Last updated on April 3, 2024
Welcome to the dynamic world of AWS Data Engineering! This beginner-friendly guide introduces you to the essentials of data staging and transformation within the AWS ecosystem without needing to code. By exploring the foundational use of Amazon S3 and AWS Glue, this guide provides a practical starting point for understanding how AWS data is handled and processed. Whether you’re aiming for certification or looking to apply these skills in practical scenarios, this guide sets the groundwork for your future in data engineering. In this article, we’ll work with 3 main datasets for a fictional ride-hailing service. These datasets cover crucial information from trip data and driver-vehicle specifics to location-based fare details. Take the time to review the tables below and download them in CSV format afterward using the link given. This format will ensure we can easily upload and manage the data within Amazon S3, setting the stage for our no-code data joining and transformation. Datasets Overview: Imagine stepping into the shoes of a Data Engineer tasked with merging these datasets to prepare them for comprehensive analysis—all without delving into complex coding. Here’s how you’ll accomplish this: Amazon S3 provides a flexible and secure object storage system that scales easily, making data accessible and safe. It’s suitable for all types of users, offering endless data storage solutions for a wide range of uses like data lakes, websites, mobile applications, backup and recovery, archiving, and big data analytics. Below, we detail a practical example of how to begin organizing your data within S3: Congratulations! You have successfully staged your datasets in S3. Next, let’s create a Glue Crawler to populate the AWS Glue Data Catalog. This prepares your data for the next steps in the analysis process, including transformation and enrichment. AWS Glue is a fully managed ETL (Extract, Transform, and Load) service that simplifies and cost-effectively categorizes data, cleans it, enriches it, and moves it between various data stores. With AWS Glue, you can prepare and load your data for analytics with minimal effort and at a lower cost. AWS Glue Studio is a visual interface that simplifies the creation, execution, and monitoring of extract, transform, and load (ETL) jobs in AWS Glue. With this tool, you can visually design data transformation workflows, seamlessly run them on AWS Glue’s Apache Spark-based serverless ETL engine, and inspect the schema and data results at each step of the job. AWS Glue Data Catalog is a central metadata repository that automatically discovers and catalogs data. An AWS Glue Visual ETL Job refers to an ETL (Extract, Transform, and Load) job that is created and managed visually using the AWS Glue Studio interface without writing any code. The key components of a visual ETL job in AWS Glue Studio are: Sources – The sources refer to the input data that will be extracted for processing. Common sources include data stored in Amazon S3, Amazon DynamoDB, Amazon Redshift, etc. Transforms – Transforms refer to the data transformation operations that will be applied on the source data to prepare it for loading into the target. Some of the transforms are: Join – Joining refers to the process of connecting similar data from various sources. For instance, to calculate the total purchase cost of a single item, you could sum up the purchase values from multiple vendors, storing the aggregated sum as the final total in the destination system. Drop fields – This refers to removing or “dropping” certain fields or columns from the data during transformation. This is commonly done to remove unused or unnecessary fields to clean up the data. Change schema – Changing the schema involves transforming the structure of the data, such as renaming or reordering fields, adding or removing fields, or changing the data type of fields. This ensures the transformed data conforms to the schema of the target system. Filtering – Filtering extracts only the relevant data needed from source by applying rules or conditions. For example filtering customer records where country is ‘US’. Targets – Targets refer to the location where the transformed data will be loaded/written after the transformations. Common targets include Amazon. Common targets include Amazon S3, Amazon Redshift, etc. Some key things you can do with targets in AWS Glue include: Changing the file format – You can write the transformed data to different file formats like Parquet, JSON, ORC, etc., based on your requirements. Parquet and JSON are commonly used formats. Configuring compression – You can compress the target files for efficient storage using compression codecs like GZIP and BZIP2. This is configured in the S3 connection properties. Navigate back to your job in the AWS Glue console, and select Run job to start the transformation process. Your AWS Glue ETL job will now process the ride-hailing data according to your specifications, transforming and loading the cleaned and structured data back into S3, ready for analysis and enrichment. By following these steps, you’ve successfully staged and transformed your ride-hailing service data, preparing it for in-depth analysis. This process is crucial for extracting valuable insights to influence strategic decisions and improve service quality. This guide introduced you to the basics of data engineering, focusing on data staging using Amazon S3 and simplifying data transformation with AWS Glue Studio without needing to code. Adopting these methods lays a strong groundwork for your data engineering work, preparing you for more complex data analysis and visualization tasks. Stay connected for more guides that will continue to expand your knowledge and skills in AWS Data Engineering. Remember, the journey to mastering AWS Data Engineering is a marathon, not a sprint. Keep practicing, exploring AWS documentation, and utilizing resources like Tutorials Dojo’s practice exams for a comprehensive understanding and preparation for the AWS Data Engineering Associate exam.
Introduction
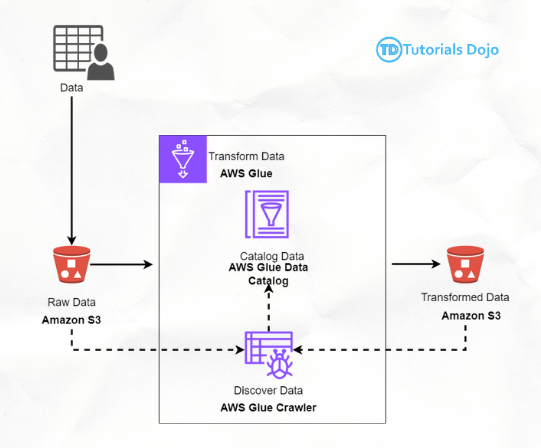
Preparation: Navigating Through Sample Datasets
TripID
DriverID
VehicleID
PickUpLocation
DropOffLocation
StartTime
EndTime
Distance
Fare
Rating
1
DR001
VH001
Intramuros
Muntinlupa
2024-03-01 08:00:00
2024-03-01 09:00:00
12
150
5
2
DR002
VH002
Malate
Las Piñas
2024-03-01 09:00:00
2024-03-01 10:00:00
5
60
4
3
DR003
VH003
Ermita
Parañaque
2024-03-01 10:00:00
2024-03-01 11:00:00
8
80
3
4
DR004
VH004
Santa Cruz
Marikina
2024-03-01 11:00:00
2024-03-01 12:00:00
16
200
5
5
DR005
VH005
Binondo
Mandaluyong
2024-03-01 12:00:00
2024-03-01 13:00:00
3
40
4
6
DR006
VH006
Tondo
Pasay
2024-03-01 13:00:00
2024-03-01 14:00:00
14
170
5
7
DR007
VH007
Paco
Taguig
2024-03-01 14:00:00
2024-03-01 15:00:00
9
100
3
8
DR008
VH008
Pandacan
Pasig
2024-03-01 15:00:00
2024-03-01 16:00:00
7
75
4
9
DR009
VH009
Quiapo
Quezon City
2024-03-01 16:00:00
2024-03-01 17:00:00
18
220
5
10
DR010
VH010
Sampaloc
Makati
2024-03-01 17:00:00
2024-03-01 18:00:00
11
130
3
DriverID
Name
Age
VehicleID
VehicleType
VehicleRegistration
CityID
DR001
Jose Rizal
25
VH001
Sedan
Tamaraw
CT001
DR002
Andres Bonifacio
36
VH002
Van
Kalabaw
CT002
DR003
Emilio Aguinaldo
47
VH003
SUV
Maya
CT003
DR004
Apolinario Mabini
52
VH004
Sedan
Agila
CT004
DR005
Marcelo H. del Pilar
33
VH005
Van
Palawan Bearcat
CT005
DR006
Juan Luna
28
VH006
SUV
Tarsier
CT006
DR007
Melchora Aquino
41
VH007
Sedan
Pawikan
CT007
DR008
Gabriela Silang
39
VH008
Van
Butanding
CT008
DR009
Gregorio del Pilar
29
VH009
SUV
Paniki
CT009
DR010
Lapu-Lapu
45
VH010
Sedan
Sundalong Ant
CT010
PickUpLocation
DropOffLocation
BaseFare
SurgeMultiplier
Intramuros
Muntinlupa
40
1
Malate
Las Piñas
50
1.2
Ermita
Parañaque
60
1.5
Santa Cruz
Marikina
70
0.8
Binondo
Mandaluyong
80
1.3
Tondo
Pasay
90
1.1
Paco
Taguig
100
1.4
Pandacan
Pasig
110
1
Quiapo
Quezon City
120
1.2
Sampaloc
Makati
130
1.3
Your Mission as a Data Engineer
Data Staging with Amazon S3

Step-by-Step Guide:
ride-hailing-data-<number or your name>).
Data Transformation with AWS Glue
Step-by-Step Guide:
Create a Glue Crawler:
ride-hailing-data-crawler.
AWSGlueServiceRole-RideHailingData.



arn:aws:s3:::ride-hailing-data-<number or your name>/transformed data*

ride_hailing_service_data).ride_hailing_service_data as the database.Prepare Your AWS Glue Environment:
Create an AWS Glue ETL Job:
ride-hailing-data-transformation) and the IAM role you created (e.g., AWSGlueServiceRoleRideHailingData)
ride_hailing_service_data
Remember that our objective is to merge and prepare these datasets for analysis. There are many transform types you can choose from. For simplicity, JOIN, DROP FIELDS, and CHANGE SCHEMA are enough to achieve our goal. You can explore the other transform types and add as you see fit.EXPECTED OUTPUT:

Trip ID
Driver ID
Name
Vehicle Type
Pick Up
Drop Off
Start Time
End Time
Distance
8
DR008
Gabriela Silang
Van
Pandacan
Pasig
2024-03-01 15:00:00
2024-03-01 16:00:00
7
2
DR002
Andres Bonifacio
Van
Malate
Las Piñas
2024-03-01 09:00:00
2024-03-01 10:00:00
5
3
DR003
Emilio Aguinaldo
SUV
Ermita
Parañaque
2024-03-01 10:00:00
2024-03-01 11:00:00
8
4
DR004
Apolinario Mabini
Sedan
Santa Cruz
Marikina
2024-03-01 11:00:00
2024-03-01 12:00:00
16
7
DR007
Melchora Aquino
Sedan
Paco
Taguig
2024-03-01 14:00:00
2024-03-01 15:00:00
9
6
DR006
Juan Luna
SUV
Tondo
Pasay
2024-03-01 13:00:00
2024-03-01 14:00:00
14
9
DR009
Gregorio del Pilar
SUV
Quiapo
Quezon City
2024-03-01 16:00:00
2024-03-01 17:00:00
18
5
DR005
Marcelo H. del Pilar
Van
Binondo
Mandaluyong
2024-03-01 12:00:00
2024-03-01 13:00:00
3
1
DR001
Jose Rizal
Sedan
Intramuros
Muntinlupa
2024-03-01 08:00:00
2024-03-01 09:00:00
12
10
DR010
Lapu-Lapu
Sedan
Sampaloc
Makati
2024-03-01 17:00:00
2024-03-01 18:00:00
11

Run the ETL Job:
Expected Result:

Conclusion
References
🔥$4.99 Claude Certified Architect Foundations CCA-F Video Course – Limited-Time Deal!

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





