Last updated on June 2, 2023
What is Aurora Serverless?
Before we get into it, let us briefly define Aurora and serverless first. Aurora is a fully managed, closed source relational database that is compatible with MySQL and PostgreSQL. According to Amazon, it is five times faster than the standard MySQL and three times faster than PostgreSQL. It uses a distributed architecture that provides fault tolerance and high availability.
Serverless is a technique in the cloud that follows the ‘pay-per-use’ model. As opposed to its name, serverless does not mean not using ‘servers’. There is no magic in it. It still uses a physical server that is managed by a cloud provider and we only pay for the resources consumed. The servers on which we run the application are just not visible to us, but they are still managed by the provider. Serverless is not new. We’ve been using it for a long time! Just like how we use electricity for watching television, charging phones, running air conditioners, and so on. We only pay for the consumption that we’ve used and we don’t worry about the infrastructure behind it. It is no different than the services in the cloud.
Now, with Aurora Serverless, we get the same high-performance, high availability, and fault-tolerant nature of Aurora plus the convenience of using a serverless model.
Before Aurora Serverless:
- Determining and provisioning for the peak load is expensive and time-consuming.
- Provisioning less than the peak load will save cost but it will compromise the user’s experience
- It needs continuous monitoring to manually scale up or down as load changes
- There is a replication lag time
Why Use Aurora Serverless?
- It eliminates provisioning of a Db instance. Instead, it uses capacity based on the minimum and maximum Aurora Capacity Units (ACU) that you defined. An ACU is a combination of processing and memory capacity.
- It will automatically scale up and down based on the capacity allotted (ACU) as workload changes.
- It can be configured to automatically shut down when idle.
- It scales up quickly as load increases without affecting application performance.
- Encryption at rest is always enabled.
- Automatic multi-AZ failover.
- Backups are always enabled and do not impact performance.

How does It Work?
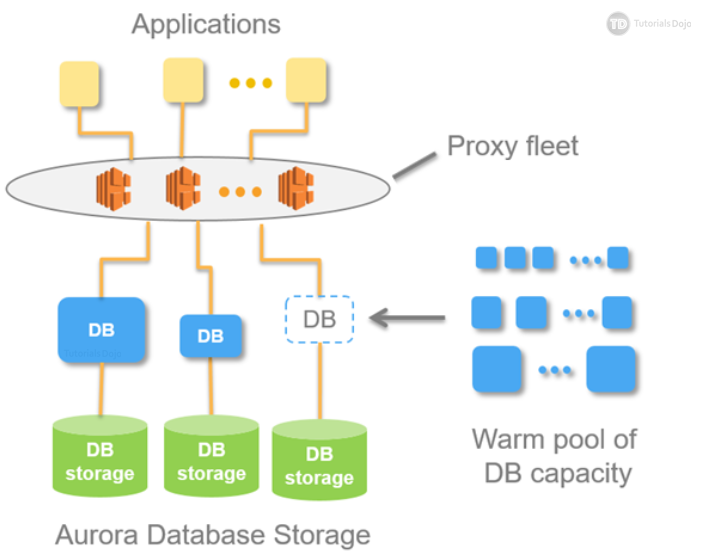
In addition to the distributed storage that Aurora (provisioned) uses, there are two key innovations that Amazon invented to make Aurora serverless work:
- Proxy Fleet – A highly distributed and highly multi-tenant proxies sitting in front of the database. This fixes the problem with Aurora (provisioned) where creating a read replica creates a replication lag. With the use of Proxy Fleet, seamless switching of active client connection to new resources is possible. And thanks to its distributed nature, no single point of failure is guaranteed.
- Warm Pool – A pool of “warm” resources that are always ready to serve. Warming an instance is no longer needed because Amazon already manages that for you.
Autoscaling For Aurora Serverless
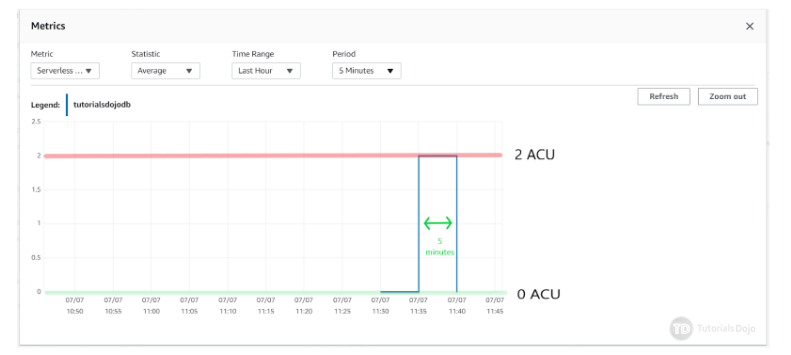
Aurora Serverless will autoscale based on the defined ACU. When configured, it can scale down to zero processing capacity for 5 minutes. Take note that this is the minimum period of inactivity before it scales down to zero, but it can be changed to a maximum period of 24 hours.
Here is how the metric would look like after 5 minutes of inactivity
Aurora Serverless automatically scales up whenever it detects:
- Constraints in CPU capacity to handle a load
- Constraints in connection
- Performance issues that can be solved by scaling up
After scaling up, it will take a cooldown period of 15 minutes for it to scale down. And after scaling down, the next cooldown period for it to scale down again is 310 seconds. This gradual scaling down ensures a quick response when a sudden spike in traffic occurs.
Remember that there is no cooldown period when scaling up. It will scale up to the defined maximum ACU as long as it needs to, to accommodate the load.
It is important to note that there is a scaling point, which is a period in time where Aurora can safely begin a scaling operation. It will continue to look for that “safe period” for it to scale up until such time where it can no longer find a scaling point. At this point, Aurora will time out.
Amazon recommends two actions to take if Aurora Serverless times out:
- Force the capacity change – This can be set at the creation of the database under “additional scaling configuration”

- Rollback the capacity change – Cancel the capacity change.

**CAVEAT: If you force the capacity to change after it fails to find a scaling point, active connections might be dropped.
When to Use Aurora Serverless:
- If you have an unpredictable workload. You no longer have to guess the capacity needed, as it will automatically adapt to your needs.
- If you have a workload that always changes. Suppose you have an application that peaks from 9 am to 10 am on a particular day. And on the next day, it only peaks for 30 minutes at night. Manually monitoring the database will require the expertise of a database admin which will cost money. Amazon does the monitoring and scaling for you.
- If you are deploying a new application and still do not have any idea of what instance to use.
- If you have an application that is in the development and testing stage. This is a good use case because Aurora Serverless can scale down to zero when no one is using it.

When not to use Aurora Serverless:
- When you have long queries that require a persistent connection to a database.
- When you have a highly predictable workload.
In the second part of this article, we will do some hands-on training and create an Aurora Serverless database.
Sources:
https://tutorialsdojo.com/amazon-aurora/
https://aws.amazon.com/rds/aurora/
https://aws.amazon.com/rds/aurora/serverless/
https://www.youtube.com/watch?v=9mTwxghXvlE&t=369s
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-serverless.how-it-works.html
🤖 $3.49 eBooks Start Here – Get Up to 30% OFF All AI & Machine Learning Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





