Retrieval-Augmented Generation (RAG) Cheat Sheet
-
Retrieval-Augmented Generation (RAG) is a method that enhances large language models (LLMs) outputs by incorporating information from external, authoritative knowledge sources.
-
Instead of relying solely on pre-trained data, RAG retrieves relevant content at inference time to ground its responses.
-
LLMs (Large Language Models) are trained on massive datasets and use billions of parameters to perform tasks like:
-
Question answering
-
Language translation
-
Text completion
-
-
RAG extends LLM capabilities to domain-specific or private organizational knowledge without requiring model retraining.
-
It provides a cost-efficient way to improve the relevance, accuracy, and utility of LLM outputs in dynamic or specialized contexts.
-
Especially useful when content must reflect up-to-date, internal, or proprietary information.
Importance of RAG
Large Language Models (LLMs) are a foundational AI technology behind intelligent chatbots and other natural language processing (NLP) applications. Their core objective is to provide relevant answers to user queries across diverse contexts, ideally by referencing trustworthy, authoritative information.
However, LLMs face key limitations:
-
They can generate unpredictable or incorrect responses.
-
They may confidently present:
-
False information is given when an answer is unknown.
-
Outdated or vague details instead of current facts.
-
Content based on unreliable sources.
-
Confusing or inaccurate responses due to inconsistent terminology in training data.
-

Think of an LLM like a confident new hire who always has an answer, whether they know what they’re talking about. They sound convincing, but sometimes they’re misinformed, outdated, or just plain wrong. While that enthusiasm is impressive, it can quickly become a problem, especially when accuracy matters. Trust takes a hit, and relying on them for essential decisions becomes risky.
Retrieval-Augmented Generation (RAG) addresses these challenges by directing the LLM to fetch relevant, up-to-date content from curated, authoritative knowledge sources. This approach improves response accuracy, enhances transparency, and gives organizations greater control over the model’s outputs.
How RAG Benefits Your Generative AI Strategy
Retrieval-Augmented Generation (RAG) is more than just a technical upgrade—it’s a more innovative, more practical way to bring generative AI into your organization. Here’s why it makes such a difference:
- Cost-Effective and Scalable
-
Avoids the high cost and complexity of retraining large language models (LLMs) for domain-specific knowledge.
-
It lets you reuse powerful foundation models by connecting them to external/internal data sources.
-
Integrates organization-specific knowledge without modifying the model itself.
-
It makes generative AI more accessible across teams and use cases by lowering technical and financial barriers.
-
- Keeps Your AI Updated
-
Solves the issue of stale or outdated information in pre-trained models.
-
Connects your LLM to live or frequently updated sources, such as:
-
News feeds
-
Research databases
-
Internal knowledge bases or policy docs
-
-
Ensures responses stay relevant and current, even when data changes rapidly.
-
Great for industries that require real-time insights or up-to-date compliance info.
-
- Builds Trust Through Transparency
-
Adds citations or source links to generated responses.
-
Allows users to verify answers by checking the original documents or knowledge sources.
-
It makes AI less of a “black box” and more of a transparent assistant.
-
Builds confidence and credibility, especially for customer-facing or regulated applications.
-
- Puts Developers in the Driver’s Seat
-
Managing the retrieval sources gives developers complete control over what the LLM knows.
-
Enables quick updates without retraining—just adjust the connected content.
-
It supports role-based access so users can see different data based on authorization levels.
-
It makes debugging or refining responses easier by tracing issues back to specific sources.
-
Offers flexibility to adapt the chatbot or application for different teams, products, or audiences.
-
- Broader, Safer Use Across the Business
-
RAG makes AI adoption safer for internal and external users.
-
Suitable for a wide range of functions, including:
-
Customer support
-
Employee self-service
-
Research assistants
-
Legal and compliance tools
-
-
Helps scale generative AI across departments without introducing unnecessary risk.
-
Increases organizational confidence in deploying AI for high-impact and high-trust scenarios.
-
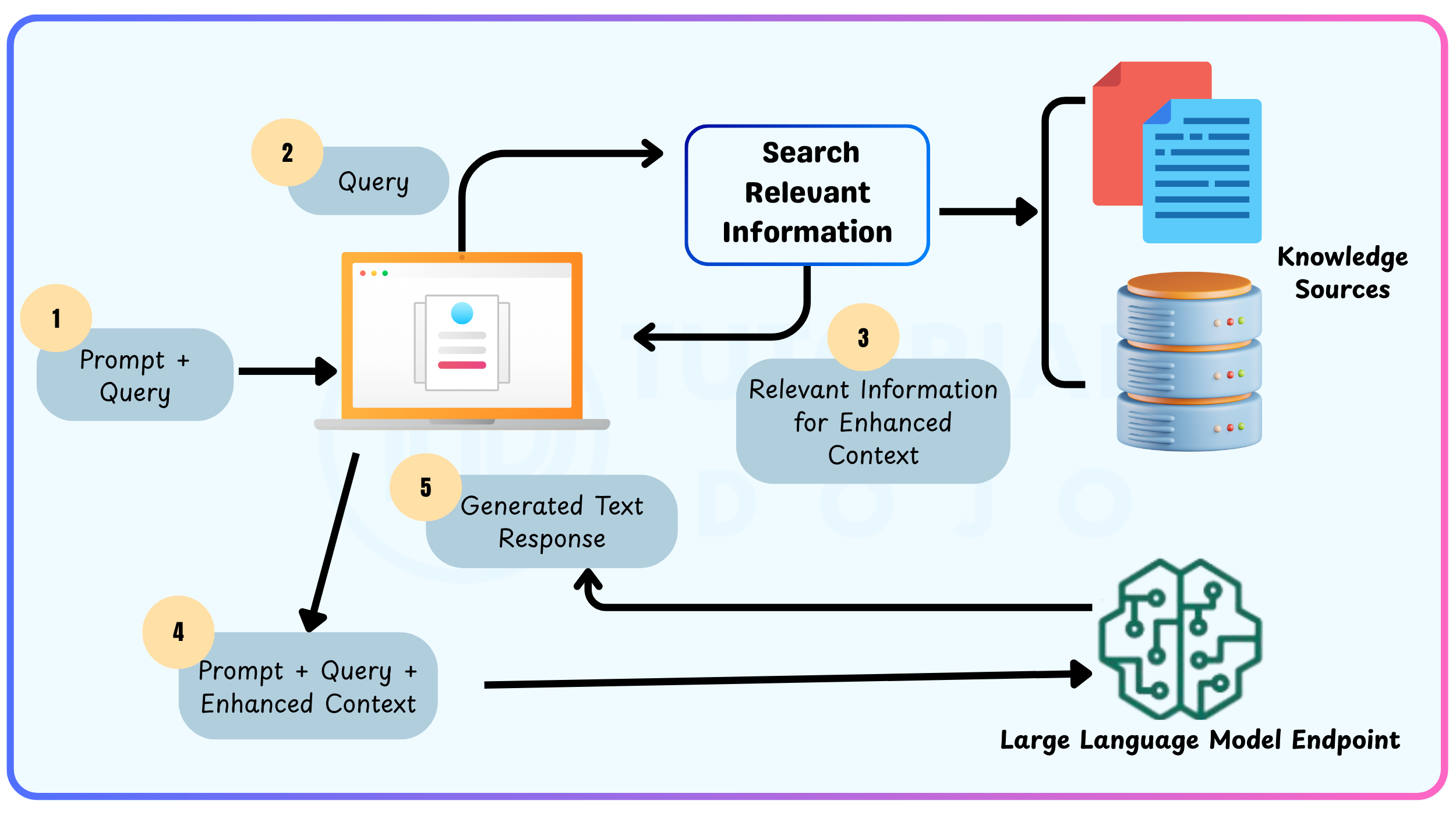
How Retrieval-Augmented Generation (RAG) Works
RAG improves the conventional workflow of large language models (LLMs) by adding a retrieval step prior to generating a response. Here’s how the process works:
- Create External Data (Knowledge Source)
-
External data refers to information outside the LLM’s original training set.
-
Can include:
-
Internal company documents
-
Databases and records
-
Web pages, PDFs, manuals, or API outputs
-
-
Since LLMs can’t naturally understand raw documents, we use embedding models to:
-
Convert the text into numeric vectors (representations of meaning).
-
Store those vectors in a vector database, forming a searchable knowledge base.
-
-
This enables the LLM to later “understand” and use that information in its responses.
-
- Retrieve Relevant Information
-
When a user submits a question or query:
-
It’s also converted into a vector (numeric format).
-
That vector is matched against stored vectors in the database to find the most relevant chunks of information.
-
-
-
Example:
A chatbot for HR is asked, “How much annual leave do I have?”
→ The system might retrieve:-
Company leave policy documents
-
That employee’s personal leave balance from the database
-
-
The retrieval engine uses mathematical similarity (not just keyword search) to ensure results are contextually accurate.
-
- Augment the LLM Prompt
-
The retrieved information is combined with the original user input.
-
This forms an augmented prompt that gives the LLM added context.
-
By doing this, the LLM:
-
Has access to fresh, specific, and relevant information
-
Can generate more accurate and context-aware responses
-
-
This step often involves prompt engineering—crafting inputs in a way the LLM best understands.
-
- Keep External Data Updated
-
For RAG to remain effective, the knowledge base must be kept current.
-
You can update external data in two ways:
-
Real-time updates (e.g. from APIs or live documents)
-
Periodic batch updates (scheduled processing of new info)
-
-
Once new documents are added, user must recompute embeddings to keep search accuracy high.
-
Retrieval-Augmented Generation vs. Semantic Search
Semantic Search
-
Retrieve the most relevant documents or passages based on meaning, not just keywords.
-
Maps queries and documents into a vector space using embeddings, then retrieves similar ones via similarity scoring (e.g., cosine similarity).
-
Returns a ranked list of relevant documents/passages.
-
Typically used in search engines, FAQ bots, and document retrieval systems.
-
It retrieves but does not generate new content.
-
Generally faster and requires fewer compute resources than RAG.
RAG (Retrieval-Augmented Generation)
-
Combines retrieval with generation to produce coherent, informative responses.
-
Functionality:
-
Step 1: Retrieves relevant documents (often using semantic search under the hood).
-
Step 2: Passes retrieved content to a language model to generate a natural-language answer.
-
-
Generates a new answer, often incorporating multiple documents.
-
Typically used chatbots, Q&A systems, and knowledge assistants (e.g., ChatGPT browsing with retrieval).
-
Can synthesize, summarize, or rewrite the retrieved data.
-
It requires more computing and a generative model (like GPT or something similar).

| Feature | Semantic Search | RAG |
| Output Type | Retrieved documents/passages | Generated answers |
| Does it use a Generator? | ❌ No | ✅ Yes |
| Complexity | Simpler | More complex (retrieval + generation) |
| Speed | Faster | Slower (due to the generation step) |
| Use Case | Search interfaces | Conversational AI, knowledge assistants |
| Combines Documents? | ❌ No | ✅ Often synthesizes multiple sources |
RAG Cheat Sheet References:
https://aws.amazon.com/what-is/retrieval-augmented-generation/
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
🔥 43% OFF AWS & Azure Pro-Level Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





