html#flow-log-records
https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs-records-examples.html
Check out this Amazon VPC Cheat Sheet:
https://tutorialsdojo.com/amazon-vpc/
Security Group vs Network ACL:
https://tutorialsdojo.com/security-group-vs-nacl/
Question 10
A newly hired Security Analyst is assigned to manage the existing CloudFormation templates of the company. The Analyst opened the templates and analyzed the configured IAM policy for an S3 bucket as shown below:
<pre>
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“s3:Get*”,
“s3:List*”
],
“Resource”: “*”
},
{
“Effect”: “Allow”,
“Action”: “s3:PutObject”,
“Resource”: “arn:aws:s3:::team-palawan/*”
}
]
}
</pre>
What does the following IAM policy allow? (Select THREE.)
- Allows reading objects from all S3 buckets owned by the account.
- Allows writing objects into the
team-palawanS3 bucket. - Allows changing access rights for the
team-palawanS3 bucket. - Allows reading objects in the
team-palawanS3 bucket but not allowed to list the objects in the bucket. - Allows reading objects from the
team-palawanS3 bucket. - Allows reading and deleting objects from the
team-palawanS3 bucket.
Correct Answer: 1,2,5
The first statement in the policy allows all List (e.g., ListBucket, ListObject) and Get (e.g., GetObject, GetObjectVersion) operations on any S3 buckets and objects. The second statement explicitly allows the upload of any object to the team-palawan bucket.

Hence, the correct answers are:
-Allows reading objects from all S3 buckets owned by the account.
-Allows writing objects into the team-palawan S3 bucket.
-Allows reading objects from the team-palawan S3 bucket.
The option that says: Allows changing access rights for the team-palawan S3 bucket is incorrect because the policy does not have any statement that allows changing access rights in the bucket.
The option that says: Allows reading objects in the team-palawan S3 bucket but not allowed to list the objects in the bucket is incorrect. s3:List* refers to any permissions that start with the word “List,” which implies that the ListObject, which is required to list objects, is implicitly included. Hence, listing objects in any bucket is allowed.
The option that says: Allows reading and deleting objects from the team-palawan S3 bucket is incorrect. Although you can read objects from the bucket, you cannot delete any objects.
References:
https://docs.aws.amazon.com/AmazonS3/latest/API/RESTObjectOps.html
https://aws.amazon.com/blogs/security/how-to-use-bucket-policies-and-apply-defense-in-depth-to-help-secure-your-amazon-s3-data/
Check out this Amazon S3 Cheat Sheet:
https://tutorialsdojo.com/amazon-s3/
For more practice questions like these and to further prepare you for the actual AWS Certified Security Specialty SCS-C02 exam, we recommend that you take our top-notch AWS Certified Security Specialty Practice Exams, which have been regarded as the best in the market.
Also, check out our AWS Certified Security Specialty SCS-C02 exam study guide here.
🔥 43% OFF AWS & Azure Pro-Level Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





