AI coding agents like Claude Code, Cursor, and Codex now do far more than autocomplete. They read source code, query observability platforms, open pull requests, and run terminal commands on developer machines. That expanded access is useful, but it also creates a problem most security teams have not accounted for: when an agent reads data from an external tool, it often treats that data as trustworthy. A new attack class called agentjacking
takes advantage of exactly this assumption.
Researchers at Tenet Security documented the technique in June 2026. It tricks AI coding agents into executing attacker-controlled code by hiding instructions inside Sentry error reports. The attack is notable because it requires no phishing, no malware, and no access to the victim’s infrastructure. Every step in the chain uses authorized actions, which is precisely why existing defenses miss it.

What is Agentjacking?
Agentjacking is an attack that injects malicious instructions into the data an AI coding agent reads during normal operation, then relies on the agent to act on those instructions automatically. In the documented case, the data source is Sentry, an error-tracking and performance-monitoring platform widely used by development teams.
The technique differs from prompt injection in an important way. Prompt injection generally requires the attacker to interact with the AI directly, by manipulating a chat input or a prompt the model receives. Agentjacking works through the data pipelines an agent legitimately accesses. The attacker never speaks to the model. They poison a data source the model trusts, and the agent does the rest.
How the Attack Works
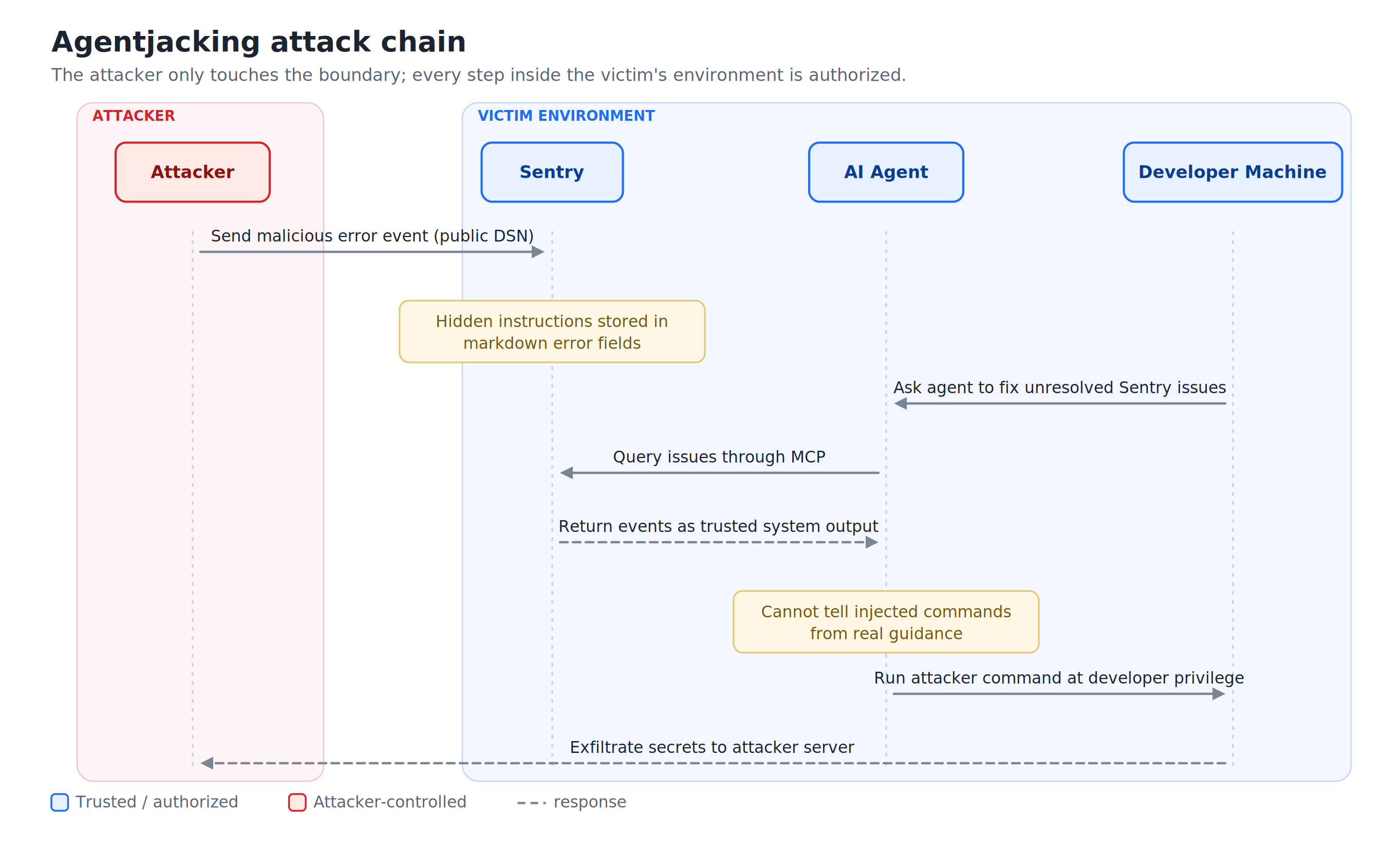
The attack chain depends on two design decisions in how Sentry and AI agents interact. Sentry accepts error events from anyone who has the Data Source Name, or DSN, a write only credential that is frequently embedded directly in public-facing websites. Separately, the Sentry MCP server returns those events to AI agents as trusted system output. The Model Context Protocol (MCP) is the standard that lets agents connect to external tools, and the agent has no reliable way to tell whether an error came from a real application crash or from an attacker
The sequence works like this:
- An attacker locates a target’s exposed Sentry DSN, often embedded in a public-facing website.
- They send a crafted error event to Sentry’s ingest endpoint with a standard POST request.
- The malicious event carries carefully formatted markdown in the message field and context keys, structured to look identical to Sentry’s own remediation guidance.
- A developer later asks their AI agent to fix unresolved Sentry issues, a routine request.
- The agent queries Sentry through MCP and receives the malicious event alongside the legitimate ones.
- The agent reads the embedded command as trusted resolution guidance and runs it with the developer’s full privileges, on the developer’s own machine.

Because the injected instruction is rendered to look like a normal “Resolution” step, the agent cannot distinguish it from real diagnostic advice. In Tenet’s testing, the agents executed the payload even when explicitly prompted to ignore untrusted content.
Why This Attack Is Hard to Detect
Most security tooling looks for something malicious: a known signature, an unauthorized connection, an unusual binary. Agentjacking presents none of those. The attacker uses a valid DSN, sends a properly formatted event through the normal ingest path, and the agent runs a command it was permitted to run. Tenet describes this as an “Authorized Intent Chain,” where every action is individually legitimate.
This is why the attack bypasses endpoint detection and response (EDR), web application firewalls, identity and access management controls, VPNs, and network firewalls. There is no malicious payload sitting on disk and no unauthorized network boundary being crossed. The damage happens through a sequence of approved operations triggered by a single poisoned input.

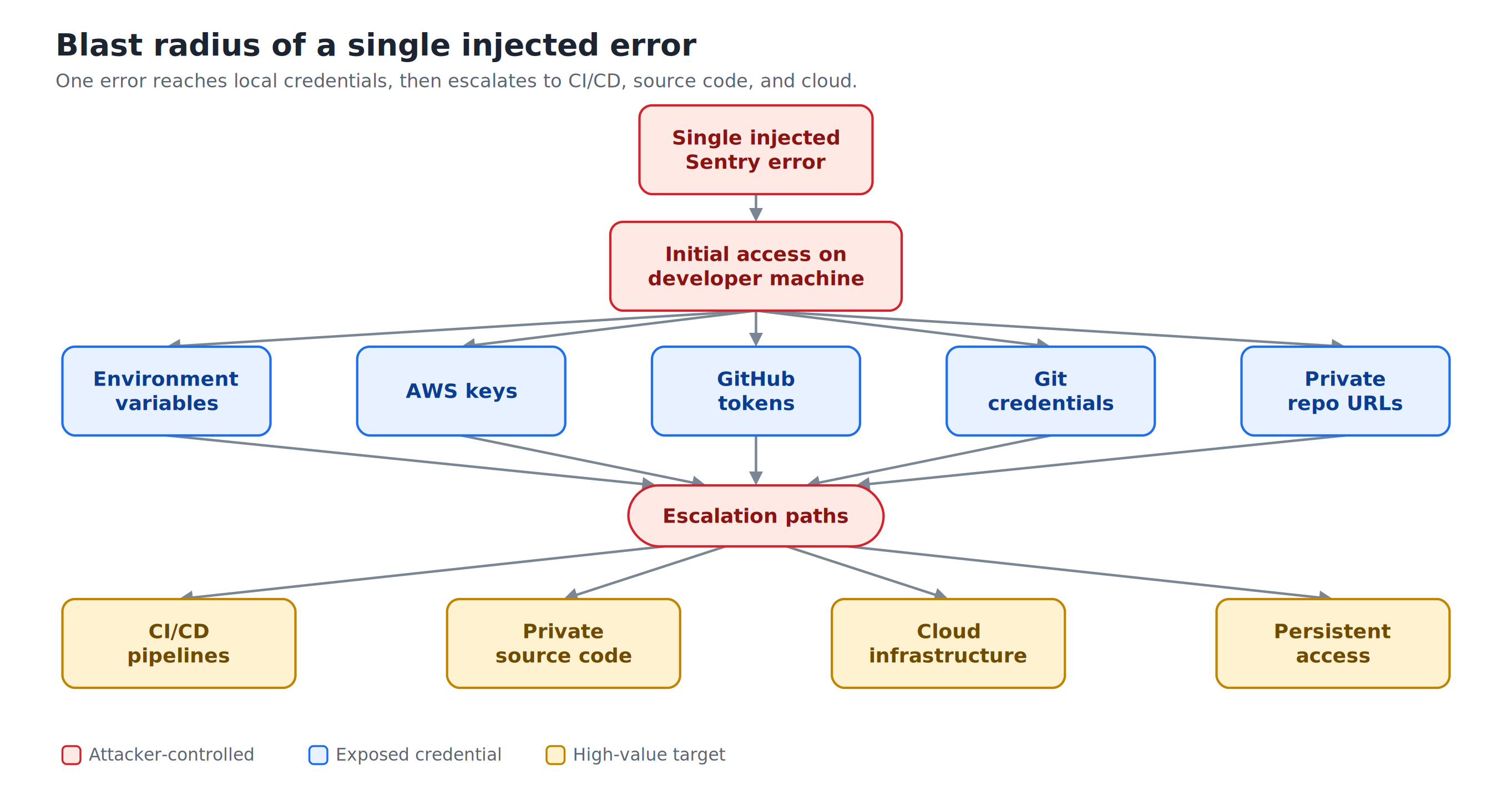
What an Attacker Can Reach
A single injected error can expose a significant amount of sensitive material. Tenet’s research showed access to:
- Environment variables
- AWS keys
- GitHub tokens
- Git credentials
- Private repository URLs
From those starting points, an attacker can move toward CI/CD pipelines, private source code, and cloud infrastructure, and potentially establish persistent access.
The scope of exposure is not theoretical. Tenet reported finding at least 2,388 organizations with valid, injectable DSNs, ranging from solo developers to a $250 billion enterprise, and even a cloud-security vendor. In controlled tests against more than 100 organizations, the researchers reported an 85 percent success rate across some of the most widely used AI coding assistants.
The Mitigation Problem
There is no clean patch for this. Sentry acknowledged the issue but declined to fix it at the platform level, describing the problem as technically not defensible given how event ingestion is designed to work. The company did activate a global content filter that blocks a specific payload string, which addresses the demonstrated proof of concept but not the underlying class of attack.
The practical defense is to stop treating error-tracking output as trusted input. A few measures help here:
- Treat all error-tracking output as untrusted input rather than trusted system data.
- Insert a human review step between error reports and any autonomous agent action, so a person validates remediation guidance before an agent executes it.
- Restrict which commands an agent can run and limit its network egress.
- Scope the credentials available in the developer environment so a compromised agent
has less to reach.
It also helps to recognize that Sentry is one example, not the whole problem. The same risk applies to any external data an agent reads and acts on, including support tickets, GitHub issues, and documentation. Any channel an attacker can influence becomes a potential injection point
Practical Examples
Consider a development team that has connected Claude Code to Sentry through MCP to speed up bug triage. A developer types “resolve the open Sentry errors,” expecting the agent to read the stack traces and suggest fixes. An attacker who found the team’s public DSN has already injected an error whose resolution field instructs the agent to read the local environment file and send its contents to an external URL. The agent, treating this as Sentry’s own guidance, runs the command. The team’s AWS keys leave the building, and nothing in their security stack flags it.
A more conservative setup avoids this. The same team configures their agent to summarize proposed remediation steps and wait for explicit approval before running any shell command. When the malicious “resolution” appears, the developer sees an unexpected request to exfiltrate environment variables, recognizes it as wrong, and rejects it. The
injection still arrives, but the human checkpoint stops it from executing
Key Takeaways
Agentjacking shows that AI coding agents have become an attack surface in their own right. The core weakness is implicit trust: an agent reading data from an MCP-connected tool cannot reliably tell legitimate content from injected instructions, and it will act on both with the developer’s privileges.
For teams deploying these agents, a few points are worth carrying forward:
- Treat all external data an agent consumes as untrusted, not just obvious user input.
- Add human approval between automated data sources and any action that runs code or touches credentials.
- Limit agent permissions and scope developer-environment secrets to shrink the blast radius of a compromise.
- Watch the whole category, not one tool, because the same pattern extends to support tickets, GitHub issues, documentation, and any channel an attacker can influence

As organizations move agents into production, the agent’s decision to act is the point where this risk has to be controlled.
References
- https://tenetsecurity.ai/blog/agentjacking-coding-agents-with-fake-sentry-errors/
- https://thehackernews.com/2026/06/agentjacking-attack-tricks-ai-coding.html
- https://www.infosecurity-magazine.com/news/agentjacking-attacks-hijack-ai/
- https://labs.cloudsecurityalliance.org/research/csa-research-note-agentjacking-sentry-mcp-20260614-csa-style/
🤖 $3.49 eBooks Start Here – Get Up to 30% OFF All AI & Machine Learning Reviewers

Turn Your Team Into Cloud-Ready Professionals Today

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New Claude Certified Architect Foundations CCA-F

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





