Last updated on January 7, 2026
AWS Glue Cheat Sheet
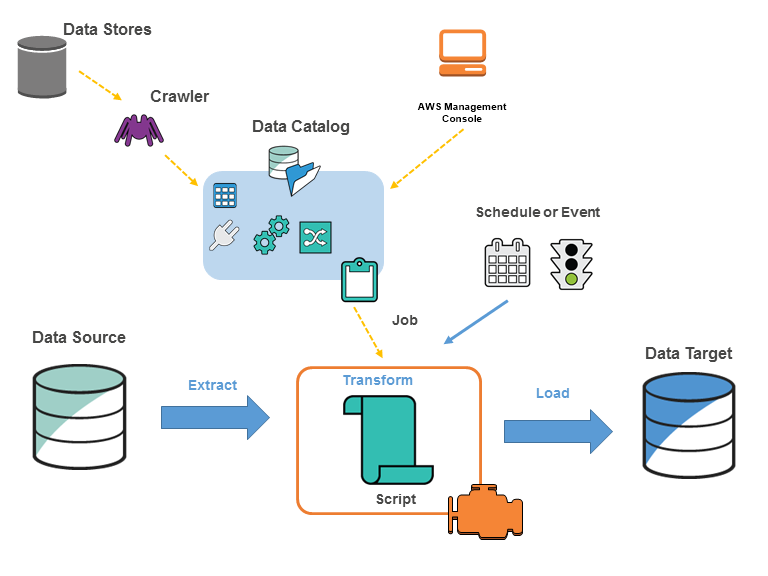
- A fully managed service to extract, transform, and load (ETL) your data for analytics.
- Discover and search across different AWS data sets without moving your data.
- AWS Glue consists of:
- Central metadata repository
- ETL engine
- Flexible scheduler
Use Cases
- Run queries against an Amazon S3 data lake
- AWS Glue supports zero-ETL integrations that allow analytics on operational data sources without building or maintaining custom ETL pipelines.
- You can use AWS Glue to make your data available for analytics without moving your data.
- Analyze the log data in your data warehouse
- Create ETL scripts to transform, flatten, and enrich the data from source to target.
- Create event-driven ETL pipelines
- As soon as new data becomes available in Amazon S3, you can run an ETL job by invoking AWS Glue ETL jobs using an AWS Lambda function.
- A unified view of your data across multiple data stores
- With AWS Glue Data Catalog, you can quickly search and discover all your datasets and maintain the relevant metadata in one central repository.
Features
Runtime and Engine Updates
- Supports AWS Glue versions 5.0 and 5.1, including Apache Spark 3.5.x, updated open table formats, and enhanced performance for modern data lake workloads.
- Provides native support for Apache Iceberg format version 3, including Iceberg materialized views and improved interoperability with Delta Lake and Apache Hudi tables.
- Enables Spark native fine-grained access control for DDL and DML operations across Hive, Iceberg, and Delta Lake tables.
Job Execution and Resources
- Supports additional worker types, including G.12X, G.16X, and memory-optimized R worker types, providing more compute and memory options for diverse workload requirements.
Data Quality
- AWS Glue Data Quality supports rule labeling, constants, and preprocessing queries, enabling better organization, reuse, and analysis of data quality rules across teams and domains.
- Integrates with AWS Lake Formation managed Iceberg, Delta, and Hudi tables for centralized data quality validation.

Integrations and Connectivity
- Supports zero-ETL integrations that enable fully managed data movement with minimal pipeline development effort.
- Provides reusable connections with a unified connection schema shared across AWS Glue, Amazon Athena, and Amazon SageMaker Unified Studio.
- Supports a growing set of SaaS native connectors for integrating data from third-party software-as-a-service platforms.
Data Catalog and Lakehouse Access
- Supports accessing the AWS Glue Data Catalog using the Apache Iceberg REST endpoint, enabling external analytics engines to interact with Iceberg tables through a REST-based catalog interface.
Developer Productivity and Troubleshooting
- Supports generative AI–powered tools for Apache Spark job upgrades and troubleshooting, helping developers analyze, migrate, and resolve issues in Spark applications more efficiently.
Concepts
- AWS Glue Data Catalog
- A persistent metadata store.
- The data that are used as sources and targets of your ETL jobs are stored in the data catalog.
- You can only use one data catalog per region.
- AWS Glue Data catalog can be used as the Hive metastore.
- AWS Glue supports Apache Iceberg tables, enabling transactional data lakes with schema evolution, time travel, and ACID operations.
- It can contain database and table resource links.
- Database
- A set of associated table definitions, organized into a logical group.
- A container for tables that define data from different data stores.
- If the database is deleted from the Data Catalog, all the tables in the database are also deleted.
- A link to a local or shared database is called a database resource link.
- Data store, data source, and data target
- To persistently store your data in a repository, you can use a data store.
- Data stores: Amazon S3, Amazon RDS, Amazon Redshift, Amazon DynamoDB, JDBC
- The data source is used as input to a process or transform.
- A location where the data store process or transform writes to is called a data target.
- To persistently store your data in a repository, you can use a data store.
- Table
- The metadata definition that represents your data.
- You can define tables using JSON, CSV, Parquet, Avro, and XML.
- You can use the table as the source or target in a job definition.
- A link to a local or shared table is called a table resource link.
- To add a table definition:
- Run a crawler.
- Create a table manually using the AWS Glue console.
- Use AWS Glue API CreateTable operation.
- Use AWS CloudFormation templates.
- Migrate the Apache Hive metastore
- A partitioned table describes an AWS Glue table definition of an Amazon S3 folder.
- Reduce the overall data transfers, processing, and query processing time with PartitionIndexes.
- Connection
- It contains the properties that you need to connect to your data.
- To store connection information for a data store, you can add a connection using:
- JDBC
- Amazon RDS
- Amazon Redshift
- Amazon DocumentDB
- MongoDB
- Kafka
- Network
- You can enable SSL connection for JDBC, Amazon RDS, Amazon Redshift, and MongoDB.
- Crawler
- You can use crawlers to populate the AWS Glue Data Catalog with tables.
- Crawlers can crawl file-based and table-based data stores.
- Data stores: S3, JDBC, DynamoDB, Amazon DocumentDB, and MongoDB
- It can crawl multiple data stores in a single run.
- How Crawlers work
- Determine the format, schema, and associated properties of the raw data by classifying the data – create a custom classifier to configure the results of the classification.
- Group the data into tables or partitions – you can group the data based on the crawler heuristics.
- Writes metadata to the AWS Glue Data Catalog – set up how the crawler adds, updates, and deletes tables and partitions.
- For incremental datasets with a stable table schema, you can use incremental crawls. It only crawls the folders that were added since the last crawler run.
- You can run a crawler on-demand or based on a schedule.
- Select the Logs link to view the results of the crawler. The link redirects you to CloudWatch Logs.
- Classifier
- It reads the data in the data store.
- You can use a set of built-in classifiers or create a custom classifier.
- By adding a classifier, you can determine the schema of your data.
- Custom classifier types: Grok, XML, JSON and CSV
- AWS Glue Studio
- Visually author, run, view, and edit your ETL jobs.
- Diagnose, debug, and check the status of your ETL jobs.
- Job
- To perform ETL works, you need to create a job.
- When creating a job, you need to provide data sources, targets, and other information. The result will be generated in a PySpark script and stored the job definition in the AWS Glue Data Catalog.
- Job types: Spark, Streaming ETL, and Python shell
- AWS Glue continues to enhance job execution with improved scaling behavior, optimized worker usage, and faster startup times for ETL workloads.
- Job properties:
- Job bookmarks maintain the state information and prevent the reprocessing of old data.
- Job metrics allows you to enable or disable the creation of CloudWatch metrics when the job runs.
- Security configuration helps you define the encryption options of the ETL job.
- Worker type is the predefined worker that is allocated when a job runs.
- Standard
- G.1X (memory-intensive jobs)
- G.2X (jobs with ML transforms)
- Max concurrency is the maximum number of concurrent runs that are allowed for the created job. If the threshold is reached, an error will be returned.
- Job timeout (minutes) is the execution time limit.
- Delay notification threshold (minutes) is set if a job runs longer than the specified time. AWS Glue will send a delay notification via Amazon CloudWatch.
- Number of retries allows you to specify the number of times AWS Glue would automatically restart the job if it fails.
- Job parameters and Non-overrideable Job parameters are a set of key-value pairs.
- Script
- A script allows you to extract the data from sources, transform it, and load the data into the targets.
- You can generate ETL scripts using Scala or PySpark.
- AWS Glue has a script editor that displays both the script and diagram to help you visualize the flow of your data.
- Development endpoint
- An environment that allows you to develop and test your ETL scripts.
- To create and test AWS Glue scripts, you can connect the development endpoint using:
- Apache Zeppelin notebook on your local machine
- Zeppelin notebook server in Amazon EC2 instance
- SageMaker notebook
- Terminal window
- PyCharm Python IDE
- With SageMaker notebooks, you can share development endpoints among single or multiple users.
- Single-tenancy Configuration
- Multi-tenancy Configuration
- Notebook server
- A web-based environment to run PySpark statements.
- You can use a notebook server for interactive development and testing of your ETL scripts on a development endpoint.
- SageMaker notebooks server
- Apache Zeppelin notebook server
- Trigger
- It allows you to manually or automatically start one or more crawlers or ETL jobs.
- You can define triggers based on schedule, job events, and on-demand.
- You can also use triggers to pass job parameters. If a trigger starts multiple jobs, the parameters are passed on each job.
- Workflows
- It helps you orchestrate ETL jobs, triggers, and crawlers.
- Workflows can be created using the AWS Management Console or AWS Glue API.
- You can visualize the components and the flow of work with a graph using the AWS Management Console.
- Jobs and crawlers can fire an event trigger within a workflow.
- By defining the default workflow run properties, you can share and manage state throughout a workflow run.
- With AWS Glue API, you can retrieve the static and dynamic view of a running workflow.
- The static view shows the design of the workflow. While the dynamic view includes the latest run information for the jobs and crawlers. Run information shows the success status and error details.
- You can stop, repair, and resume a workflow run.
- Workflow restrictions:
- You can only associate a trigger in one workflow.
- When setting up a trigger, you can only have one starting trigger (on-demand or schedule).
- If a crawler or job in a workflow is started by a trigger that is outside the workflow, any triggers within a workflow will not fire if it depends on the crawler or job completion.
- If a crawler or job in a workflow is started within the workflow, only the triggers within a workflow will fire upon the crawler or job completion.
- Transform
- To process your data, you can use AWS Glue built-in transforms. These transforms can be called from your ETL script.
- Enables you to manipulate your data into different formats.
- Clean your data using machine learning (ML) transforms.
- Tune transform:
- Recall vs. Precision
- Lower Cost vs. Accuracy
- With match enforcement, you can force the output to match the labels used in teaching the ML transform.
- Tune transform:
- Dynamic Frame
- A distributed table that supports nested data.
- A record for self-describing is designed for schema flexibility with semi-structured data.
- Each record consists of data and schema.
- You can use dynamic frames to provide a set of advanced transformations for data cleaning and ETL.
- AWS Glue Schema Registry
- Registry is a logical container of schemas. It allows you to organize your schemas, as well as manage access control for your applications. It also has an Amazon Resource Name (ARN) to allow you to organize and set different access permissions to schema operations within the registry.
- It enables you to centrally discover, control, and evolve data stream schemas.
- The AWS Glue Schema Registry is unavailable in the AWS Glue console for the following regions: Asia Pacific (Jakarta) and Middle East (UAE).
- It can manage and enforce schemas on data streaming applications using convenient integrations with Apache Kafka, Amazon Managed Streaming for Apache Kafka, Amazon Kinesis Data Streams, Amazon Managed Service for Apache Flink for Apache Flink, and AWS Lambda.
- AWS Glue Schema Registry is serverless and free to use.
- The Schema Registry allows disparate systems to share a schema for serialization and deserialization.
- Serialization is the process of converting data structures or objects into a format that can be easily transmitted or stored. It involves encoding the data into a sequence of bytes or a specific format.
- AWS Glue Schema Registry supports various serialization formats such as Avro, JSON, and others.
- Deserialization is the reverse process of serialization. It involves converting the serialized data back into its original data structure or object, thus making it readable and usable by the application or system.
- Serialization is the process of converting data structures or objects into a format that can be easily transmitted or stored. It involves encoding the data into a sequence of bytes or a specific format.
- Quotas of the Schema Registry:
- It only allows up to 10 registries per AWS account per AWS Region.
- It allows up to 1000 schema versions per AWS account per AWS Region.
- For Schema version metadata key-value pairs, it allows up to 10 key-value pairs per SchemaVersion per AWS Region.
- The quota for schema payloads is a size limit of 170KB.
Populating the AWS Glue Data Catalog

- Select any custom classifiers that will run with a crawler to infer the format and schema of the data. You must provide a code for your custom classifiers and run them in the order that you specify.
- To create a schema, a custom classifier must successfully recognize the structure of your data.
- The built-in classifiers will try to recognize the data’s schema if no custom classifier matches the data’s schema.
- For a crawler to access the data stores, you need to configure the connection properties. This will allow the crawler to connect to a data store, and the inferred schema will be created for your data.
- The crawler will write metadata to the AWS Glue Data Catalog. The metadata is stored in a table definition, and the table will be written to a database.
Authoring Jobs

- You need to select a data source for your job. Define the table that represents your data source in the AWS Glue Data Catalog. If the source requires a connection, you can reference the connection in your job. You can add multiple data sources by editing the script.
- Select the data target of your job or allow the job to create the target tables when it runs.
- By providing arguments for your job and generated script, you can customize the job-processing environment.
- AWS Glue can generate an initial script, but you can also edit the script if you need to add sources, targets, and transforms.
- Configure how your job is invoked. You can select on-demand, time-based schedule, or by an event.
- Based on the input, AWS Glue generates a Scala or PySpark script. You can edit the script based on your needs.
Glue DataBrew
- A visual data preparation tool for cleaning and normalizing data to prepare it for analytics and machine learning.
- You can choose from over 250 pre-built transformations to automate data preparation tasks. You can automate filtering anomalies, converting data to standard formats, and correcting invalid values, and other tasks. After your data is ready, you can immediately use it for analytics and machine learning projects.
- When running profile jobs in DataBrew to auto-generate 40+ data quality statistics like column-level cardinality, numerical correlations, unique values, standard deviation, and other statistics, you can configure the size of the dataset you want analyzed.
Glue Flex
- Allows you to optimize costs on non-urgent or non-time sensitive data integration workloads.
- AWS Glue Flex jobs run on spare compute capacity instead of dedicated hardware.
- The start and runtimes of jobs using Flex can vary because spare compute resources aren’t readily available and can be reclaimed during the run of a job.
- Regardless of the run option used, AWS Glue jobs have the same capabilities, including access to custom connectors, visual authoring interface, job scheduling, and Glue Auto Scaling.
- The cost of running flexible jobs is $0.29 per DPU-Hour, a 35% savings.
Glue Data Quality
- AWS Glue Data Quality is natively integrated with AWS Glue ETL jobs and the Data Catalog to evaluate data quality during processing and at rest.
- Allows you to measure and monitor the quality of your data for making good business decisions.
- It is built on top of the open-source DeeQu framework and provides a managed, serverless experience.
- AWS Glue Data Quality works with Data Quality Definition Language (DQDL), a domain-specific language that you use to define data quality rules.
-
Key Features
- Serverless: There is no installation, patching, or maintenance.
- Quick Start: AWS Glue Data Quality quickly analyzes your data and creates data quality rules for you.
- Detect Data Quality Issues: Use machine learning (ML) to detect anomalies and hard-to-detect data quality issues.
- Customizable Rules: With 25+ out-of-the-box DQ rules to start from, you can create rules that suit your specific needs.
- Data Quality Score: Once you evaluate the rules, you get a Data Quality score that provides an overview of the health of your data.
- Identify Bad Data: AWS Glue Data Quality helps you identify the exact records that caused your quality scores to go down.
- Pay as You Go: There are no annual licenses you need to use AWS Glue Data Quality.
- No Lock-In: AWS Glue Data Quality is built on open source DeeQu, allowing you to keep the rules you are authoring in an open language.
- Data Quality Checks: You can enforce data quality checks on Data Catalog and AWS Glue ETL pipelines allowing you to manage data quality at rest and in transit.
- ML-Based Data Quality Detection: Use machine learning (ML) to detect anomalies and hard-to-detect data quality issues.
- AWS Glue Data Quality evaluates objects that are stored in the AWS Glue Data Catalog. It offers non-coders an easy way to set up data quality rules.
Glue Sensitive Data Detection
-
The Detect PII transform identifies Personal Identifiable Information (PII) in your data source. You can choose the PII entity to identify, how you want the data to be scanned, and what to do with the PII entity that have been identified.
-
You can choose to detect PII in each row or detect the columns that contain PII data. When you choose Detect PII in each cell, you’re choosing to scan all rows in the data source.
-
If you choose to detect fields that contain PII, you can specify the percentage of rows to sample and the percentage of rows that contain the PII entity in order for the entire column to be identified as having the PII entity.
-
If you chose Detect PII in each cell, you can choose from one of three options: All available PII patterns, Select categories, or PII patterns will automatically include patterns in the categories that you select.
-
This feature uses pattern matching and machine learning to automatically recognize personally identifiable information (PII) and other sensitive data at the column or cell level as part of AWS Glue jobs.
-
You can create a custom identification pattern to identify case-specific entities.
-
It helps you take action, such as creating a new column that contains any sensitive data detected as part of a row or redacting the sensitive information before writing records into a data lake.
Glue for Ray
- Allows you to scale your Python workloads using Ray, an open-source unified compute framework.
- It is designed for customers who want to use familiar Python tools and AWS Glue jobs on data sets of all sizes, even those that can’t fit on a single instance.
- AWS Glue for Ray provides the same serverless experience and fast start time offered by AWS Glue.
-
Key Components
- Ray Core: The distributed computing framework.
- Ray Dataset: The distributed data framework based on Apache Arrow.
- AWS Glue Job and AWS Glue Interactive Session Primitives: These allow you to access the Ray engine.
-
How it Works
- You submit your Ray code to the AWS Glue jobs API and AWS Glue automatically provisions the required compute resources and runs the job.
- AWS Glue interactive session APIs allow interactive exploration of the data for the purpose of job development.
- Regardless of the option used, you are only billed for the duration of the compute used.
-
You can use AWS Glue for Ray with Glue Studio Notebooks, SageMaker Studio Notebook, or a local notebook or IDE of your choice.
Glue JDBC
-
AWS Glue natively supports connecting to certain databases through their JDBC connectors. The JDBC libraries are provided in AWS Glue Spark jobs. When connecting to these database types using AWS Glue libraries, you have access to a standard set of options.
-
JDBC Connection Types: The JDBC connectionType values include the following:
sqlserver: Designates a connection to a Microsoft SQL Server database.mysql: Designates a connection to a MySQL database.oracle: Designates a connection to an Oracle database.postgresql: Designates a connection to a PostgreSQL database.redshift: Designates a connection to an Amazon Redshift database.
-
JDBC Connection Option Reference: If you already have a JDBC AWS Glue connection defined, you can reuse the configuration properties defined in it, such as: url, user and password; so you don’t have to specify them in the code as connection options. This feature is available in AWS Glue 3.0 and later versions.
-
Setting up Amazon VPC for JDBC connections: To configure your Amazon VPC to connect to Amazon RDS data stores using JDBC, refer to Setting up Amazon VPC for JDBC connections to Amazon RDS data stores from AWS Glue.

AWS Glue Monitoring
- Record the actions taken by the user, role, and AWS service using AWS CloudTrail.
- You can use Amazon CloudWatch Events with AWS Glue to automate the actions when an event matches a rule.
- With Amazon CloudWatch Logs, you can monitor, store, and access log files from different sources.
- You can assign a tag to crawler, job, trigger, development endpoint, and machine learning transform.
- Monitor and debug ETL jobs and Spark applications using Apache Spark web UI.
- You could view the real-time logs on the Amazon CloudWatch dashboard if you enabled continuous logging.
AWS Glue Security
- Security configuration allows you to encrypt your data at rest using SSE-S3 and SSE-KMS.
- S3 encryption mode
- CloudWatch logs encryption mode
- Job bookmark encryption mode
- With AWS KMS keys, you can encrypt the job bookmarks and the logs generated by crawlers and ETL jobs.
- AWS Glue only supports symmetric customer master keys (CMKs).
- For data in transit, AWS provides SSL encryption.
- Managing access to resources using:
- Identity-Based Policies
- Resource-Based Policies
- You can grant cross-account access in AWS Glue using the Data Catalog resource policy and IAM role.
- Data Catalog Encryption:
- Metadata encryption
- Encrypt connection passwords
- You can create a policy for the data catalog to define fine-grained access control.
AWS Glue Pricing
- You are charged at an hourly rate based on the number of DPUs used to run your ETL job.
- You are charged at an hourly rate based on the number of DPUs used to run your crawler.
- Data Catalog storage and requests:
- You will be charged per month if you store more than a million objects.
- You will be charged per month if you exceed a million requests in a month.
Note: If you are studying for the AWS Certified Data Analytics Specialty exam, we highly recommend that you take our AWS Certified Data Analytics – Specialty Practice Exams and read our Data Analytics Specialty exam study guide.

Validate Your Knowledge
Question 1
A company is using Amazon S3 to store financial data in CSV format. An AWS Glue crawler is used to populate the AWS Glue Data Catalog and create the tables and schema. The Data Analyst launched an AWS Glue job that processes the data from the tables and writes it to Amazon Redshift tables. After running several jobs, the Data Analyst noticed that duplicate records exist in the Amazon Redshift table. The analyst needs to ensure that the Redshift table must not have any duplicates when jobs were rerun.
Which of the following is the best approach to satisfy this requirement?
- Set up a staging table in the AWS Glue job. Utilize the
DynamicFrameWriterclass in AWS Glue to replace the existing rows in the Redshift table before persisting the new data. - In the AWS Glue job, insert the previous data into a MySQL database. Use the upsert operation in MySQL and copy the data to Redshift.
- Remove the duplicate records using Apache Spark’s DataFrame
dropDuplicates()API before persisting the new data. - Select the latest data using the
ResolveChoicebuilt-in transform in AWS Glue to avoid duplicate records.
Correct Answer: 1
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. AWS Glue consists of a central data repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries. AWS Glue is serverless, so there’s no infrastructure to set up or manage. Use the AWS Glue console to discover your data, transform it, and make it available for search and querying.

Amazon Redshift doesn’t support a single merge statement (update or insert, also known as an upsert) to insert and update data from a single data source. However, you can effectively perform a merge operation. To do so, load your data into a staging table and then join the staging table with your target table for an UPDATE statement and an INSERT statement.
In this scenario, you can implement an upsert/merge in Redshift using an AWS Glue job. You can load your data into a staging table first and then join the staging table with your target table using an UPSERT operation. The term ‘UPSERT’ is basically a portmanteau of the ‘UPdate’ and ‘inSERT’ operations. The upsert feature inserts or updates data if the row that is being inserted already exists in the table. By using this operation, the Redshift tables will no longer have duplicate records.
Hence, the correct answer is: Set up a staging table in the AWS Glue job. Utilize the DynamicFrameWriter class in AWS Glue to replace the existing rows in the Redshift table before persisting the new data.
The option that says: In the AWS Glue job, insert the previous data into a MySQL database. Use the upsert operation in MySQL and copy the data to Redshift is incorrect because you can’t use the COPY command to copy data directly from a MySQL database into Amazon Redshift. A workaround for this is to move the MySQL data into Amazon S3 and use AWS Glue as a staging table to perform the upsert operation. Since this method requires more effort, it is not the best approach to solve the problem.
The option that says: Remove the duplicate records using Apache Spark’s DataFrame dropDuplicates() API before persisting the new data is incorrect. This won’t ensure the removal of duplicates in the Amazon Redshift table because you’re just effectively removing duplicates from the staging table. Take note that the current Redshift table contains duplicate records. Even if you manage to join the target table and the staging table, the duplicate records in the Redshift table will still persist.
The option that says: Select the latest data using the ResolveChoice built-in transform in AWS Glue to avoid duplicate records is incorrect because ResolveChoice is just a built-in transform function that just resolves a choice type within a DynamicFrame.
References:
https://docs.aws.amazon.com/redshift/latest/dg/c_best-practices-upsert.html
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame-writer.html
https://aws.amazon.com/premiumsupport/knowledge-center/sql-commands-redshift-glue-job/
Note: This question was extracted from our AWS Certified Data Analytics Specialty Practice Exams.
For more AWS practice exam questions with detailed explanations, visit the Tutorials Dojo Portal:

AWS Glue Cheat Sheet References:
https://aws.amazon.com/glue/faqs/
https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
🔥 43% OFF AWS & Azure Pro-Level Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





