Last updated on December 15, 2023
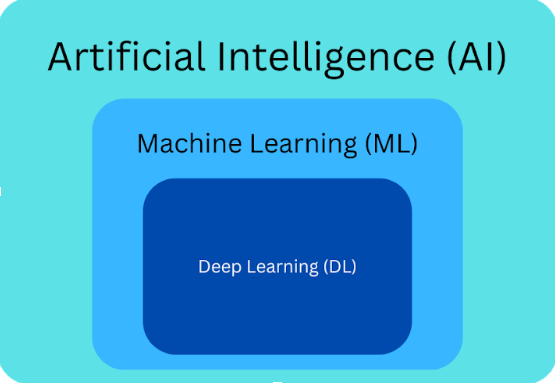
The recent biggest trends in technology revolve around this buzzword that exploded in popularity: Generative AI. After the initial public release of ChatGPT from OpenAI around November 2022, plenty of other chatbots powered by large language models (LLMs), like Google’s PaLM powering Google Bard and Meta’s LLaMa model, took the world by storm. These LLMs have empowered millions of users and developers, affecting various areas of work and thus reshaping the industry. In this article, we will discuss the basic principles and concepts around these LLMs, explain the role of Foundation Models behind them, and explore AI’s current integrations and future capabilities. Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are frequently occurring terminologies (often left as buzzwords) ever since the boom in late 2022. Although they are closely interrelated, they are distinct concepts. Artificial Intelligence is a broad field that aims to create “intelligent” machines mimicking the capabilities of humans to conduct tasks, hence “artificial.” An example would be AI voice assistants in mobile devices, performing as human assistants without the actual human. Meanwhile, Machine Learning is a subset of Artificial Intelligence that uses concepts from mathematics, statistics, computer science, and other fields, dedicated to developing algorithms that allow computers to make decisions without explicit instruction, where the “machine” is “learning.” An example would be post-processing found in the cameras of modern phones, making adjustments to the final image based on the information in the shot. Lastly, Deep Learning is a specialized subset of Machine Learning (and therefore also a subset of Artificial Intelligence) that utilizes neural networks, which are powerful computational models that mimic how neurons in the human brain operate. These operate with many layers, hence the term “deep.” An example would be facial recognition in phones, which processes a large dataset of facial features to confirm a person’s identity. One last buzzword that I would like to highlight is the term model. In this context, a model is a massive bundle of mathematical equations with coefficients (which are called parameters or weights). In essence, “training” a model is changing these coefficients repeatedly and testing which sets of coefficients provide results closest to the actual values. Upon inputting values into these trained models (bundles of equations), there exists a corresponding output.
Note that the terms input values and output have many variations and forms depending on the model. Examples would be: Having a clear understanding and personal ideas of these buzzwords will significantly aid in understanding the concepts related to them. Generative AI, as the name suggests, is a type of AI that can generate outputs that are not part of the original dataset. Generate AI models learn this by analyzing vast amounts of existing data and figuring out the patterns within them, which they then use to generate new outputs that are extensions of these patterns. Generative AI is unlike traditional AI in the sense that traditional AI is intended to interpret, categorize, predict, and not generate. These usually operate within the trained dataset and the explicit programming it has. There are many forms of outputs of these generative AI models, like images, audio, or text. For example, Large Language Models (LLMs) are responsible for text generation. LLMs can learn to generate depending on the text they have been trained on using concepts from natural language processing (NLP). The gist of this process is that words can be converted into the world of numbers, which is what these models (which we have mentioned to be mathematical equations) can understand. These “numerical words” are often called tokens, and the conversion process is called tokenization. After data preprocessing (including tokenization), the data is then ready for the core training part. The model is tasked to predict the next words or phrases (tokens/series of tokens). The training dataset may contain the following sentences: The model will be asked to predict the last word from the following sentence: It can try the plethora of words it knows, but there will be correct and incorrect words. For instance, it may try the following: The model then scores the “mug” token positively since it came from the dataset, which the model assumes to be correct. In contrast, the opposite would happen if it tries the following: The model can score the token “fork” negatively since it does not exist in the dataset. Now, the model knows that “mug” suits the sentence above and “fork” does not. These words highlight the importance of having correct training data, or else the model may consider “fork” to be correct and “mug” to be incorrect. This training process is done many times depending on the complexity and could easily reach an overwhelmingly large number of iterations. Over time, the model learns which words go with which, developing a complex understanding of language, including grammar and style. Once the training process is done, it proceeds to testing and fine-tuning, where it is tested on data it has not been shown before, and ensures that it still performs as well. If not, then the metrics are analyzed, the model’s root cause of possible confusion is analyzed, and the model is trained again with corresponding adjustments. After a heavily repeated process, the LLM is ready to generate text based on prompts. Please note that this process involves extremely complex mathematics, significant computing resources, and other techniques to capture the intricacies of language. Furthermore, this process is for LLMs only and can only generate text. Other forms of output, like images, follow a separate process. We have defined models to be massive bundles of mathematical equations with parameters that change depending on the amount of training it does from a dataset. But as mentioned before, model training is very costly, as having a clean dataset, training the model with compute resources, and refining the model are serious tasks. But what if we could use a model already finished with these steps, where the parameters of these mathematical equations have been tuned correctly by training with large and clean datasets? These models exist and are called foundation models (FMs). Foundation models are massive deep-learning neural networks that serve as a starting point for data scientists to develop models that can be integrated into applications, allowing the application to have ML-powered features. Foundation models fall under generative AI. As discussed earlier, they generate outputs based on inputs (or prompts) in the form of human instruction. They rely on the learned patterns and relationships to understand the meaning of the prompt and follow the instructions on a technical level. Besides text-based generative capabilities, foundation models are also adept in other fields like code generation, speech recognition and generation, and visual comprehension. Depending on the use case, foundation models can be trained further for specific use cases or if there is a particular body of knowledge for which the model will be used. For instance, ChatGPT now allows custom GPTs, a feature where the default GPT4 model can ingest specific information and contexts, thus increasing the knowledge it can pull from and adjust the responses accordingly. Other major foundation models include Stable Diffusion for image generation, the GPTs from OpenAI, LLaMa from Meta, and Amazon Titan Foundation Models. Generative AI has been the recent powerhouse of the digital world and shows no sign of stopping. A deeper understanding of how they work can help individuals leverage the capabilities they provide and open avenues for innovation. It transforms industries, from healthcare to education to creatives like music and art. With the power generative AI holds, it is important that we use it responsibly as well. We must see it as a tool for augmentation/automation and improving our traditional processes. Not all institutions, and definitely not society as a whole, have set guidelines regarding the proper use of generative AI. Still, as individuals, we can be made aware of the positives and negatives they bring. It is also important to be wary of the data we may feed into these models, whether it is confidential personal medical data or art that an artist has not consented to model training. Specific companies that provide data access through APIs also generally mention in their Terms of Use (TOU) if their data can be used in training these models. Lastly, for those developing these models, it is important that laws govern their data handling and are not to be kept as black boxes. In any case, the marvel of generative AI is here, and just like with all the other technical innovations that have come throughout the years, they are built to improve the human experience, and we should use them as such. Thank you for taking the time to read this article. Happy learning!Demystifying AI, ML DL
1.Linear Regression Model

2. Image Classification Model
3.LLM
Core Principles of Generative AI
“I drank coffee from the mug.”
“I drank coffee from the cup.”
“I drank coffee from the glass.”
“I drank coffee from the ___.”
“I drank coffee from the mug.”
“I drank coffee from the fork.”
Foundation Models Explained
Final Remarks

Resources:
🤖 $3.49 eBooks Start Here – Get Up to 30% OFF All AI & Machine Learning Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





