We often hear about Large Language Models, but did you know that there’s a “smaller” version of it? In this article, we will talk about what a Small Language model is, their strengths and weaknesses, and its practical use cases. So, what really is a Small Language Model? At its core, an SLM is a lightweight language model designed specifically for task-specific, highly efficient inference. It is built on the exact same transformer foundations as the Large Language Models (LLMs) we are familiar with, but it’s built with a completely different philosophy. To clarify: an SLM is not simply “a smaller LLM.” While technically they share the same architecture (such as GPT, encoder-only, seq2seq, etc. ), SLMs are heavily optimized for speed, cost, and efficiency in environments where compute is severely constrained. When we look at the architecture of SLMs, they generally have: A lower parameter count: We are talking anywhere from a few hundred million up to the low, single-digit billion parameters (~ 350M – 4B or up to 10B if we stretch the definition). The honeymoon time is gone. We have to actually pay for LLMs now, and the free-tier stuff is drying up. The surge in SLM popularity is directly tied to the rising infrastructure costs of LLM deployment. If you are trying to build a sustainable business, you need models that are efficient and cheap enough to run at scale. This has created a massive demand for real-time, low-latency AI that can handle private inference without breaking the bank. The advantages are clear: Therefore, the rise of SLMs is really the combination of practical engineering needs meeting an industry-wide shift toward efficiency. Where good enough is a business metric and experimental is out of the picture. There is a misconception that SLMs are just weaker, less capable LLMs.But you have to understand that the goals are completely different. LLMs are general-purpose. They are the Swiss Army knives of Generative AI they can code, write stories, and talk to people about fluently. SLMs, on the other hand, are use-case specific. As they are designed to be highly specialized. In the engineering world, capability does not equal usefulness in production. You can’t cram everything into a small package, so SLMs give up general knowledge to be incredibly good at one specific thing. Because of this, an SLM can actually outperform an LLM in specific scenarios that it was explicitly meant to do. It will be the best at its specific job, and it will just suck at the rest. That sounds like a disadvantage however good engineering means negotiating around constraints, and being aware of the design envelope. Let’s look at an example: Liquid AI’s LFM2.5-350M. This is a perfect case study of what a modern SLM looks like. Specs: Comparing it against LLM sounds very unfair, because it is like comparing a speck of sand to a stone. But as they say, nothing is so big that it hurts the eyes. Local inference on MacBook M2 These optimizations make it possible to deploy models on local machines with no code configuration, thanks to LM Studio, which supports CPU, GPU, and Apple Metal inference. These compute optimizations improve performance while reducing overall operational costs, with minimal impact on performance. When you actually put these models head-to-head, the efficiency of a purpose-built SLM becomes incredibly obvious. On-Device Intelligence: This is AI running locally without any cloud dependency. SLMs fit perfectly here because they offer incredibly low latency and are inherently privacy-preserving. Because the model doesn’t need an internet connection, the “thinking” happens entirely on your device, not on a server halfway around the world. Tool Calling and Structured Tasks SLMs are fantastic for agentic usage where predictable outputs favor smaller models. If you need a model to do one thing and use tools to do it, SLMs are your go-to. Examples include: Narrow Chatbots (Primary Focus): These are domain-specific conversational systems. Think of a customer service bot focused entirely on your specific product. In this arena, SLMs actually outperform LLMs in: Of course, SLMs are not a silver bullet. We have to acknowledge their limitations: Performance can drop outside the model’s trained domain, sometimes in unpredictable ways. When pushed beyond its intended scope, results become less reliable. These are inherent design trade-offs; general knowledge is reduced in exchange for speed, cost, and efficiency. Guardrails and validation layers remain essential to keep outputs consistent and safe. Learn more about why AI Alignment is Hard. So, how do we actually build with this? Modern systems present a layered view of the AI stack: The key insight here is that modern systems combine both rather than choosing one. You don’t have to pick between SLMs and LLMs. By using SLMs on the front lines, you enable truly scalable, production-grade AI that performs beautifully without burning through your budget.

What are Small Language Model (SLM)?
Why Are SLMs Gaining Attention Right Now?

So Are SLMs Just Smaller LLMs?
Case Study: LFM2.5-350M
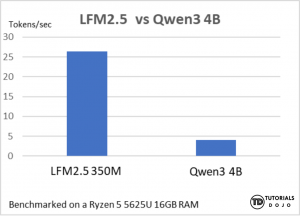
Quick benchmark LFM2.5 vs Qwen 8B performance
Limitations of SLMs

Where SLMs Fit in the AI Stack
🤖 $3.49 eBooks Start Here – Get Up to 30% OFF All AI & Machine Learning Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin


Vince is a BSIT student, academic researcher, and advocate for diversity and inclusion within the technology sector. She brings a diverse portfolio of experience spanning IT infrastructure management, compliance, security consulting, and systems evaluation. Her professional background includes work on industrial machine programming, software assessment, and IT operational support. In addition to her technical pursuits, Vince has led operations for AWS BuildHers+ PH, and presented award-winning research at academic conferences. She remains committed to fostering safer, more inclusive environments that empower diverse talent to succeed in the technology industry.



