Last updated on February 2, 2026
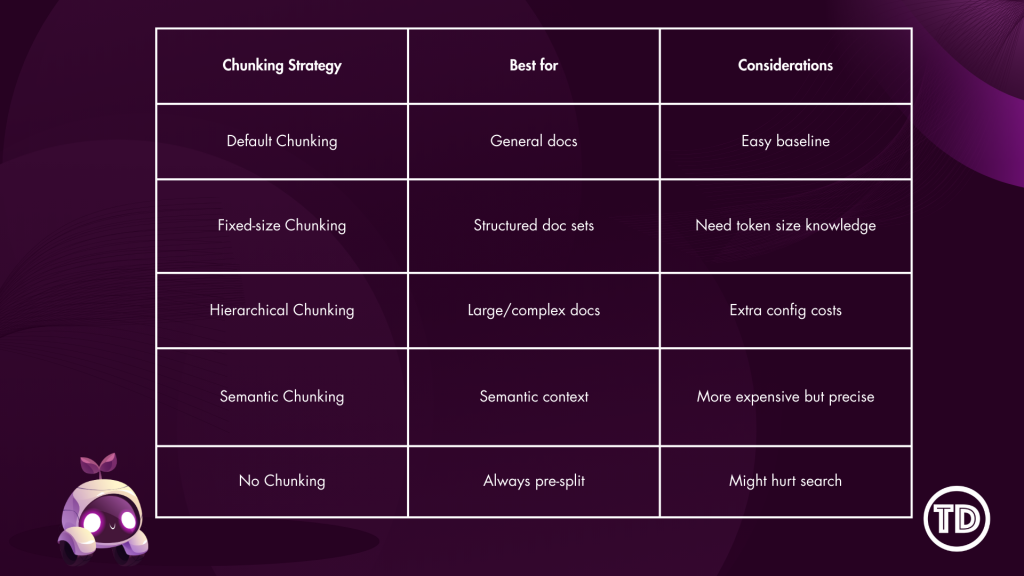
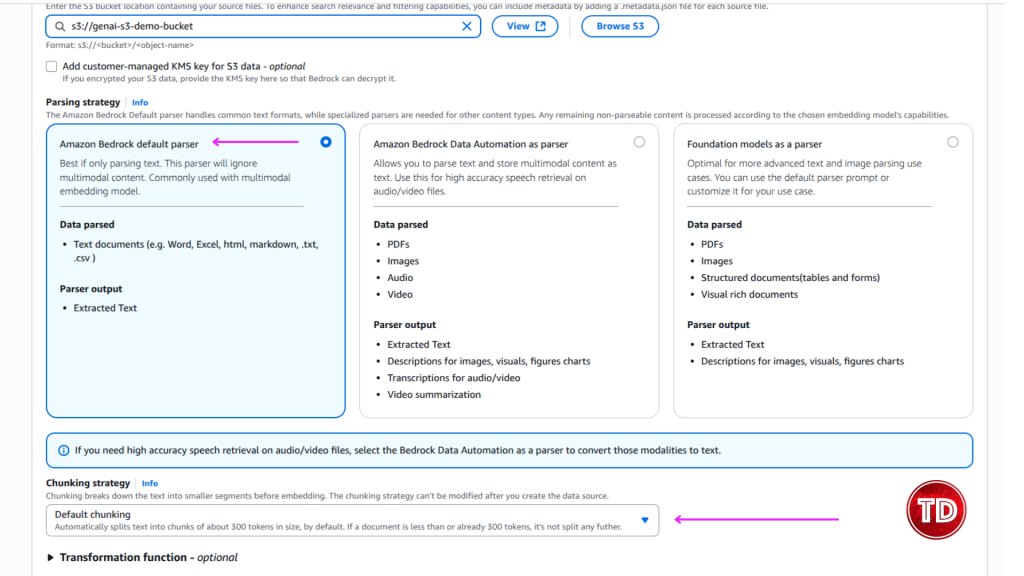
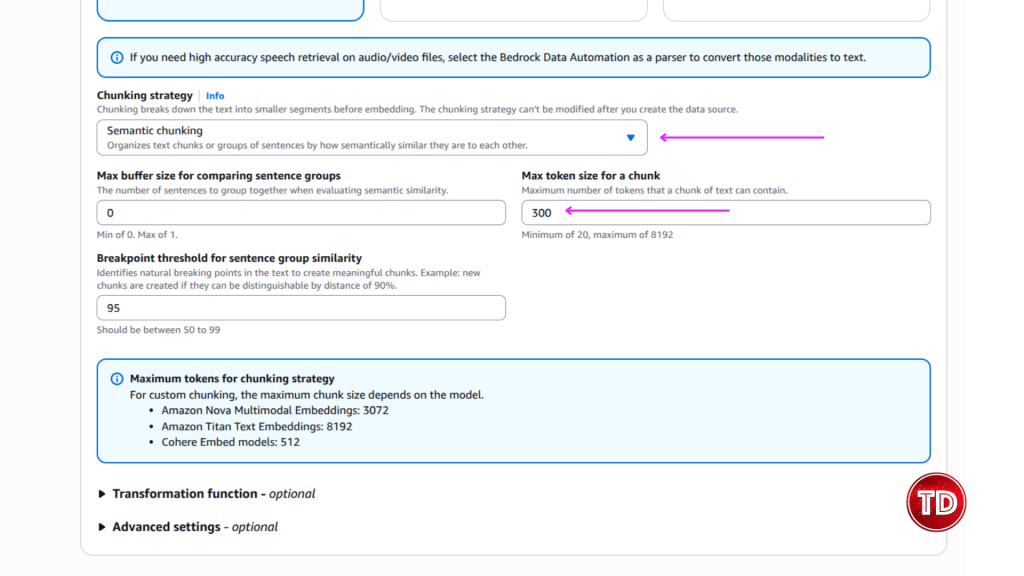
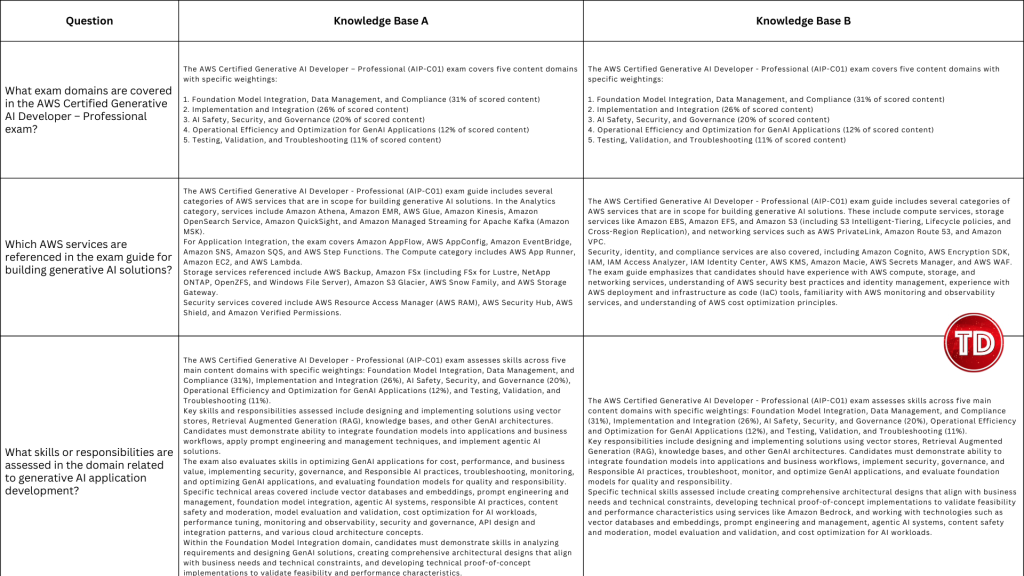
Modern generative AI systems often appear to “read” entire documents instantly, returning precide answers form long PDFs or dense technical manuals. In reality, large language models do not consume documents holistically. Instead, they rely on carefully prepared context that is retrieved and supplied at query time. One of the most critical and often misunderstood mechanisms behind this process is content chunking. At its core, content chunking determines how raw documents such as PDFs, webpages, or text files are transformed into smaller, meaningful units that can be indexed, embedded, and retrieved efficiently. Understanding how chunking works and how to configure it correctly is essential for building high-quality Retrieval-Augmented Generation (RAG) applications on Amazon Bedrock. In this article, we’ll walk through: Before diving deeper, it’s useful to briefly introduce a few key concepts that frequently appear in this discussion: Although all of these components work together, the primary focus of this article is content chunking, specifically within Amazon Bedrock Knowledge Bases. Content chunking is the process of dividing large documents into smaller, meaningful segments—called chunks—before those segments are embedded and stored in a vector index. Instead of embedding an entire document as a single unit, Bedrock embeds each chunk independently, enabling fine-grained semantic search. Chunking happens early in the RAG pipeline—transforming raw data sources into smaller segments before they’re embedded and stored for retrieval. A useful analogy is a technical reference book. When searching for information about a specific configuration or concept, you do not reread the entire book; you locate the relevant section or paragraph. Chunking allows Bedrock to perform this same operation at scale. Each chunk represents a self-contained unit of meaning that can be retrieved independently, improving both accuracy and efficiency. Chunking is especially important because vector search systems operate under token limits and similarity thresholds. Large documents are inefficient to embed and difficult to retrieve accurately. By breaking content into manageable units, chunking reduces retrieval noise, isolates context, and enables precise matching between user queries and relevant source material. In Amazon Bedrock Knowledge Bases, chunking occurs before embeddings are generated, which means the chosen strategy has a direct and lasting impact on retrieval quality, latency, and cost. Amazon Bedrock provides multiple built-in chunking strategies designed to support document structures and use cases. The default chunking strategy is a general-purpose option that splits content into chunks of approximately 300 tokens while preserving sentence boundaries. For many workloads—such as FAQs, internal documentation, and blog-style content—this strategy offers a strong balance between simplicity and effectiveness, making it an excellent starting point for prototyping. Fixed-size chunking offers more control by allowing you to specify the maximum number of tokens per chunk and define overlap between adjacent chunks. Overlap can help preserve context across boundaries, which is particularly useful for structured documents like policy manuals or technical guides where concepts span multiple paragraphs. Semantic chunking takes a different approach by focusing on meaning rather than size. Instead of splitting text based on token counts, this strategy uses semantic similarity to determine logical breakpoints. Sentences or paragraphs that are closely related are grouped together, while topic shifts trigger new chunks. This approach is especially effective for long-form or concept-dense documents such as legal agreements or research materials. Because semantic chunking relies on foundation models, it is more computationally expensive, but it often produces higher-quality retrieval results. Hierarchical chunking introduces a two-level structure consisting of smaller child chunks and larger parent chunks. During retrieval, Bedrock first identifies the most relevant child chunks and then replaces them with their corresponding parent chunks to provide broader context. This strategy is well suited for large documents with clear structural organization, where both precision and contextual completeness are important. Finally, Bedrock supports a no-chunking option, in which each document is treated as a single chunk. This approach is only appropriate for small or pre-segmented documents and is generally not recommended for production RAG systems. Not sure which chunking strategy to use? Here’s a quick cheat sheet to help you decide! For this test, I used the AWS Certified Generative AI Developer – Professional Exam Guide. This document includes well structured sections, bullet points, and formal language, making it an ideal candidate for analyzing how structural preservation impacts downstream performance. I uploaded this document to S3 bucket. Knowledge Base A: Default Configuration Knowledge Base B: Advanced Configuration We tested both Knowledge Bases: Knowledge Base A (with Bedrock Default Parser / Default Chunking) and Knowledge Base B (with Bedrock Default Parser / Semantic Chunking), by asking same questions. Below are a few samples: Amazon Bedrock’s default configurations provide a solid foundation for early experimentation and prototyping. As RAG applications evolve toward production, however, fine-tuning Knowledge Base settings becomes increasingly valuable. I focused this experiment on Chunking but, there are additional configurations to explore as well. It is worth noting that Amazon Bedrock offers additional configuration options that can further influence retrieval quality and system behavior. Achieving optimal RAG performance is iterative process. While this experiments highlight the importance of effective chunking, every implementation requires fine-tuning to match its specific needs. The relevance of retrieved context has a direct impact on the accuracy of generated responses, so continuous testing, evaluation, and refinement are essential to achieving reliable results.

Understanding Content Chunking and Why It Matters
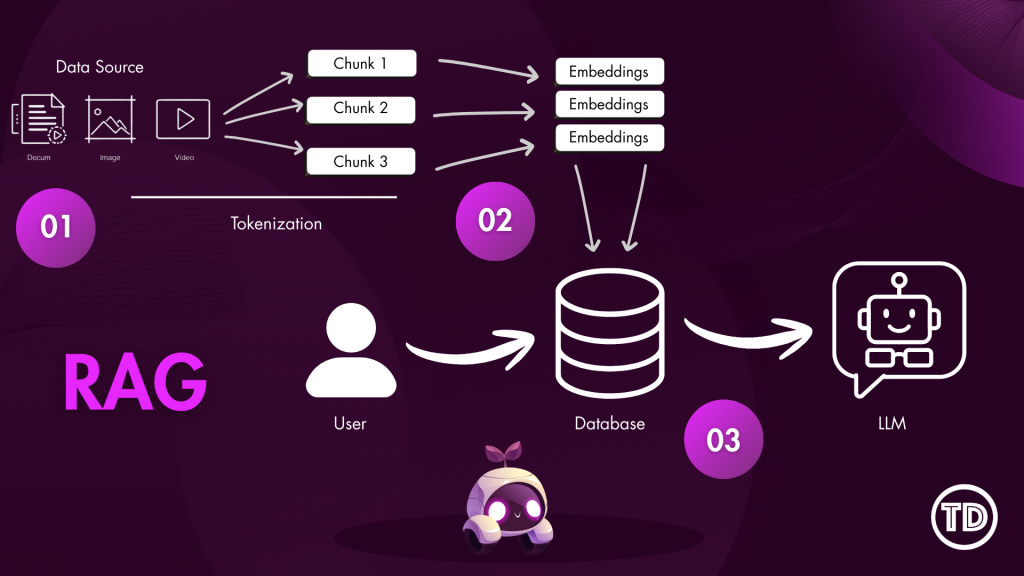
A Visual Guide To Chunking Strategies and How it Works
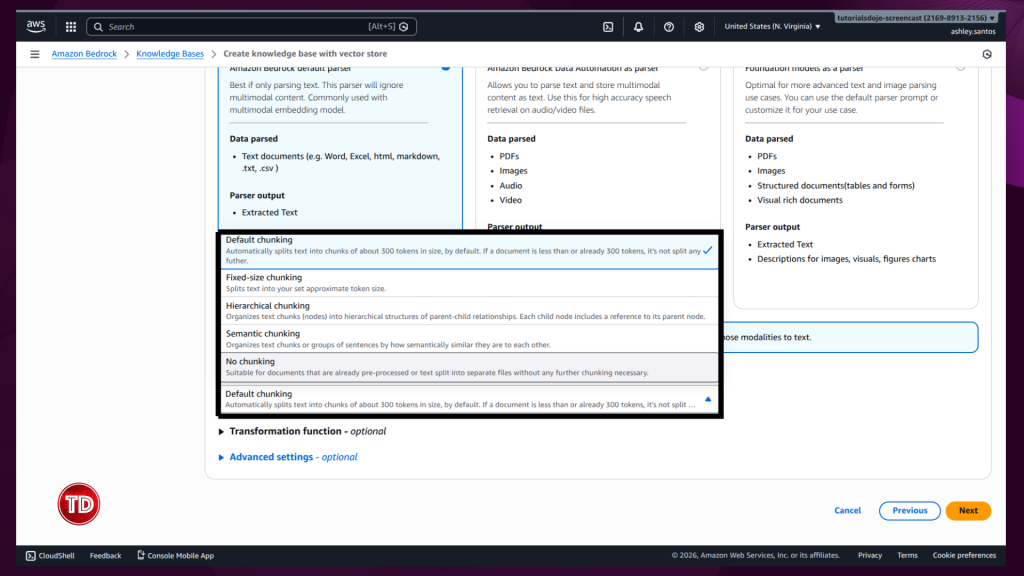
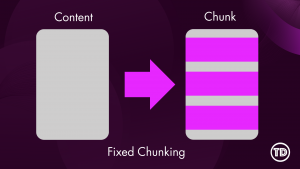
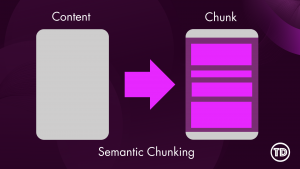

Chunking Strategy Cheat Sheet: Quick reference for choosing the right approach for your use case
Document Used For Testing

Questions and Findings
Final Thoughts
Key Takeaways for Implementation
References:
🔥 $0.99 eBooks Start Here – Up to 80% OFF All Products Mid-Year Sale!

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





