Last updated on October 5, 2025
When you’re running a production website on an EC2 instance, the last thing you want is for it to unexpectedly go down while you’re focused on other tasks. Without the right monitoring in place, you might not even realize your site has been offline for a while, and repeated downtimes like this are unacceptable for any production application. If you’ve faced this issue before or just want to be prepared so it doesn’t happen to you, then you’re in the right place. In this article, I’ll show you a simple way to automate recovery with CloudWatch so your site stays up and running.
Understanding First the EC2 Status Checks
If you’re running your website or application on an EC2 instance, AWS gives you built-in status checks to help you stay on top of potential issues. These checks run automatically in the background and look at three key areas: the AWS systems that power your instance, the instance’s own operating system, and the attached EBS volumes. Knowing how each check works helps you figure out whether the issue is something AWS will handle or something you need to fix yourself. Let’s go through each of these status checks in detail so you know exactly what they mean.

- System status checks
Monitors the AWS infrastructure hosting your instance. It detects problems such as hardware failure, loss of network connectivity, or AWS-side software issues. Failures here are usually out of your control and may require restarting the instance or waiting for AWS to fix the issue. - Instance status checks
Monitors the software and network configuration of your instance itself. Failures typically indicate issues like corrupted file systems, kernel panics, misconfigured networking, or resource exhaustion. These are usually the user’s responsibility to fix. - Attached EBS status checks
Checks the reachability and health of attached EBS volumes. It ensures that your EC2 instance can communicate with its storage volumes. If this check fails, it may indicate I/O errors, degraded volume performance, or issues with volume attachment.
These status checks play a critical role in keeping your EC2 instance healthy. If any of them fail, it often means your instance won’t function as expected, which usually translates to downtime for your application in production. And as you know, even a short outage can impact users, cause frustration, and potentially lead to lost opportunities. That’s why it’s important to understand what each check monitors and what it means when something goes wrong.
How Status Check Alarms Keep Your EC2 Running
Knowing what the EC2 status checks do is one thing, but actively monitoring them all the time is another challenge. While you can check your instance health through the CloudWatch dashboard, you’re not expected to sit there watching it 24/7. That’s why status check alarms come in to make life easier. By tying CloudWatch alarms to these checks, you can set things up so that if a status check fails, AWS will automatically reboot the instance for you. This way, your production app recovers quickly without requiring constant manual intervention.
Why Reboot Works Best for Status Check Failures?

Rebooting an EC2 instance is usually the quickest and easiest way to fix a status check failure. Many of these issues, such as temporary OS glitches, stuck processes, or minor network issues, can often be resolved simply by restarting the instance. A reboot resets the instance’s software and networking stack, quickly getting it back to a healthy state without requiring complex troubleshooting. AWS documentation also highlights that using a reboot through a status check alarm is the recommended approach when an Instance Health Check fails. By automating this process, you can ensure your instance recovers quickly, minimizing downtime and removing the need to actively monitor it.
Step-by-Step Guide to Setting Up a Status Check Alarm
In this section, we’ll walk through a step-by-step guide to creating a status check alarm in CloudWatch. For this example, we’ll use an EC2 instance that has experienced an Instance reachability check failure, showing how you can automatically reboot the instance whenever a status check fails.
Step 1: Navigate to the “Create Status Check alarm” button
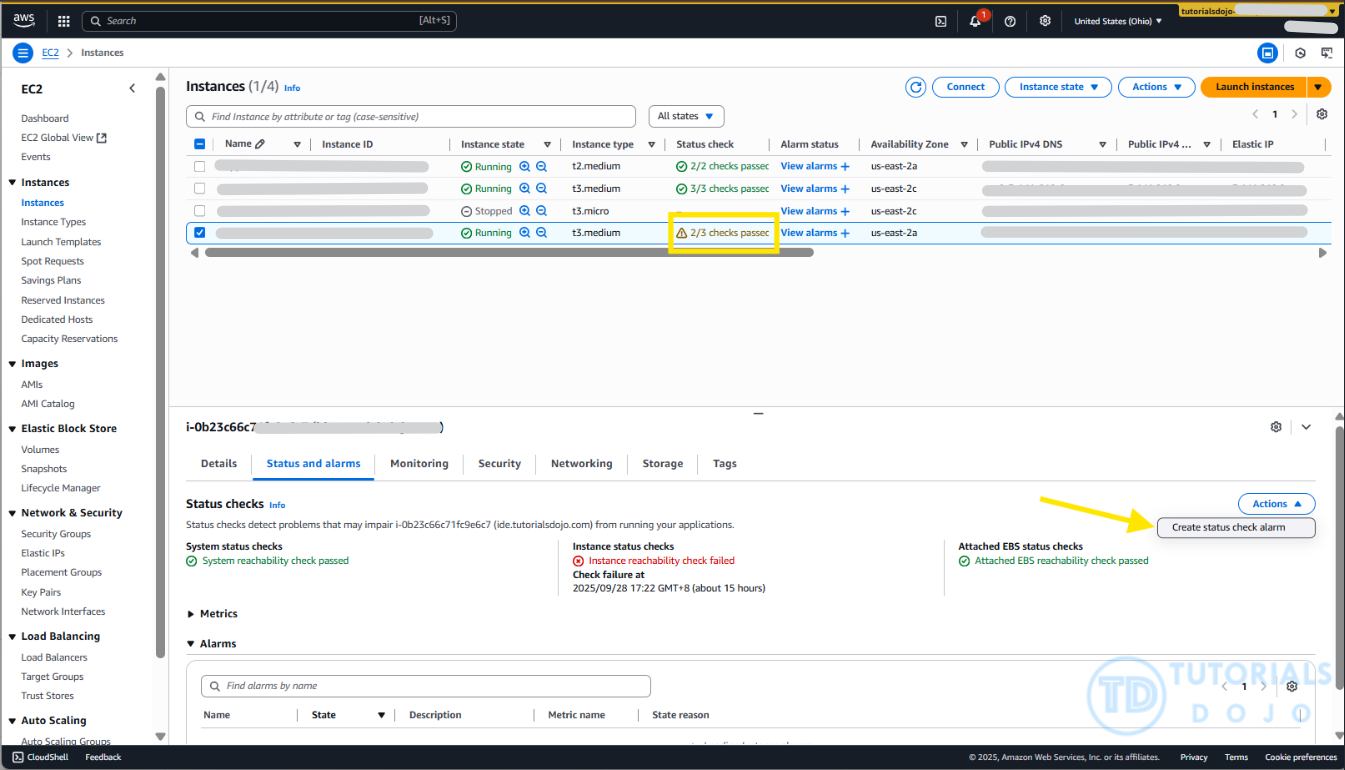
- On the Amazon EC2 console, select your EC2 instance.
- Click the “Status and alarms” tab.
- Click Actions, then select “Create status check alarm”.
Step 2: Configure the alarm conditions
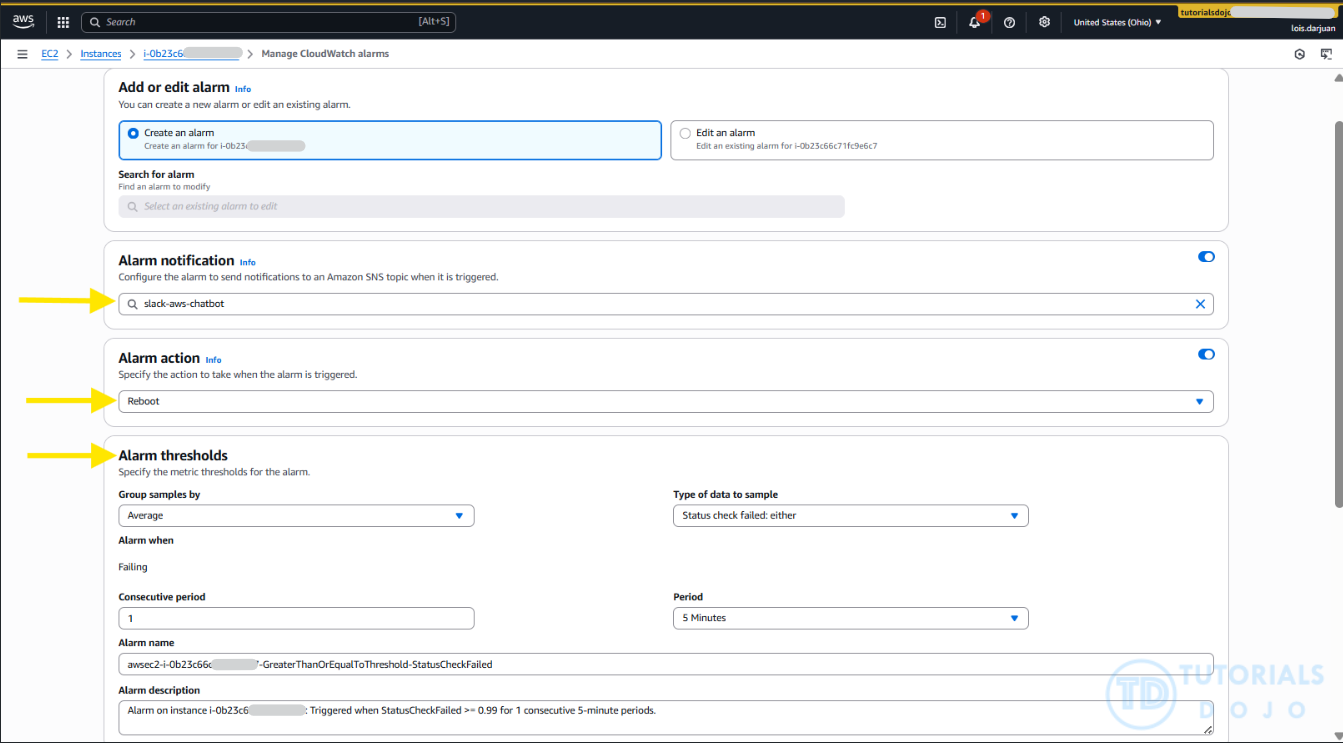
Set the following configurations:
- Select “Create an alarm”
- Alarm Notification – Set your custom SNS
- Alarm action – Reboot
- Alarm Threshold:
- Group samples by: Average
- Alarm when: Failing
- Consecutive period: 1
- Type of data to sample: “Status check failed: either”
- Period: 1 minute (can be adjusted based on your preference)
- Enter your preferred alarm name and description
- Once done, click Create
Step 3: Verify if the CloudWatch alarm is working
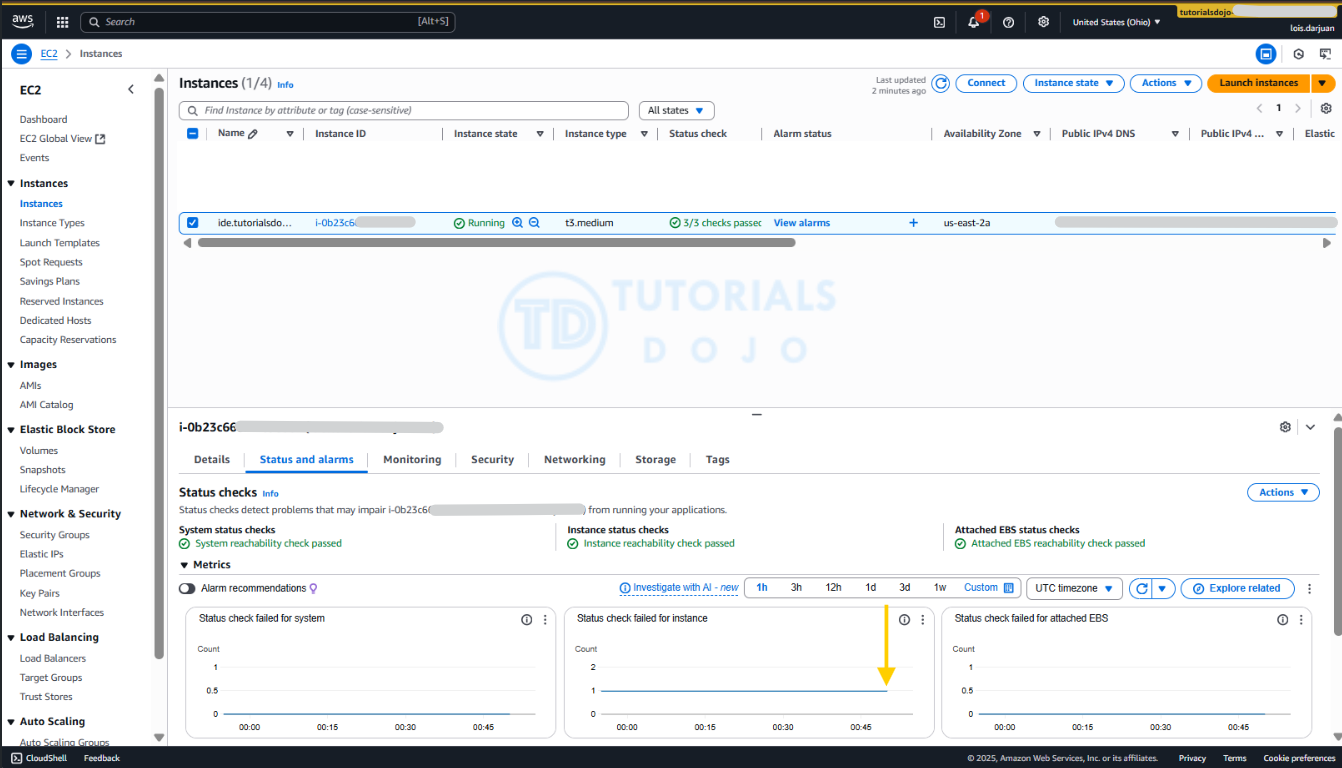
- Check if the instance reboots after the period you configured in the alarm conditions. As shown in the image above, the EC2 instance was successfully rebooted (highlighted by the yellow arrow, where the “status check failed for instance” and other metrics temporarily stopped updating), and it now passes all checks, including the previously failed “Instance reachability check”.
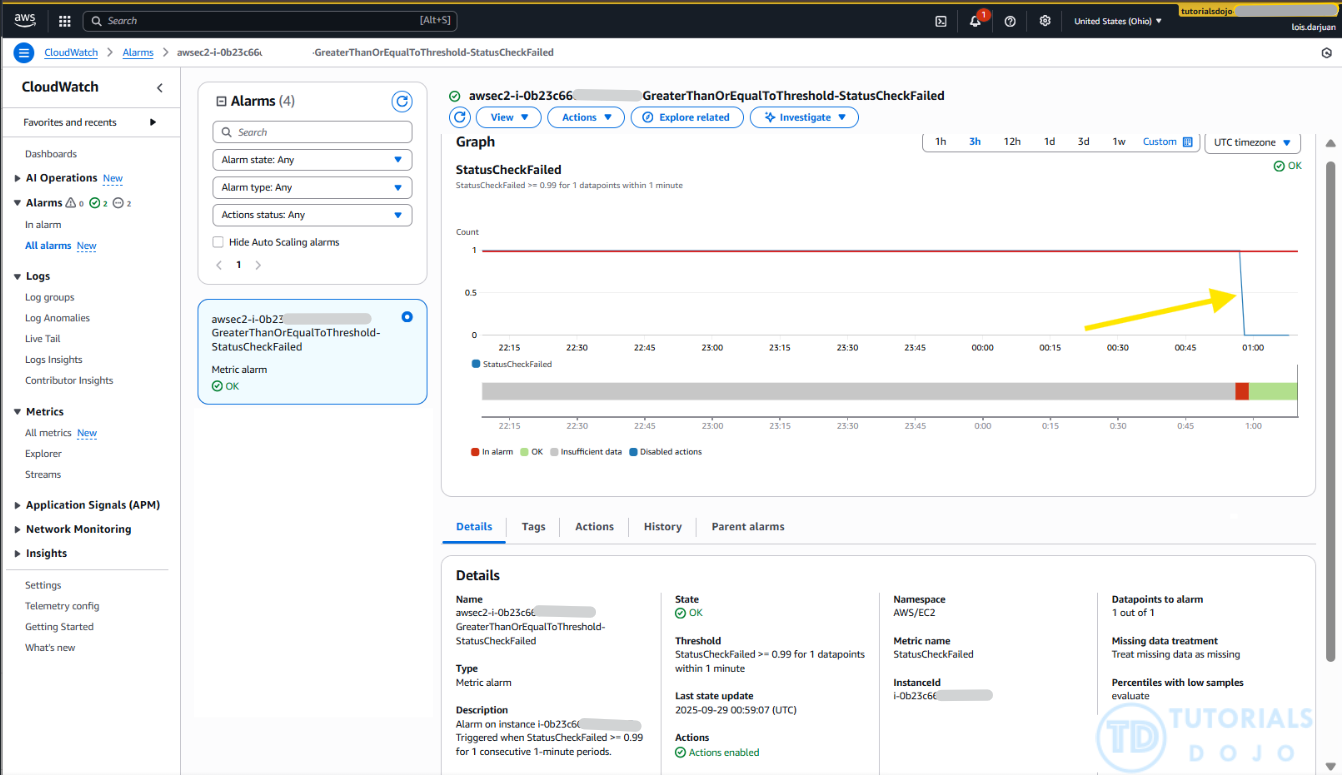
- You can also check the alarm in CloudWatch. In the image above, the
StatusCheckFailedmetric, previously at 1, suddenly drops to zero when the EC2 instance is rebooted. This shows that the CloudWatch alarm triggered the auto-reboot, fixing the failed status check.

Conclusion and Future Improvements
You didn’t expect it to be that easy, right? Setting up a CloudWatch status check alarm to automatically reboot your EC2 instance is actually straightforward, and it can save you a lot of hassle. With this setup, temporary issues like OS glitches, stuck processes, or minor network problems are handled automatically, so your instance recovers quickly without you having to watch it all the time.
Of course, there’s always room to make it even better. You could add notifications either through an SNS topic in the alarm itself or by using a Lambda action to let you know whenever an instance is down and is being rebooted. You could also track failure patterns with automated logs to identify recurring issues, or combine multiple alarms for more advanced recovery actions across different instances. These enhancements give you greater visibility and control, helping you stay on top of your infrastructure while keeping manual intervention to a minimum.
References:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/monitoring-system-instance-status-check.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/UsingAlarmActions.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-alarms.html
🌸 25% OFF All Reviewers on our International Women’s Month Sale! Save 10% OFF All Subscriptions Plans & 5% OFF Store Credits/Gift Cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





