Stage 2 of the AWS Data and AI Journey: Integrating and Moving Data Across Systems
As organizations build a modern data foundation, the next challenge is ensuring that data can move efficiently across systems, teams, and applications. Even with scalable storage and analytics platforms in place, data often remains fragmented across cloud services, SaaS tools, on-premises environments, and operational systems.
Without reliable integration, data becomes delayed, siloed, or difficult to operationalize. This limits an organization’s ability to generate timely insights, automate workflows, and support AI-driven decision-making.
Stage 2 of the AWS Data and AI journey focuses on integrating and moving data across systems. At this stage, organizations aim to create continuous data flows, connect critical sources, and adopt modern DataOps practices that improve reliability, speed, and collaboration.
This article explores why data integration matters, what a modern movement strategy looks like, and how AWS Marketplace solutions can help organizations build real-time, connected, and operational data environments.
Why Data Integration Matters
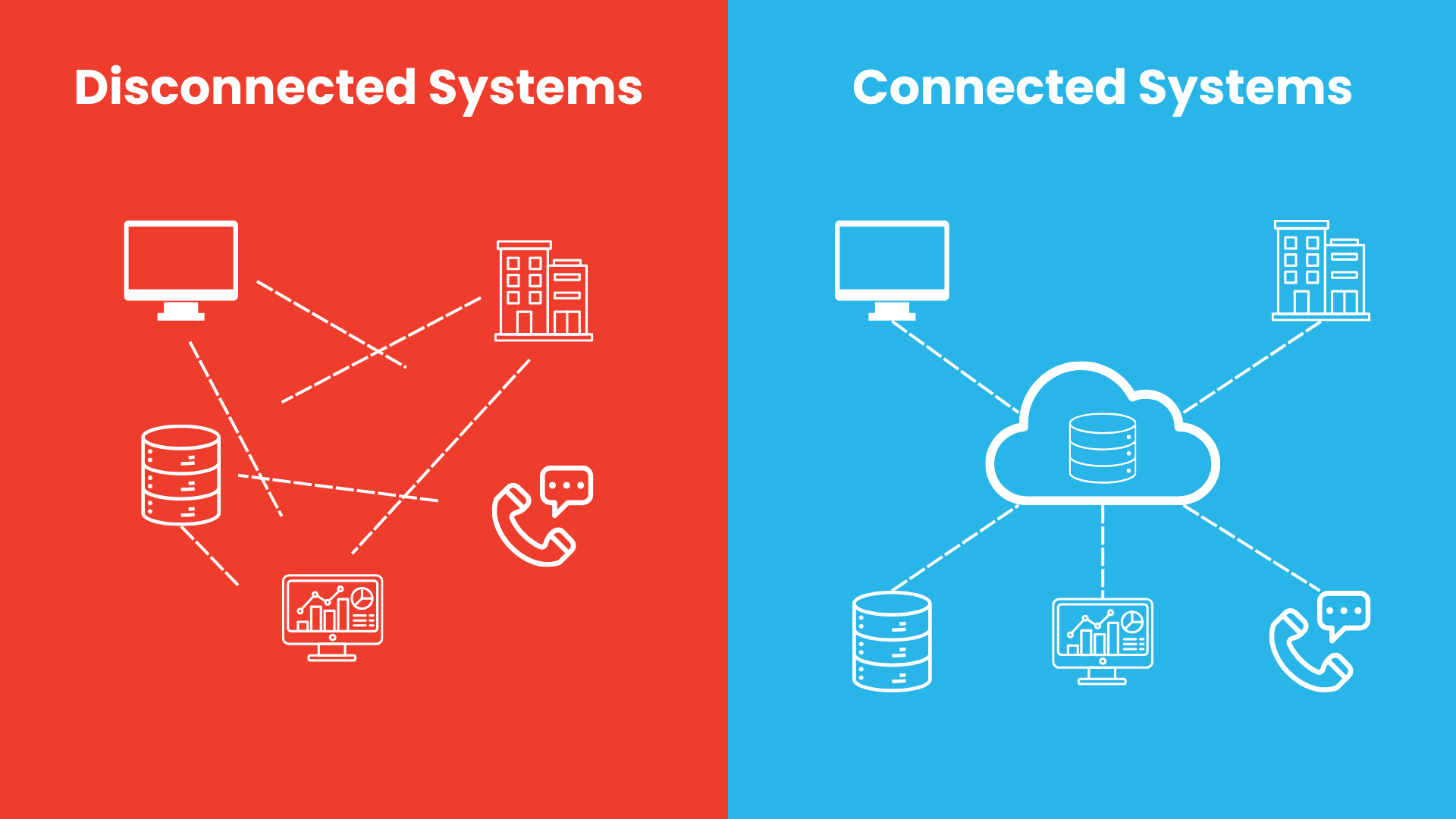
Data is most valuable when it can move freely and reliably to where it is needed. In many organizations, however, important information is spread across multiple platforms such as CRM systems, ERP platforms, databases, cloud applications, and internal tools.
When these systems are disconnected, teams often rely on manual exports, delayed batch jobs, or custom scripts to transfer data. This creates several common problems:
- Delayed reporting and outdated insights
- Duplicate data pipelines and inconsistent transformations
- Limited visibility across business functions
- Difficulty operationalizing analytics outcomes
- Higher maintenance effort for engineering teams
Modern organizations need more than isolated pipelines. They need an integration strategy that supports continuous movement of data across the business.
A strong integration layer should support:
- Real-time and batch data pipelines
- Connectivity across cloud, SaaS, on-premises, and edge sources
- Event-driven architectures for immediate reactions
- DataOps practices for quality, testing, and deployment
- Reverse ETL to activate data in operational tools
Without these capabilities, organizations struggle to turn their data foundation into a connected system that supports analytics, automation, and AI at scale.
Moving Beyond Traditional ETL
Traditional extract, transform, and load (ETL) approaches are still useful, but many older data movement models were designed for periodic batch processing rather than continuous, real-time operations.

Today’s data environments require faster and more flexible approaches. Businesses increasingly depend on streaming pipelines, event-driven architectures, and near real-time synchronization between systems.
Instead of moving data once per day or once per hour, organizations now aim to refresh critical data in minutes or even seconds. This is especially important for applications such as:
- Customer activity tracking
- Fraud detection
- Operational monitoring
- Personalized recommendations
- Real-time dashboards
- AI and machine learning workflows
A modern integration strategy enables data to move continuously, reducing latency between data generation and action.
Breaking Down Data Silos
As companies grow, data silos often emerge across departments and systems. Marketing, finance, operations, product, and customer support may each use different tools and maintain separate datasets.
This fragmentation reduces collaboration and makes it difficult to establish a reliable, enterprise-wide view of the business.
To solve this, organizations must connect diverse environments, including:
- SaaS applications
- Cloud databases and storage platforms
- On-premises systems
- Operational applications
- Edge and streaming sources
The goal is not only to centralize data, but also to make it usable across teams and workflows. By integrating these systems, organizations can create unified pipelines that improve reporting, analytics, and decision-making across the enterprise.
Adopting Streaming and Event-Driven Architectures
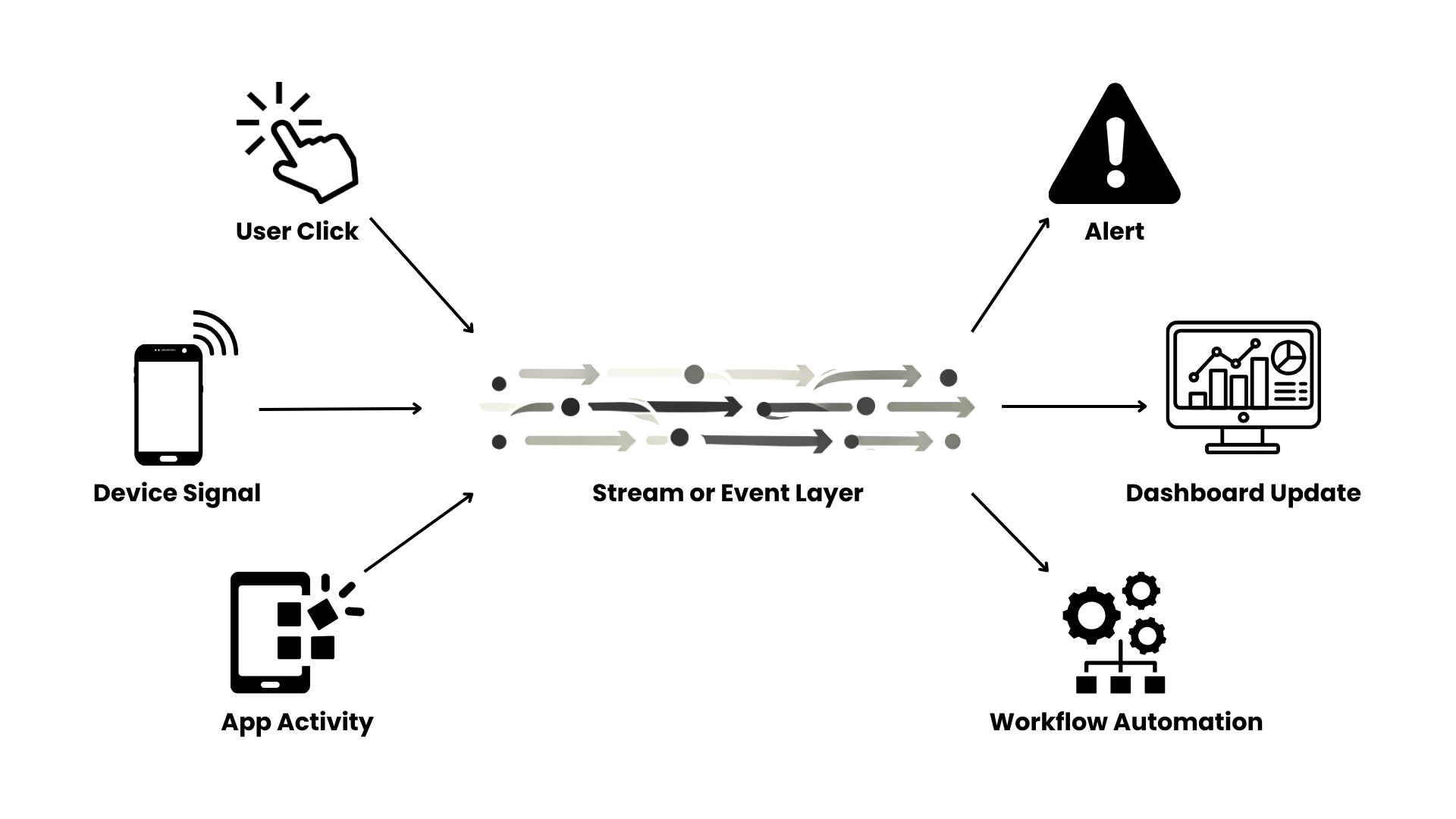
One of the most important shifts in Stage 2 is the move toward streaming-first and event-driven systems.
In a streaming architecture, data is processed continuously as it is generated. In an event-driven architecture, systems react immediately to specific triggers such as a transaction, status update, sensor signal, or user action.
These approaches allow organizations to:
- React to events in real time
- Reduce delays between systems
- Support automated workflows
- Power low-latency applications
- Improve responsiveness at scale
This is especially valuable for modern digital businesses where timing matters. Real-time architectures help ensure that business decisions are based on the latest available data rather than outdated snapshots.
Introducing DataOps for Reliability and Speed
As data pipelines become more complex, organizations need better ways to manage changes, improve data quality, and maintain reliability.
This is where DataOps becomes important. DataOps applies modern software engineering practices to data workflows. It helps teams build pipelines that are more consistent, testable, and scalable.
Key DataOps practices include:
- Version control for transformations and pipeline logic
- Automated testing for data quality and schema changes
- CI/CD pipelines for analytics and data workflows
- Monitoring for failures, freshness, and reliability
- Collaboration across engineering, analytics, and operations teams
By adopting DataOps, organizations reduce pipeline failures, improve trust in data, and accelerate the delivery of insights.
Enabling Reverse ETL and Operational Activation
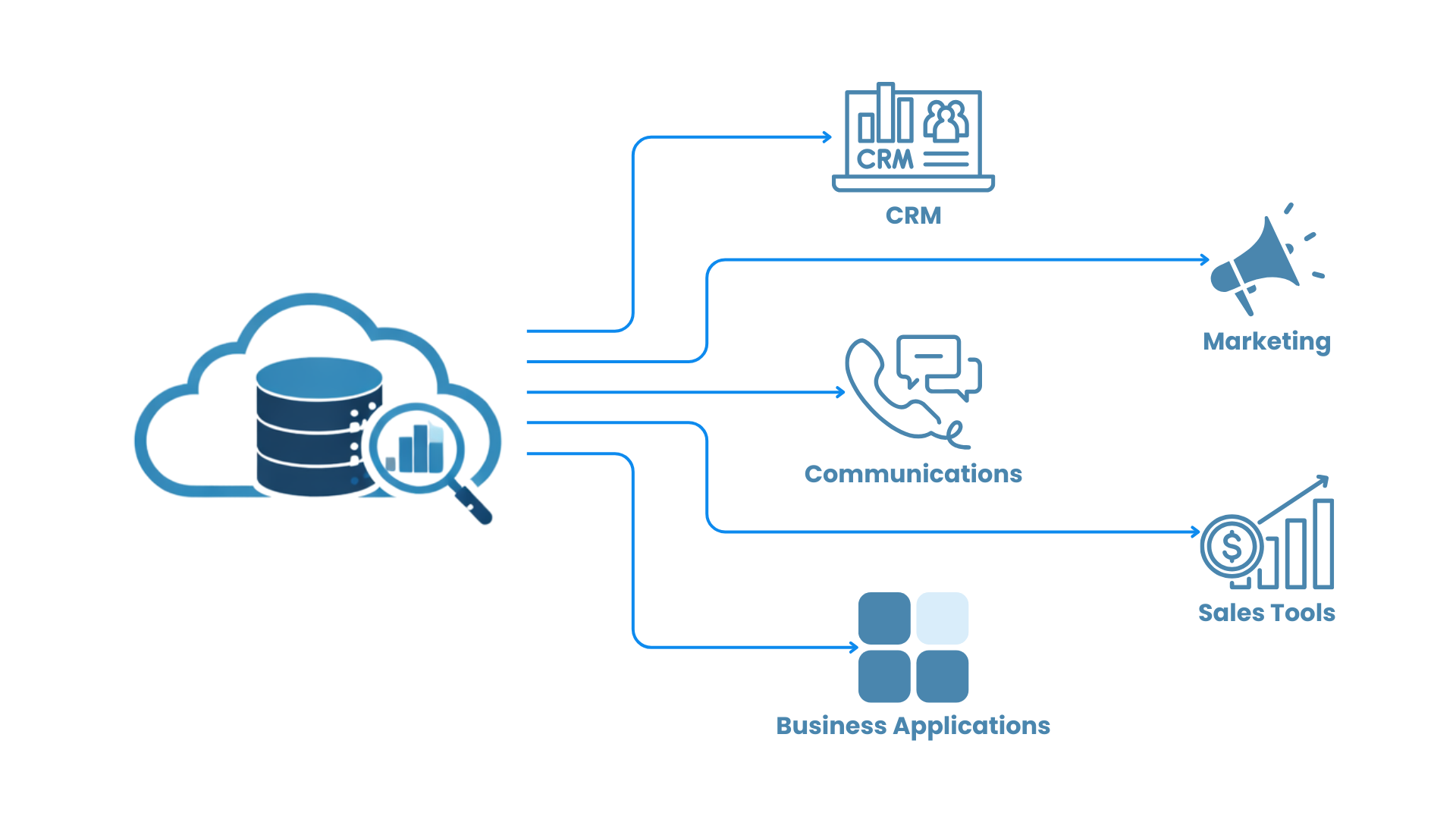
Integration is not only about moving data into warehouses or lakes. It is also about moving enriched data back into the tools where business teams work every day.
This approach is known as reverse ETL. Reverse ETL allows organizations to sync processed or enriched data from analytical platforms into operational systems such as CRM platforms, marketing tools, customer support platforms, and business applications. This makes data more actionable by allowing business teams to use insights directly in their workflows.
For example, reverse ETL can support:
- Sending customer segments into marketing platforms
- Updating sales tools with product usage insights
- Enriching support systems with customer behavior data
- Feeding operational dashboards with processed analytics results
This helps organizations move from passive reporting to active data-driven operations.
AWS Marketplace Solutions for Stage 2
At this stage of the journey, organizations need solutions that can connect data sources, orchestrate movement, and support modern pipeline architectures. AWS Marketplace offers partner solutions that help organizations accelerate data integration without having to build every connector and workflow manually.

These solutions support both traditional and modern integration needs, from ETL and ELT to streaming, synchronization, and operational activation.
Data Integration and Pipeline Automation
Solutions such as Fivetran, Airbyte, and Matillion help organizations connect data from a wide range of systems and move it into cloud data platforms efficiently. These tools simplify pipeline development, reduce manual integration work, and support scalable ingestion across business-critical sources.
Streaming and Event-Driven Data Movement
Platforms such as Confluent enable organizations to build streaming-first architectures that support continuous data flow and event-driven processing. These tools are valuable for businesses that need low-latency pipelines and real-time responsiveness across applications and services.
Workflow Orchestration and Data Transformation
Solutions such as Matillion help organizations design, orchestrate, and transform data pipelines across cloud environments. In AWS Marketplace, Matillion is positioned as a platform for moving, transforming, and orchestrating data pipelines faster, which makes it a stronger fit for this section than leaving it generic.
Reverse ETL and Operational Sync
For reverse ETL and operational activation, Hightouch is a clear product example. Its AWS Marketplace listing describes it as a reverse ETL platform that activates customer data from the warehouse into CRM, marketing, and support tools, which directly matches your point about syncing enriched data back into operational systems.
How These Solutions Support a Connected Data Environment
The solutions highlighted in this stage help organizations build the core capabilities needed for integrated and continuously moving data systems:
Data ingestion and connectivity layer
- Fivetran
- Airbyte
- Matillion
Streaming and event-driven layer
- Confluent
Transformation and orchestration layer
- Matillion
Operational activation and reverse ETL layer
- Hightouch
By combining these technologies with AWS services, organizations can create unified data pipelines that support both real-time and batch workflows while reducing silos across systems.
AWS Marketplace simplifies this process by offering ready-to-deploy partner solutions that integrate directly with AWS environments, helping organizations accelerate implementation and reduce complexity.
What Comes Next
Once data is moving reliably across systems, the next priority is ensuring that it remains trusted, secure, and governed.
In the next stage of this series, we explore how organizations can govern and secure data at scale by strengthening access controls, automating data discovery and classification, improving observability, and enforcing compliance across environments.
References
📚 $0.99 eBooks Start Here – Up to 80% OFF All Products Mid-Year Sale Extension!

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





