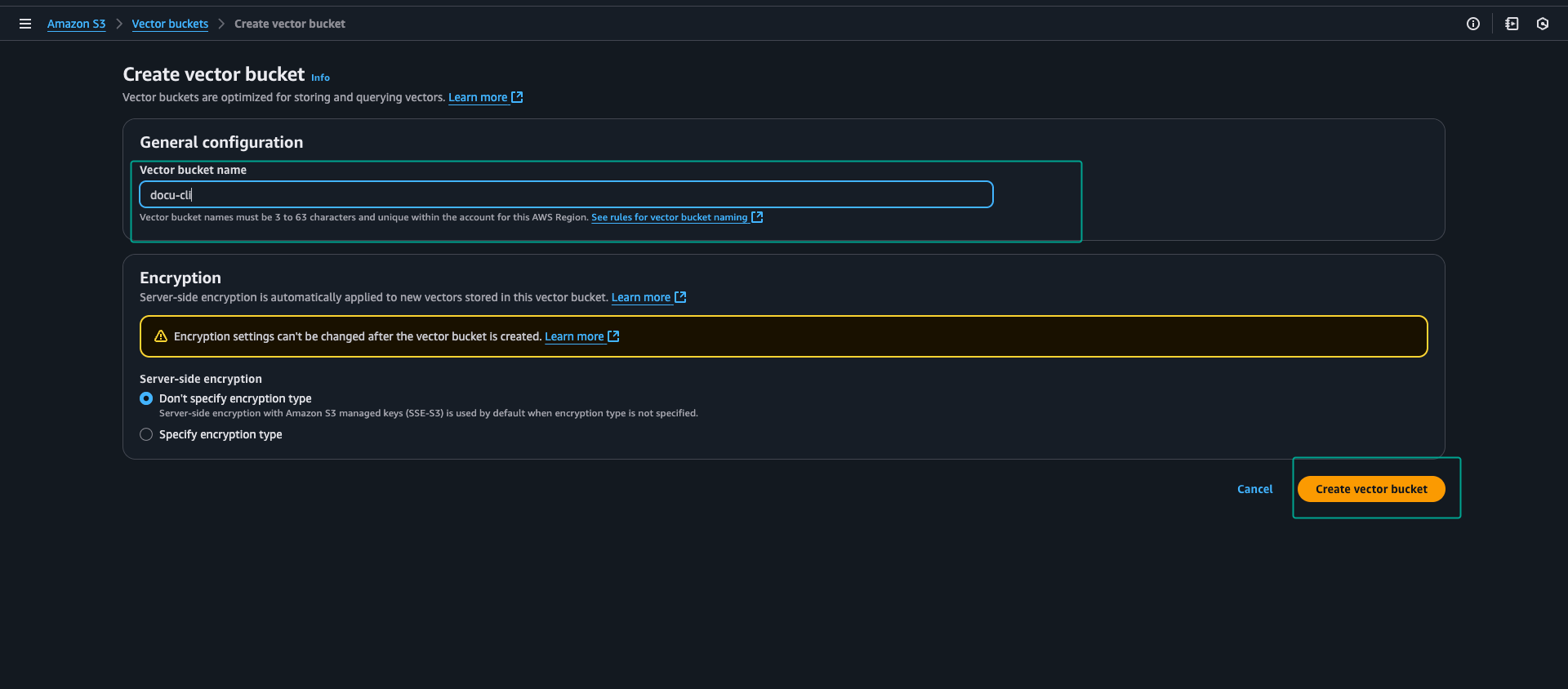
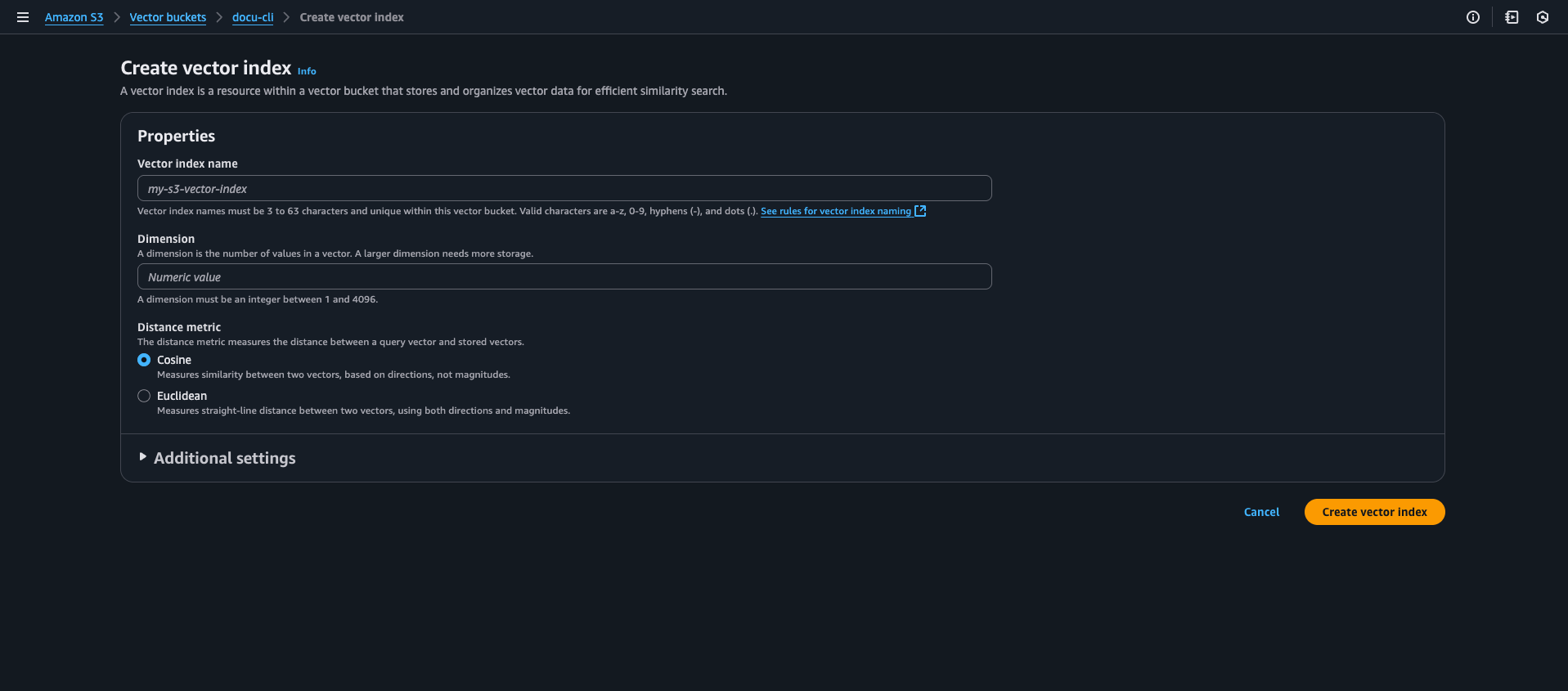
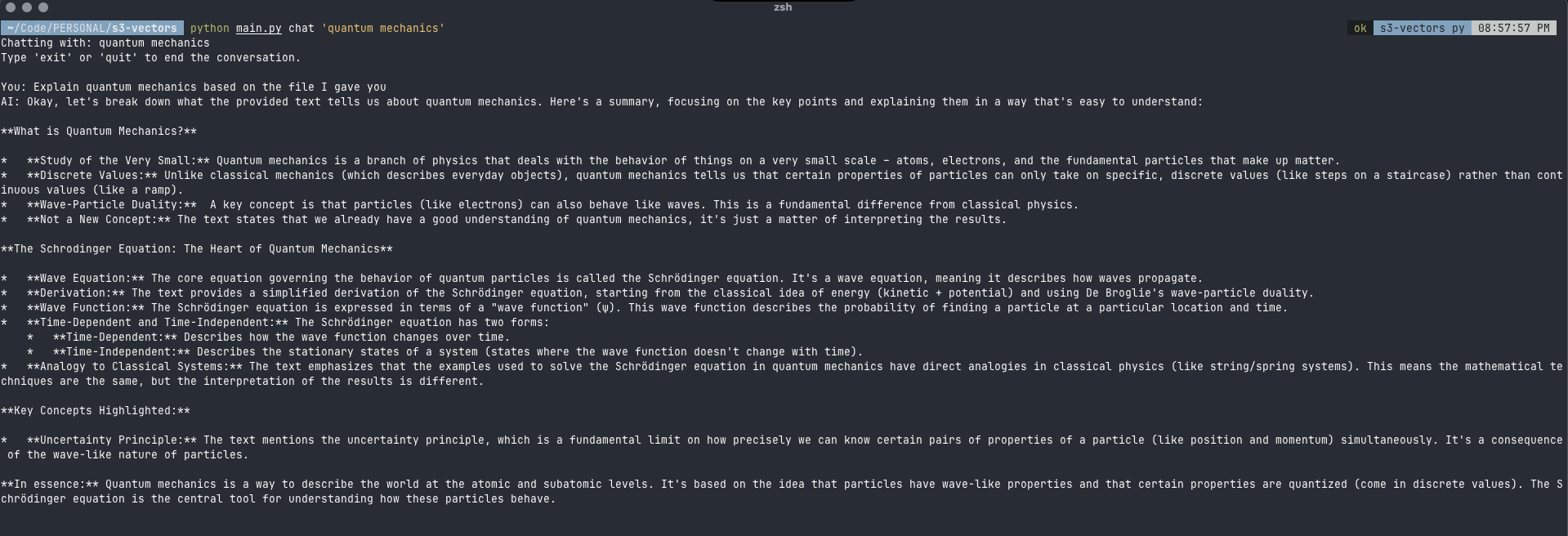
The world of generative AI is evolving at a rapid pace and one of the most powerful and practical applications is Retrieval-Augmented Generation (RAG). RAG enhances Large Language Models (LLMs) by giving them access to external, up-to-date knowledge bases. This allows them to generate more accurate and context-aware responses. Traditionally, building a RAG system required setting up and managing a separate vector database that adds complexity, cost, and a new layer of infrastructure to maintain however with the introduction of Amazon S3 Vector Buckets a new paradigm has emerged: zero-infrastructure vector search. Amazon S3 is a highly scalable, durable, and cost-effective object storage service.With its new native vector support (preview), S3 is no longer just a passive data lake. It now functions as a serverless vector search engine. This means you can store, index, and query vector embeddings directly in your S3 buckets, eliminating the need for a separate and dedicated vector database. The key benefits of this approach are: This makes S3 Vectors an ideal solution for RAG applications that don’t require millisecond-level latency and can tolerate sub-second query performance in exchange for significant cost savings and operational simplicity. Head over to S3 in the AWS Console: Once you are logged in, navigate to the S3 service. Find the Vector Buckets tab: In the left-hand navigation pane, find and click on Vector Buckets. Create a Vector Bucket: In the dashboard, click on Create vector bucket. Give your bucket a unique name and click Create. You can leave the other settings as their defaults for this example. A vector index is a resource within a vector bucket that stores and organizes vector data for efficient similarity search. Each index can store vectors at scale and supports metadata filtering to refine search results. Vector indexes are purpose-built for: Cost-effective storage of large vector datasets Similarity queries Metadata filtering during queries Integration with Amazon Bedrock Knowledge Bases and Amazon OpenSearch Service When creating a vector index, you specify: Distance metric (Euclidean or Cosine) for measuring similarity. Number of dimensions for vectors. Optional non-filterable metadata keys. Each vector in an index consists of: A unique vector key The vector data Optional metadata (up to 40 KB per vector, with 2 KB limit for filterable metadata) Writes to vector indexes are strongly consistent, ensuring that subsequent queries include the most recently added data. You can attach metadata to vectors to filter future queries based on conditions like dates, categories, or user preferences. You can use bucket policies to grant or restrict access to specific indexes and vectors within your vector bucket. To create a vector index in the console, find the Vector indexes section and click Create vector index. Properties Vector index name: The name must be 3 to 63 characters and unique within this vector bucket. Valid characters are a-z, 0-9, hyphens (-), and dots (.). Dimension: A dimension is the number of values in a vector. A larger dimension needs more storage. A dimension must be an integer between 1 and 4096. Distance metric: The distance metric measures the distance between a query vector and stored vectors. Cosine: Measures similarity between two vectors, based on directions, not magnitudes. Euclidean: Measures straight-line distance between two vectors, using both directions and magnitudes. This practical example is a command-line interface (CLI) application that demonstrates a complete, end-to-end RAG workflow. It showcases how to leverage the new S3 Vector Buckets as a serverless vector store eliminating the need for a separate database. The script handles the entire process, from parsing PDFs and creating vector embeddings with a local model to storing those embeddings in S3 and then querying them to generate context-aware responses. This provides a clear runnable blueprint for building a scalable and cost-effective RAG solution. The following Python script demonstrates how to build a simple, local RAG application that leverages Amazon S3 Vectors. It uses Ollama for running the embedding and chat models locally, and the Learn More About Amazon S3 Vector

What is Zero-Infrastructure Vector Search?
Create a Vector Bucket and Understand Vector Indexes
Vector Indexes

Demo Time!
boto3 library to interact with the S3 Vectors API. This provides a powerful, scalable, and cost-effective way to build production-ready RAG applications.
📚 $0.99 eBooks Start Here – Up to 80% OFF All Products Mid-Year Sale Extension!

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin


Rafael Louie Miguel, also known as Kuya Egg, is an AWS Certified Cloud Practitioner and Certified Solutions Architect Associate. An intern at Tutorials Dojo. He serves as the Director of Technology at AWS Cloud Club PUP, the first AWS Cloud Club in the Philippines. He is an undergraduate at the Polytechnic University of the Philippines currently pursuing a Bachelor’s degree in Information Technology.



