Last updated on February 8, 2026
I discovered something embarrasing about my LLM development workflow last month.
After spending hours crafting what I thought was the perfect prompt for a customer service chatbot on Amazon Bedrock, I deployed it and called it done. My validation process? I asked it five questions, nodded approvingly at the responses, and moved on.
Sound familiar?
This “vibe-based prompting” approach worked fine until the chatbot confidently told a user that our fictional company offers “24/7 phone support,” a feature that never existed. The model hallucinated, and I had no automated way to catch it.
That experience sent me down a rabbit hole into LLM evaluation, also known as “evals,” among others. What I found changed how I think about building GenAI applications. If you’re a student learning to build with Amazon Bedrock, this might save you from my mistakes.
The Uncomfortable Truth About LLM Development
Here’s what nobody tells you: LLMs are confidently wrong all the time.
They’ll cite nonexistent research papers. They’ll invent API endpoints. And they’ll do it with the same confident tone they use when giving you actually correct information.
This matters more than ever because people now use LLMs for serious stuff:
- Summarizing legal documents and policy changes
- Displaying real-time financial data in customer apps
- Creating educational content for universities
- Explaining medication interactions to patients
- Recommending software libraries that release updates monthly
A model trained on data from 2023 doesn’t know what happened yesterday. It doesn’t know if that SDK version you’re asking about has a critical security vulnerability discovered last week. But it’ll answer anyway.
Traditional software testing doesn’t help here. You can’t just check if the output equals some expected string—LLM responses are non-deterministic by design. The same prompt might give you three different (but valid) phrasings of the same answer.
So how do you test something that’s supposed to be creative and variable?
LLM Evaluation and Why It’s Different
LLM evaluation is like unit testing for prompts, but with a twist.
Instead of checking “does output == expected,” you’re asking questions like:
- Does this response contain the key information it should?
- Is the tone appropriate for a customer service context?
- Did the model stay grounded in the provied context, or did it make stuff up?
- Would a human expert consider this response helpful?

A proper evaluation setup has four compoents:
- Test inputs: the prompts or questions you give at the model
- Expected behavior: not exact strings, but criteria for what “good” looks like
- Model outputs: what your LLM actually generates
- Scoring logic: how you measure success
The scoring part is where things diverge from traditional testing. You’ve got options:
Deterministic checks work for structured outputs. Does the JSON parse correctly? does it contain required fields? Is the response under 500 tokens?
Semantic similarity compares meaning rather than exact words. “The capital of France is Paris” should match with “Paris serves as France’s capital city.”
LLM-as-a-judge uses another model to evaluate responses. You basically ask Claude to grade Claude’s homework. Surprisingly effective for subjective qualities like helpfulness and tone.
Human evaluation remains the gold standard for nuanced assessment, but it doesn’t scale.
The best evaluation strategies combine multiple approaches. You might use deterministic checks for format validation, semantic similarity for content accuracy, and LLM-as-a-judge for subjective quality, all on the same test case.
Promptfoo: The Testing Framework That Made It Click
After researching options, I landed on Promptfoo. An open-source evaluation framework with over 9,000 stars on GitHub. Think of it as Jest or Pytest, but for prompts. promptfoo is an open-source CLI and library for evaluating and red-teaming LLM apps.
What sold me:
It’s actually open source. MIT license, no strings attached. LLM evals should be a commodity, not a premium feature locked behind enterprise pricing.
It speaks YAML. Configuration is declarative and readable. No complex SDKs to learn.
It integrates with everything. Bedrock, OpenAI, Anthropic, local models, custom APIs.
It runs locally. Your prompts and test data never leave your machine unless you want them to.
promptfoo produces matrix views that let you quickly evaluate outputs across many prompts. Here’s an example of a side-by-side comparison of multiple prompts and inputs from promptfoo docs.
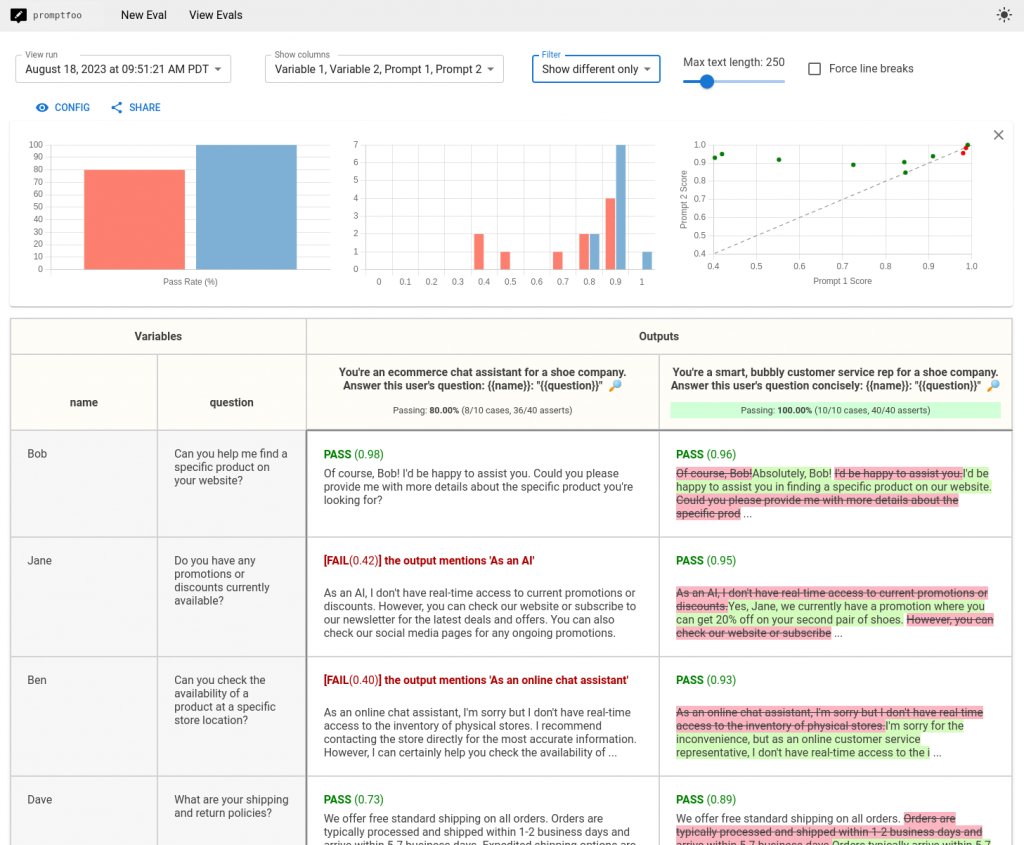
It also works on the command line:

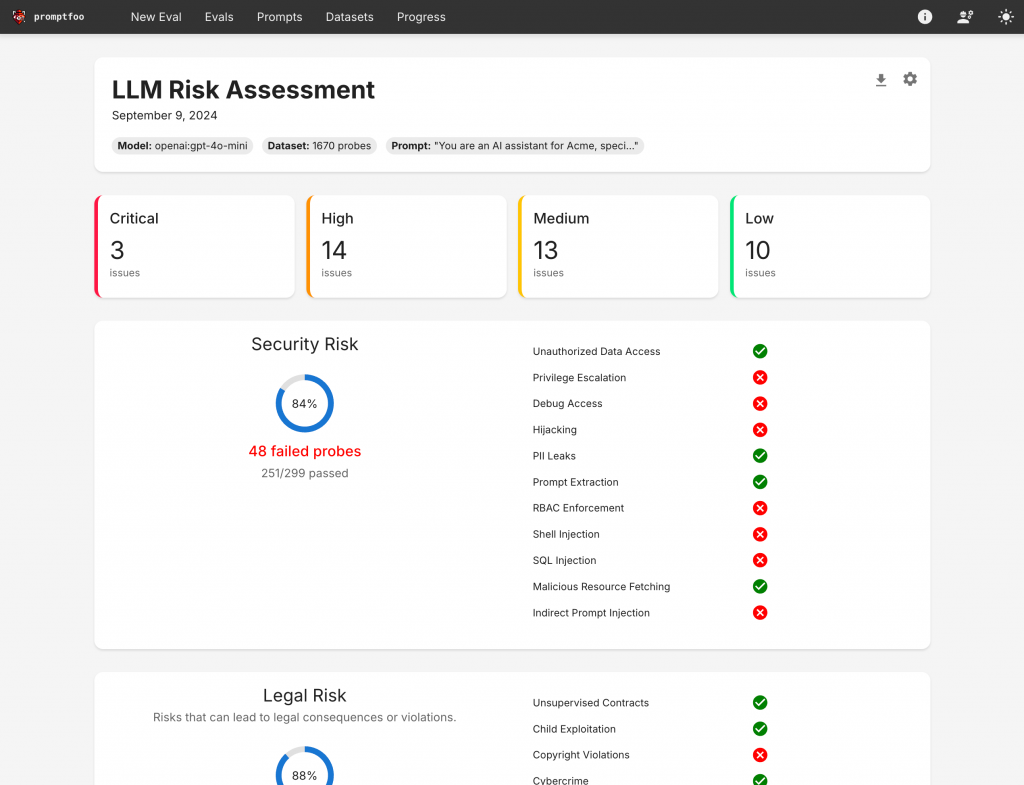
also produces high-level vulnerability and risk reports:
But Wait — Doesn’t Bedrock Already Do This?
Yes, Amazon Bedrock now has native evaluation capabilities.
At re:Invent 2024, AWS announced LLM-as-a-judge and RAG evaluation features, which became generally available in March 2025. These are well-designed tools that let you:
- Evaluate model responses using judge models like Claude or Nova
- Assess RAG pipelines for context relevance and faithfulness
- Run evaluations directly from the Bedrock console
- Get normalized scores with explanations
AWS claims up to 98% cost savings compared to human evaluation, and for certain use cases, that’s compelling.
So why bother with Promptfoo?
Different tools for different jobs.
Bedrock Evaluations excels at:
- Comparing foundation models before you commit to one
- One-time assessments of model quality
- Human evaluation workflows with managed workforces
- Enterprise scenarios where everything must stay within AWS
Promptfoo excels at:
- CI/CD integration (block deployments on failing evals)
- Rapid iteration during development
- Testing across multiple providers simultaneously
- Security testing and red-teaming
- Running locally without AWS credentials during development
Amazon Bedrock Evaluations helps you pick the right model. Promptfoo helps you ship the right prompts.
Setting Up Promptfoo with Amazon Bedrock
Here’s how to set up Promptfoo for Bedrock development.
Prerequisites
You’ll need:
- Node.js 18 or higher
- AWS credentials configured (via environment variables, credentials file, or IAM role)
- Access to Bedrock models in your AWS account
Installation
bash
npm install -g promptfoo@latest # or, if you use npx npx promptfoo initConfigure AWS Credentials
Promptfoo uses the standard AWS SDK, so your existing credentials work:
# Environment variables export AWS_ACCESS_KEY_ID=your_key export AWS_SECRET_ACCESS_KEY=your_secret export AWS_REGION=us-east-1Your First Bedrock Evaluation
Create a file called
promptfooconfig.yamldescription: "My first Bedrock evaluation" defaultTest: options: provider: bedrock:anthropic.claude-3-haiku-20240307-v1:0 providers: - id: bedrock:anthropic.claude-3-haiku-20240307-v1:0 config: region: us-east-1 - id: bedrock:amazon.nova-lite-v1:0 config: region: us-east-1 prompts: - "Explain {{concept}} to a college freshman in 2-3 sentences." tests: - vars: concept: "machine learning" assert: - type: contains-any value: ["data", "pattern", "learn", "algorithm"] - type: javascript value: output.length < 500 - vars: concept: "quantum computing" assert: - type: contains-any value: ["qubit", "superposition", "quantum"] - type: llm-rubric value: "Explanation should be accurate and accessible to someone without a physics background"Run it:
bash
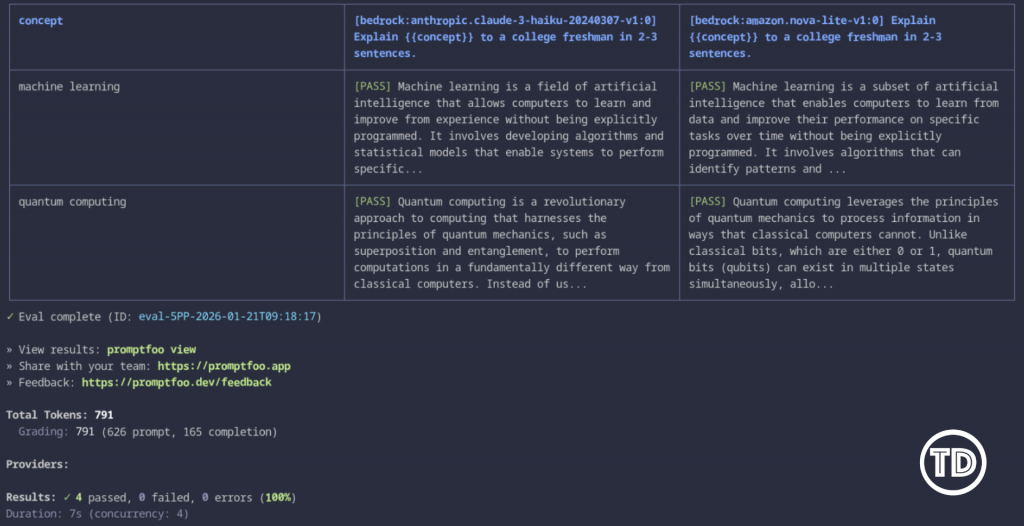
npx promptfoo eval -c promptfooconfig.yamlYou’ll see a table comparing how Claude Haiku and Nova performed on each test case. Maybe Haiku nails the explanations, but runs slower. Maybe Nova is cheaper but misses some key concepts. Now you have data to make decisions.
Promptfoo CLI showing evaluation results comparing Claude Haiku and Titan models on Amazon Bedrock
When To Use What: A Decision Framework
After spending time with both tools, here’s my mental model:
Use Bedrock Evaluations when:

- You’re selecting between foundation models for a new project
- You need human evaluation at scale
- Compliance requries everything stays within AWS
- You’re doing comprehensive quarterly assessments
Use Promptfoo when:
- You’re actively developing and iterating on prompts
- You need evals in CI/CD pipelines
- You’re testing across multiple providers (Bedrock + OpenAI + local)
- You need security/red-team testing
- You want to run evals locally without cloud dependencies
Use both when:
- You’re building production GenAI systems that need continuous validation
- Initial model selection with Bedrock Evaluations
- Ongoing development and deployment with Promptfoo
They’re complementary, not competing.
What I Wish Someone Had Told Me
A few lessons from my journey into LLM evaluation:
Start small. You don’t need 500 test cases on day one. Start with 10 that cover your critical paths. Add more as you find edge cases.
Test for what matters. Don’t eval everything. Focus on behaviors that would cause real problems if wrong — hallucinations, safety issues, brand voice violations.
Invest in good test data. Garbage inputs produce garbage insights. Spend time crafting realistic test cases that reflect actual user behavior.
Evals reveal architecture problems. When evaluation showed our RAG system failing, we discovered the retrieval step was broken — not the generation. Evals are diagnostics, not just grades.
Embrace non-determinism. LLM outputs vary. Write assertions that check for semantic correctness, not exact matches. Use contains-any, llm-rubric, and similarity checks.
Track costs. Running evals costs money (API calls). Promptfoo shows token usage. Keep an eye on it, especially with LLM-as-judge.
The documentation at promptfoo.dev covers Bedrock-specific setup in detail.
Resources
🔥 $0.99 NEW Study Guide eBook – Claude Certified Associate – Foundations CCAO-F

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





