Last updated on November 25, 2025

AWS ParallelCluster Cheat Sheet
- AWS ParallelCluster is an AWS-supported open-source cluster management tool that makes it easy to deploy and manage High Performance Computing (HPC) clusters on AWS.
- AWS ParallelCluster provisions a master instance for build and control, a cluster of compute instances, a shared filesystem, and a batch scheduler. You can also extend and customize your use cases using custom pre-install and post-install bootstrap actions.
How It Works
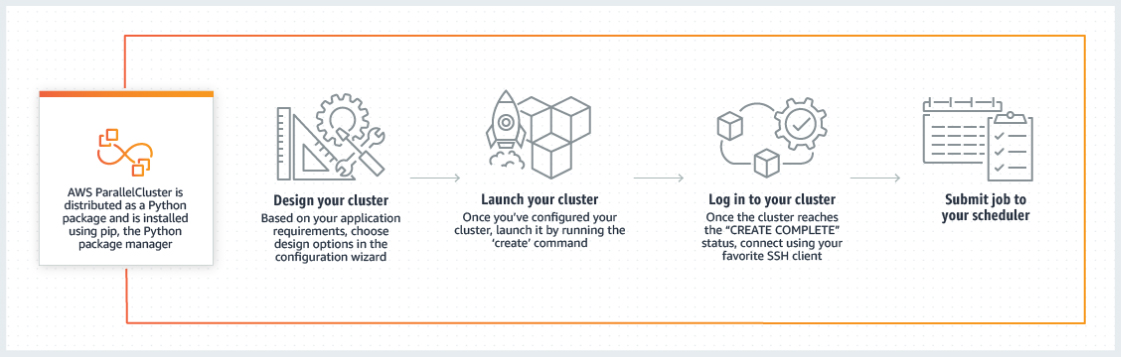
- You have four supported schedulers to use along with ParallelCluster:
- Slurm
- AWS Batch
- AWS ParallelCluster supports
- On-Demand,
- Reserved,
- and Spot Instances
AWS ParallelCluster Networking
-
- AWS ParallelCluster uses Amazon Virtual Private Cloud (VPC) for networking. The VPC must have DNS Resolution = yes, DNS Hostnames = yes and DHCP options with the correct domain-name for the Region.
- AWS ParallelCluster supports the following high-level configurations:
- One subnet for both master and compute instances.
- Two subnets, with the master in one public subnet, and compute instances in a private subnet. The subnets can be new or existing.
- AWS ParallelCluster can also be deployed to use an HTTP proxy for all AWS requests.
- Supports Elastic Fabric Adapter (EFA) on supported instance types to deliver lower, more consistent latency and higher throughput for inter-instance communication.
AWS ParallelCluster Storage
-
- By default, AWS ParallelCluster automatically configures an external volume of 15 GB of Elastic Block Storage (EBS) attached to the cluster’s master node and exported to the cluster’s compute nodes via Network File System (NFS).
- AWS ParallelCluster is also compatible with Amazon EBS, Amazon Elastic File System (EFS), Amazon FSx for ONTAP, Amazon FSx for OpenZFS, Amazon FSx for Lustre file systems, and Amazon File Cache.
- You can configure AWS ParallelCluster with Amazon S3 object storage as the source of job inputs or as a destination for job output.
- Cluster Configuration
- By default, it uses a YAML configuration file called
cluster-config.yamlto define the cluster resources, queues, and settings. - The configuration is organized into sections like
HeadNode,Scheduling(queues and compute resources), andSharedStorage. - Key Configuration Properties:
Region(Optional,String):- Specifies the AWS Region for the cluster (e.g.,
us-east-2). - Update policy: If this setting is changed, updates are not allowed.
- Specifies the AWS Region for the cluster (e.g.,
CustomS3Bucket(Optional,String):- Specifies the name of an Amazon S3 bucket in your account to store cluster resources (config files, logs).
- AWS ParallelCluster maintains one S3 bucket in each Region you create clusters in. By default, these are named
parallelcluster-hash-v1-DO-NOT-DELETE. - Update policy: If changed, the update is not allowed. If forced, the new value is ignored.
AdditionalResources(Optional,String):- Defines an additional AWS CloudFormation template to launch along with the cluster.
- Used for creating resources outside the cluster that are part of its lifecycle.
- The value must be a public HTTPS URL to a template that provides all parameters. There is no default value.
- By default, it uses a YAML configuration file called
- Multiple Queues & Mixed Instances
- Multiple Queues: You can configure up to 50 job queues within a single cluster. Each queue maps to a partition in the Slurm workload manager.
- Mixed Instance Types: Unlike older versions, you can now mix different instance types within the same cluster.
- You can define multiple Compute Resources (up to 50) within a single queue.
- Example: A single queue can contain both
c5.large(On-Demand) andc5.xlarge(Spot) instances.
- Prioritization: You can assign different priorities to queues to ensure critical jobs get resources first, or to spill over jobs from On-Demand to Spot queues when capacity is tight.
- Multi-AZ Support: Queues can span multiple Availability Zones (AZs), allowing you to access a larger pool of capacity (though this may impact latency for tightly coupled jobs).
- Cluster Processes
- When a cluster is running (specifically with
Slurm), these specific daemons manage the lifecycle and health of the fleet:clustermgtd– The cluster management daemon running on the head node. It manages the compute fleet lifecycle (launching/terminating instances), synchronizes the scheduler with EC2, performs health checks, and manages Slurm reservations for Capacity Blocks.clusterstatusmgtd– The cluster status management daemon running on the head node. It fetches the fleet status from DynamoDB every minute and processes cluster STOP and START requests.computemgtd– The compute management daemon running on each compute node. It monitors the head node’s health every 5 minutes; if the head node becomes unreachable, it automatically shuts down the compute node.
- When a cluster is running (specifically with
AWS ParallelCluster Pricing
-
- AWS ParallelCluster is available at no additional charge. You pay only for the AWS resources needed to run your applications.
Limitations
-
- AWS ParallelCluster does not support building Windows clusters; the head node and compute fleet must be Linux-based.
- While you can span queues across Availability Zones, Elastic Fabric Adapter (EFA) and Placement Groups are not supported in queues that span multiple AZs (due to latency requirements).
AWS ParallelCluster Cheat Sheet References:
https://aws.amazon.com/hpc/parallelcluster/
https://docs.aws.amazon.com/parallelcluster/latest/ug/what-is-aws-parallelcluster.html
https://aws.amazon.com/hpc/faqs/
https://aws.amazon.com/blogs/opensource/aws-parallelcluster/
🌸 25% OFF All Reviewers on our International Women’s Month Sale! Save 10% OFF All Subscriptions Plans & 5% OFF Store Credits/Gift Cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin


Written by: Jon Bonso
Jon Bonso is the co-founder of Tutorials Dojo, an EdTech startup and an AWS Digital Training Partner that provides high-quality educational materials in the cloud computing space. He graduated from Mapúa Institute of Technology in 2007 with a bachelor's degree in Information Technology. Jon holds 10 AWS Certifications and is also an active AWS Community Builder since 2020.



