Last updated on December 29, 2025
AWS OpsWorks Cheat Sheet
- A configuration management service that helps you configure and operate applications in a cloud enterprise by using Puppet or Chef.
- AWS OpsWorks Stacks and AWS OpsWorks for Chef Automate (1 and 2) let you use Chef cookbooks and solutions for configuration management, while OpsWorks for Puppet Enterprise lets you configure a Puppet Enterprise master server in AWS.
- With AWS OpsWorks, you can automate how nodes are configured, deployed, and managed, whether they are Amazon EC2 instances or on-premises devices:
- This service has been deprecated and is End of Life as of May 26, 2024.
OpsWorks for Puppet Enterprise
- Provides a fully-managed Puppet master, a suite of automation tools that enable you to inspect, deliver, operate, and future-proof your applications, and access to a user interface that lets you view information about your nodes and Puppet activities.
- Does not support all regions.
- Uses puppet-agent software.
- Features
- AWS manages the Puppet master server running on an EC2 instance. You retain control over the underlying resources running your Puppet master.
- You can choose the weekly maintenance window during which OpsWorks for Puppet Enterprise will automatically install updates.
- Monitors the health of your Puppet master during update windows and automatically rolls back changes if issues are detected.
- You can configure automatic backups for your Puppet master and store them in an S3 bucket in your account.
- You can register new nodes to your Puppet master by inserting a user-data script, provided in the OpsWorks for Puppet Enterprise StarterKit, into your Auto Scaling groups.
- Puppet uses SSL and a certification approval process when communicating to ensure that the Puppet master responds only to requests made by trusted users.
- Deleting a server also deletes its events, logs, and any modules that were stored on the server. Supporting resources are also deleted, along with all automated backups.
- Pricing
- You are charged based on the number of nodes (servers running the Puppet agent) connected to your Puppet master and the time those nodes are running on an hourly rate, and you also pay for the underlying EC2 instance running your Puppet master.

OpsWorks for Chef Automate
- Lets you create AWS-managed Chef servers that include Chef Automate premium features, and use the Chef DK and other Chef tooling to manage them.
- AWS OpsWorks for Chef Automate supports Chef Automate 2.
- Uses chef-client.
- Features
- You can use Chef to manage both Amazon EC2 instances and on-premises servers running Linux or Windows.
- You receive the full Chef Automate platform which includes premium features that you can use with Chef server, like Chef Workflow, Chef Visibility, and Chef Compliance.
- You provision a managed Chef server running on an EC2 instance in your account. You retain control over the underlying resources running your Chef server and you can use Knife to SSH into your Chef server instance at any time.
- You can set a weekly maintenance window during which OpsWorks for Chef Automate will automatically install updates.
- You can configure automatic backups for your Chef server and is stored in an S3 bucket.
- You can register new nodes to your Chef server by inserting user-data code snippets provided by OpsWorks for Chef Automate into your Auto Scaling groups.
- Chef uses SSL to ensure that the Chef server responds only to requests made by trusted users. The Chef server and Chef client use bidirectional validation of identity when communicating with each other.
- Deleting a server also deletes its events, logs, and any cookbooks that were stored on the server. Supporting resources are deleted also, along with all automated backups.
- Pricing
- You are charged based on the number of nodes connected to your Chef server and the time those nodes are running, and you also pay for the underlying EC2 instance running your Chef server.
OpsWorks Stacks
- Provides a simple and flexible way to create and manage stacks and applications.
- Stacks are group of AWS resources that constitute an full-stack application. By default, you can create up to 40 Stacks, and each stack can hold up to 40 layers, 40 instances, and 40 apps.
- You can create stacks that help you manage cloud resources in specialized groups called layers. A layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server. Layers depend on Chef recipes to handle tasks such as installing packages on instances, deploying apps, and running scripts.

- OpsWorks Stacks does NOT require or create Chef servers.
- Features
- You can deploy EC2 instances from template configurations, including EBS volume creation.
- You can configure the software on your instances on-demand or automatically based on lifecycle events, from bootstrapping the base OS image into a working server to modifying running services to reflect changes.
- OpsWorks Stacks can auto heal your stack. If an instance fails in your stack, OpsWorks Stacks can replace it with a new one.
- You can adapt the number of running instances to match your load, with time-based or load-based auto scaling.
- You can use OpsWorks Stacks to configure and manage both Linux and Windows EC2 instances.
- You can use AWS OpsWorks Stacks to deploy, manage, and scale your application on any Linux server such as EC2 instances or servers running in your own data center.
- Instance Types
- 24/7 instances are started manually and run until you stop them.
- Time-based instances are run by OpsWorks Stacks on a specified daily and weekly schedule. They allow your stack to automatically adjust the number of instances to accommodate predictable usage patterns.
- Load-based instances are automatically started and stopped by OpsWorks Stacks, based on specified load metrics, such as CPU utilization. They allow your stack to automatically adjust the number of instances to accommodate variations in incoming traffic.
- Load-based instances are available only for Linux-based stacks.
- Lifecycle Events
- You can run recipes manually, but OpsWorks Stacks also lets you automate the process by supporting a set of five lifecycle events:
- Setup occurs on a new instance after it successfully boots.
- Configure occurs on all of the stack’s instances when an instance enters or leaves the online state.
- Deploy occurs when you deploy an app.
- Undeploy occurs when you delete an app.
- Shutdown occurs when you stop an instance.
- You can run recipes manually, but OpsWorks Stacks also lets you automate the process by supporting a set of five lifecycle events:
- Monitoring
- OpsWorks Stacks sends all of your resource metrics to CloudWatch.
- Logs are available for each action performed on your instances.
- CloudTrail logs all API calls made to OpsWorks.
- Security
- Grant IAM users access to specific stacks, making management of multi-user environments easier.
- You can also set user-specific permissions for actions on each stack, allowing you to decide who can deploy new application versions or create new resources.
- Each EC2 instance has one or more associated security groups that govern the instance’s network traffic. A security group has one or more rules, each of which specifies a particular category of allowed traffic.
- Pricing
- You pay for AWS resources created using OpsWorks Stacks in the same manner as if you created them manually.
AWS OpsWorks-related Cheat Sheets:
Validate Your Knowledge
Question 1
A company manually runs its custom scripts when deploying a new version of its application that is hosted on a fleet of Amazon EC2 instances. This method is prone to human errors, such as accidentally running the wrong script or deploying the wrong artifact. The company wants to automate its deployment procedure.
If errors are encountered after the deployment, the company wants to be able to roll back to the older application version as fast as possible.
Which of the following options should the Solutions Architect implement to meet the requirements?
- Create two identical environments of the application on AWS Elastic Beanstalk. Use a blue/green deployment strategy by swapping the environment’s URL. Deploy the custom scripts using Elastic Beanstalk platform hooks.
- Create a new pipeline on AWS CodePipeline and add a stage that will deploy the application on the AWS EC2 instances. Choose a “rolling update with an additional batch” deployment strategy, to allow a quick rollback to the older version in case of errors.
- Utilize AWS CodeBuild and add a job with Chef recipes for the new application version. Use a “canary” deployment strategy to the new version on a new instance. Delete the canary instance if errors are found on the new version.
- Create an AWS System Manager automation runbook to manage the deployment process. Set up the runbook to first deploy the new application version to a staging environment. Include automated tests and, upon successful completion, use the runbook to deploy the application to the production environment
Correct Answer: 1
Blue/Green Deployment involves maintaining two separate, identical environments. The “Blue” environment is the current production version, while the “Green” is for the new version. . This Green environment is an exact replica of the Blue one but hosts the new version of your application. After deploying and thoroughly testing the new version in the Green environment, you simply switch the environment’s URL to redirect traffic from the Blue to the Green environment. This switch makes the new version live for users. If a rollback is needed due to any issues, it’s just a matter of switching the URL back to the original Blue environment and instantly reverting to the previous version of the application.

In Elastic Beanstalk you can perform a blue/green deployment by swapping the CNAMEs of the two environments to redirect traffic to the new version instantly. If there are any custom scripts or executable files that you want to run automatically as part of your deployment process, you may use platform hooks.
To provide platform hooks that run during an application deployment, place the files under the .platform/hooks directory in your source bundle, in one of the following subdirectories:
prebuild – Files here run after the Elastic Beanstalk platform engine downloads and extracts the application source bundle, and before it sets up and configures the application and web server.
predeploy – Files here run after the Elastic Beanstalk platform engine sets up and configures the application and web server, and before it deploys them to their final runtime location.
postdeploy – Files here run after the Elastic Beanstalk platform engine deploys the application and proxy server.
Therefore, the correct answer is: Create two identical environments of the application on AWS Elastic Beanstalk. Use a blue/green deployment strategy by swapping the environment’s URL. Deploy the custom scripts using Elastic Beanstalk platform hooks.
The option that says: Create an AWS System Manager automation runbook to manage the deployment process. Set up the runbook to first deploy the new application version to a staging environment. Include automated tests and, upon successful completion, use the runbook to deploy the application to the production environment is incorrect. While this is technically possible, it does not offer the fastest rollback mechanism in case of immediate issues post-deployment, as the rollback would involve a separate process. Moreover, unlike AWS Elastic Beanstalk, which has built-in features for version tracking, using AWS System Manager for deployment requires a more manual approach to version control. You would need to maintain a system for tracking different application versions, ensuring that you have the correct version deployed in the right environment (staging vs. production). This adds complexity to the deployment process.
The option that says: Create a new pipeline on AWS CodePipeline and add a stage that will deploy the application on the AWS EC2 instances. Choose a “rolling update with an additional batch” deployment strategy, to allow a quick rollback to the older version in case of errors is incorrect. Although the pipeline can deploy the new version on the EC2 instances, rollback for this strategy takes time. You will have to re-deploy the older version if you want to do a rollback.
The option that says: Utilize AWS CodeBuild and add a job with Chef recipes for the new application version. Use a “canary” deployment strategy to the new version on a new instance. Delete the canary instance if errors are found on the new version. is incorrect. Although you can detect errors on a canary deployment, AWS CodeBuild cannot deploy the new application version on the EC2 instances. You have to use AWS CodeDeploy if you want to go this route. It’s also easier to set up Chef deployments using AWS OpsWorks rather than in AWS CodeBuild.
References:
https://aws.amazon.com/opsworks/chefautomate/
https://docs.aws.amazon.com/opsworks/latest/userguide/best-deploy.html#best-deploy-environments-blue-green
https://docs.aws.amazon.com/opsworks/latest/userguide/workingapps-deploying.html
Note: This question was extracted from our AWS Certified Solutions Architect Professional Practice Exams.
Question 2

A startup prioritizes a serverless approach, using AWS Lambda for new workloads to analyze performance and identify bottlenecks. The startup aims to transition to self-managed services on top of Amazon EC2 later if it is more cost-effective. To do this, a solution for granular monitoring of every component of the call graph, including services and internal functions, for all requests, is required. In addition, the startup wants engineers and other stakeholders to be notified of performance irregularities as soon as such irregularities arise.
Which option will meet these requirements?
-
Create an internal extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms.
-
Consolidate workflows spanning multiple Lambda functions into 1 function per workflow. Create an external extension and enable AWS X-Ray active tracing to instrument functions into segments. Assign an execution role allowing X-Ray actions. Enable X-Ray insights and set up appropriate Amazon EventBridge rules and Amazon CloudWatch alarms.
-
Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable Amazon CloudWatch Logs insights. Configure relevant Amazon EventBridge rules and CloudWatch alarms.
-
Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms.
Correct Answer: 4
AWS X-Ray is a service that analyzes the execution and performance behavior of distributed applications. Traditional debugging methods don’t work so well for microservice-based applications, in which there are multiple, independent components running on different services. X-Ray enables rapid diagnosis of errors, slowdowns, and timeouts by breaking down application latency.
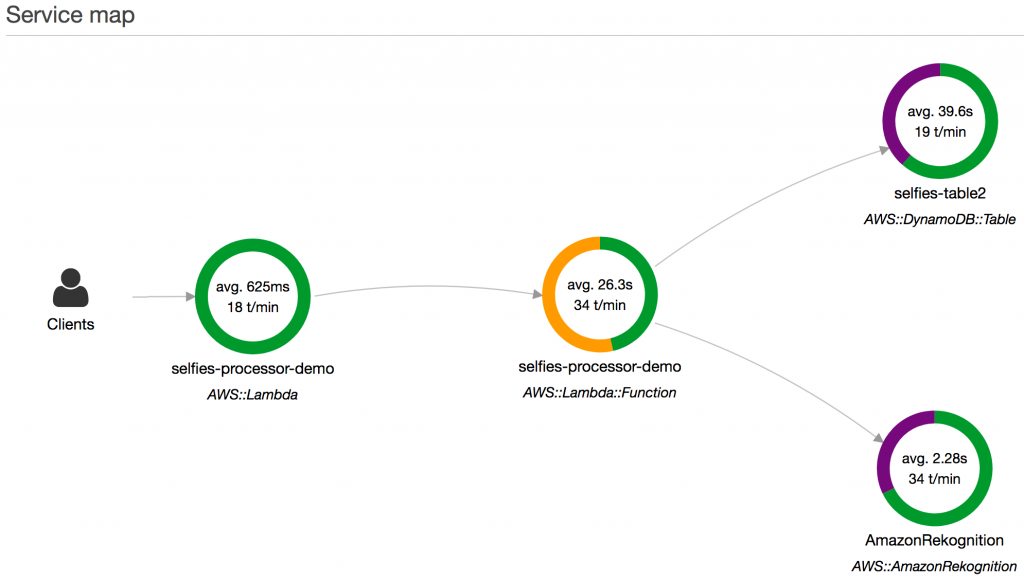
Insights is a feature of X-Ray that records performance outliers and tracks their impact until resolved. With insights, issues can be identified where they are occurring and what is causing them, and be triaged with the appropriate severity. Insights notifications are sent as the issue changes over time and can be integrated with your monitoring and alerting solution using Amazon EventBridge.
With an external AWS Lambda Extension using the telemetry API and X-Ray active tracing enabled, workflows are broken down into segments corresponding to the unit of work each Lambda function does. This can even be further broken down into subsegments by instrumenting calls to dependencies and related work, such as when a Lambda function requires data from DynamoDB and additional logic to process the response.
Lambda extensions come in two flavors: external and internal. The main difference is that an external extension runs in a separate process and can run longer to clean up after the Lambda function terminates, whereas an internal one runs in-process.
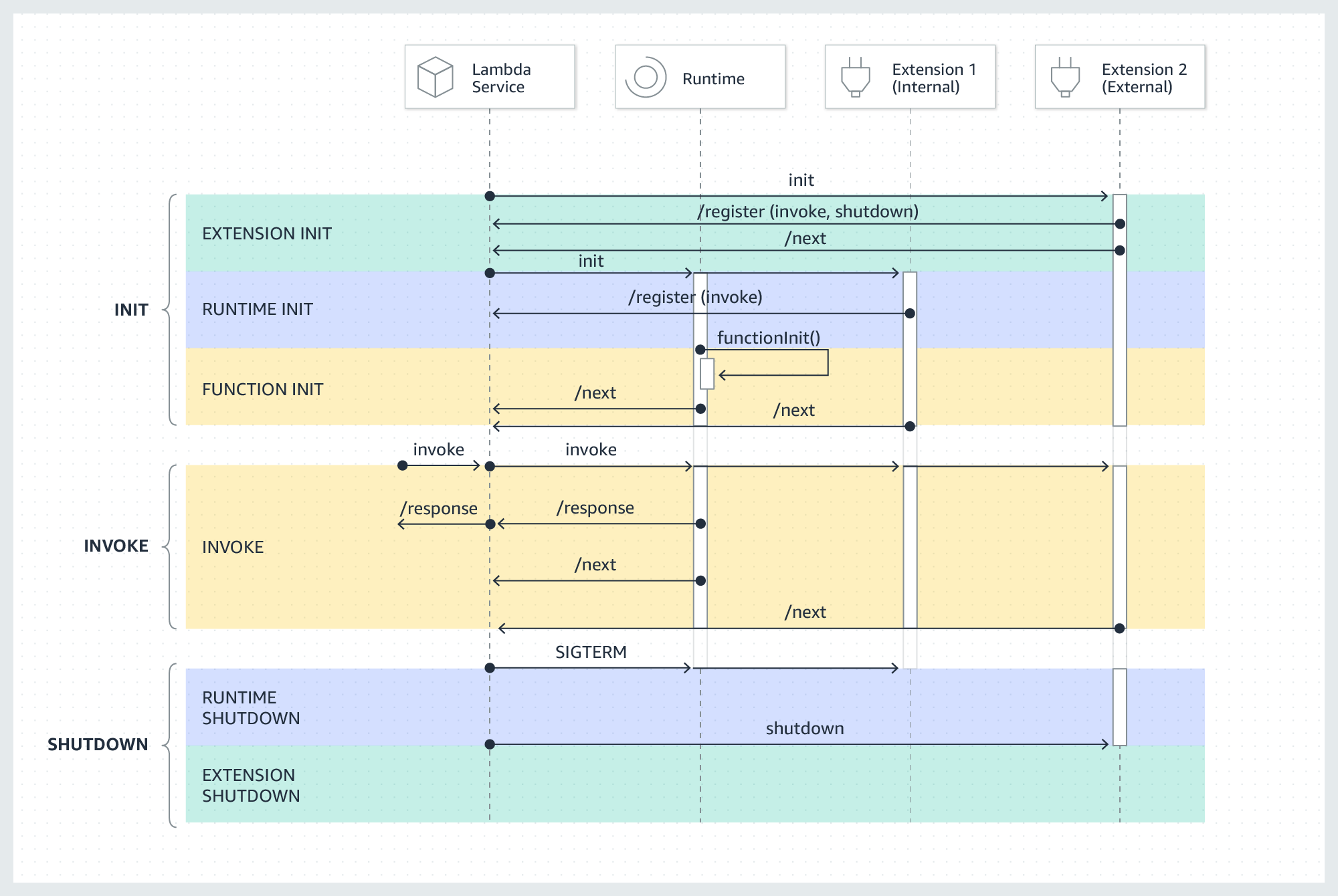
Hence, the correct answer is: Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms.
The option that says: Create an internal extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable X-Ray insights. Configure relevant Amazon EventBridge rules and Amazon CloudWatch alarms is incorrect. An internal Lambda extension only works in-process. In the scenario, since X-Ray is the solution chosen for tracing and the X-Ray daemon runs as a separate process, an implementation based on an internal Lambda extension will not work.
The option that says: Consolidate workflows spanning multiple Lambda functions into 1 function per workflow. Create an external extension and enable AWS X-Ray active tracing to instrument functions into segments. Assign an execution role allowing X-Ray actions. Enable X-Ray insights and set up appropriate Amazon EventBridge rules and Amazon CloudWatch alarms is incorrect. Aside from adding unnecessary engineering work, this primarily prevents the reuse of functions in different workflows and increases the chance of undesirable duplication. Use X-Ray groups instead to group traces from individual workflows.
The option that says: Create an external extension and instrument Lambda workloads into AWS X-Ray segments and subsegments. Enable X-Ray active tracing for Lambda. Assign an execution role allowing X-Ray actions. Set up X-Ray groups around workflows and enable Amazon CloudWatch Logs insights. Configure relevant Amazon EventBridge rules and CloudWatch alarms is incorrect. Although Cloudwatch Logs insights and X-Ray insights both analyze and surface emergent issues from data, they do it on very different types of data — logs and traces, respectively. As logs do not have graph-like relationships of trace segments/spans, they may require more work or data to surface the same issues.
References:
https://docs.aws.amazon.com/lambda/latest/dg/services-xray.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-console-groups.html
https://docs.aws.amazon.com/lambda/latest/dg/lambda-extensions.html
Check out this AWS X-Ray Cheat Sheet:
https://tutorialsdojo.com/aws-x-ray/
For more AWS practice exam questions with detailed explanations, visit the Tutorials Dojo Portal:

AWS OpsWorks Cheat Sheet References:
https://aws.amazon.com/opsworks/chefautomate/features
https://aws.amazon.com/opsworks/chefautomate/pricing
https://aws.amazon.com/opsworks/chefautomate/faqs
https://aws.amazon.com/opsworks/puppetenterprise/feature
https://aws.amazon.com/opsworks/puppetenterprise/pricing
https://aws.amazon.com/opsworks/puppetenterprise/faqs
https://aws.amazon.com/opsworks/stacks/features
https://aws.amazon.com/opsworks/stacks/pricing
https://aws.amazon.com/opsworks/stacks/faqs
🌸 25% OFF All Reviewers on our International Women’s Month Sale! Save 10% OFF All Subscriptions Plans & 5% OFF Store Credits/Gift Cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





