Last updated on October 28, 2025
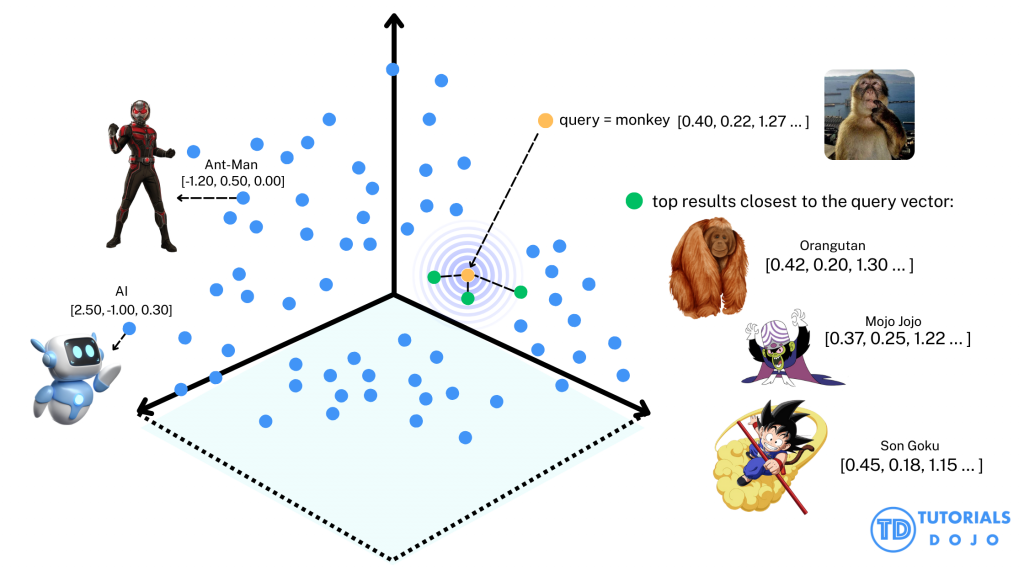
In today’s AI-driven world, finding information based on meaning and context rather than exact keywords has become crucial. Good thing we now have vector search, enabling semantic search, personalized recommendations, image similarity, and more. However, building and managing vector search infrastructure can be complex. Fortunately, AWS offers zero-infrastructure managed services that let you implement powerful vector search capabilities without worrying about servers, scaling, or maintenance. Let’s walk through creating a simple yet effective vector search demo using AWS services within the Free Tier so you can follow along without incurring costs. Vector search is a groundbreaking technique that converts data (text, photos, etc.) into high-dimensional vectors (numerical representations) that maintain the meaning and context. Instead of searching for exact keyword matches, vector search identifies items whose vectors are closest to the query vector, resulting in more intelligent, semantic search results. Imagine a world where you can search for documents not just by shared words but by shared concepts or ideas, or find images visually similar to another photo. Vector search is the key to unlocking this potential. Example of vector search: a query for ‘monkey’ retrieves the closest related vectors like Orangutan, Mojo Jojo, and Son Goku, while distant vectors such as Ant-Man and AI Bot are less relevant. How it works: Traditionally, building and maintaining vector search infrastructure requires a lot of technical proficiency and resources. To maintain high availability and security, you must solve scalability issues, configure highly complex databases, maintain specialized hardware, and continuously optimize performance. AWS removes these barriers by delivering managed services that handle the tedious backend tasks. Instead of dealing with infrastructure complexity, you can concentrate on developing intelligent applications like recommendation systems, image recognition, and natural language processing using this zero-infrastructure approach. Key benefits include: This approach democratizes advanced search technology, making it accessible to developers of all skill levels. It’s a progressive movement that includes everyone, while providing enterprise-grade performance and reliability. For this guide, we will be using three key AWS services to create our vector search system: With AWS Kendra’s free 30-day trial and the free tier limits of AWS SageMaker and S3, you can keep your experiments cost-free, making this setup powerful and a wise financial choice. Ensure you have an AWS Account to log in to the AWS Management Console. Begin by creating a small set of text files you’d like to search semantically (such as product descriptions, FAQs, or short articles). For this demo, I created 4 .txt files containing lines of information related to vector search. Log in using your AWS credentials at https://console.aws.amazon.com/. You’ll need a root or IAM user with sufficient permissions to use SageMaker, S3, and Kendra. Let’s head on over to Amazon SageMaker and convert our sample data into vector embeddings. It is recommended that you choose the Quick setup option when setting up your domain when you’re getting started with SageMaker. After running the code, your sample test should be converted into a vector embedding via a result showing the numerical representation of your data. Alright! Now we can add the folder that we made locally (Step 1) into the notebook and use this following code to convert them into vector embeddings: Then we can compile these embeddings and convert them into a single json file. You can also upload your embeddings directly to S3 by using this code: Now we can head on to Amazon S3 to store our data Let’s see if our Index is working properly. Well done! Using advanced vector search technology, you’ve successfully converted unstructured data into intelligent, searchable knowledge. You’ve generated embeddings, used Amazon Kendra to index them, and run semantic queries that can comprehend the intent behind your searches rather than just terms. What you’ve accomplished is no small feat: you’ve created a working zero-infrastructure vector search using AWS managed services, laying the groundwork for knowledgeable search applications. Now that you’ve successfully completed your demo and seen the power of vector search in action, you may want to clean up your AWS resources. Consider doing these after you’re done with your work to prevent any unexpected charges: Cleaning up is optional, but it keeps your AWS environment neat and helps keep costs under control, especially if you’re eager to keep playing with your new creation. Managing performance and costs effectively is crucial when deploying vector search solutions on AWS. Although AWS’s managed services handle complexity, optimizing performance and controlling expenses can elevate your application’s reliability and scalability. For example, choosing the right vector embedding size plays a significant role in performance. Faster searches are usually achieved with lower-dimensional embeddings without a considerable accuracy trade-off. Moreover, queries can be significantly accelerated while yielding pertinent answers using approximate nearest neighbor (ANN) search methods. Monitoring your AWS resources with CloudWatch allows you to monitor query latency, throughput, and usage patterns, helping you spot bottlenecks before they impact users. Batching updates and indexing operations can reduce overhead and improve efficiency when working with large or frequently updated datasets. Cost control is equally important. You can test stuff without paying for it if you stay inside the AWS Free Tier limits while developing. Don’t forget to remove Amazon Kendra indexes and terminate SageMaker endpoints when not in use. Storage considerations are also important. Amazon S3 is a very affordable way to store your data and embeddings, but you may further reduce costs by selecting the appropriate storage class and lifecycle policies. By balancing these performance and cost factors, you can create a robust, scalable vector search system that maximizes AWS’s cloud capabilities. Vector search transforms how organizations find, analyze, and leverage their data across industries. By understanding meaning rather than just matching keywords, AWS vector search enables semantic, AI-driven applications that deliver measurable business value. These instances show how AWS vector search isn’t a workable answer to business problems, rather than merely a theoretical concept. Vector search already demonstrates its value in increasing productivity, increasing customer happiness, and gaining a competitive advantage. And this is just the beginning; there are many more opportunities across industries when sophisticated search features are combined with AWS’s scalability and dependability. This article helps you overcome the traditional barriers by showing you how to build a powerful vector search engine with AWS’s free-tier resources, preventing you from learning more about this intriguing topic. By putting the cost and performance management techniques we’ve covered into practice, you can ensure your application expands without hiccups and remains user-responsive. The field of searching is shifting rapidly. Previously thought to be exclusive to tech giants, cutting-edge technology is now accessible to developers and companies of all sizes. Quickly, semantic and vector-based search features are no longer optional; people now demand intelligent, contextual search experiences that comprehend their meanings and their typing. AWS gives you the resources and infrastructure you need to fulfill these changing demands. Thanks to the foundation you have established today, you can develop applications that do more than search through data; they actually comprehend and relate to what people seek. Semantic search is the way of the future, and you now possess the abilities to contribute to this change. Ready to Take Your Vector Search Skills Further? While this guide gives you a solid foundation using the traditional approach with SageMaker, Kendra, and S3, AWS has recently introduced even more powerful capabilities. If you’re ready for advanced implementation patterns and want to leverage the latest Amazon S3 vector storage features for better performance and integration, check out the comprehensive guide on Zero-Infrastructure Vector Search with Amazon S3 Vectors. This advanced tutorial covers the newest AWS vector bucket capabilities and enterprise-grade optimization techniques that can take your semantic search applications to the next level. Semantic search is the way of the future, and you now possess the abilities to contribute to this change.

What is Vector Search?
Why Use Zero-Infrastructure Vector Search on AWS?
Step-by-Step Demo: Building Vector Search on AWS
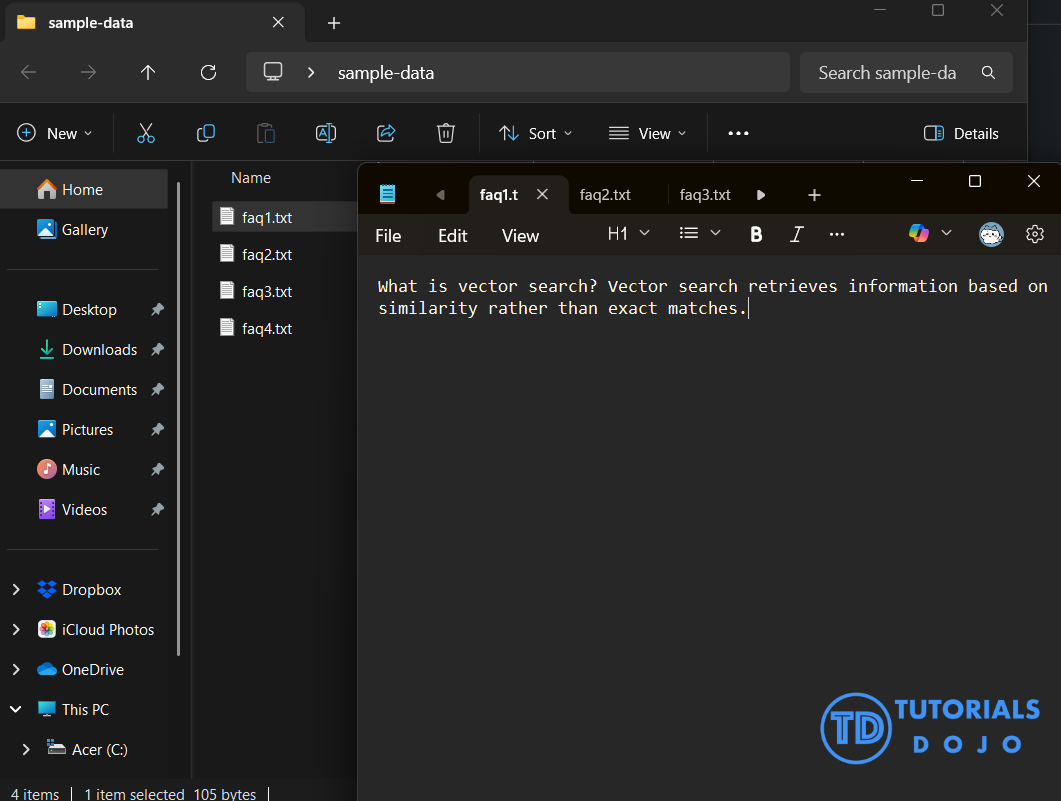
Step 1: Prepare Your Sample Data

Step 2: Log In to AWS Management Console
Step 3: Generate Vector Embeddings with SageMaker
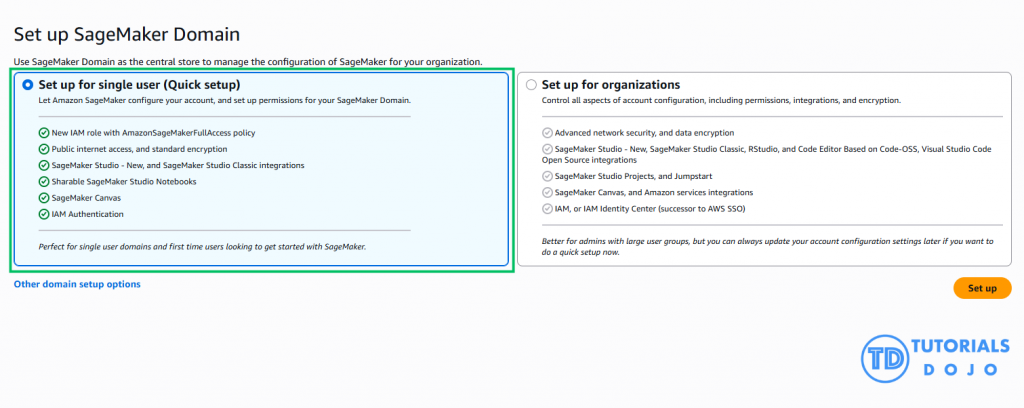
SageMaker Domain
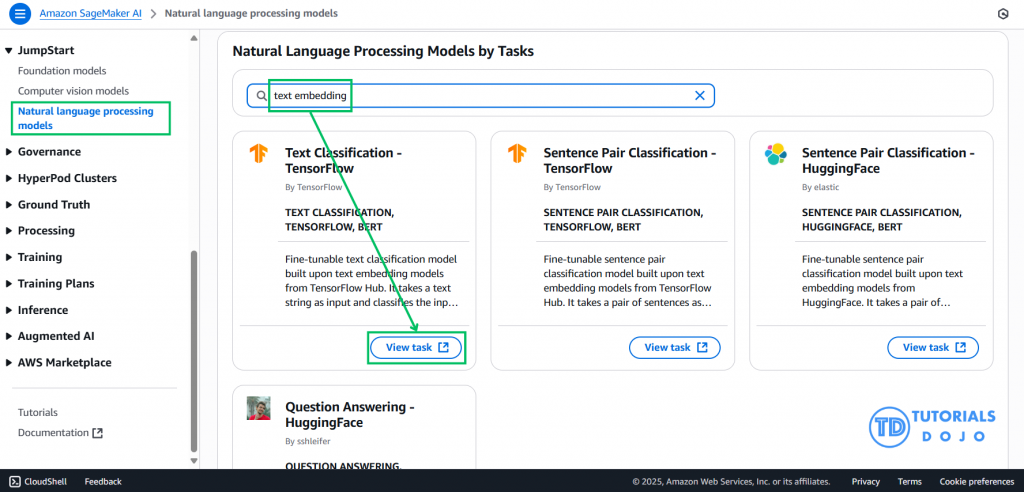
SageMaker JumpStart
SageMaker Studio
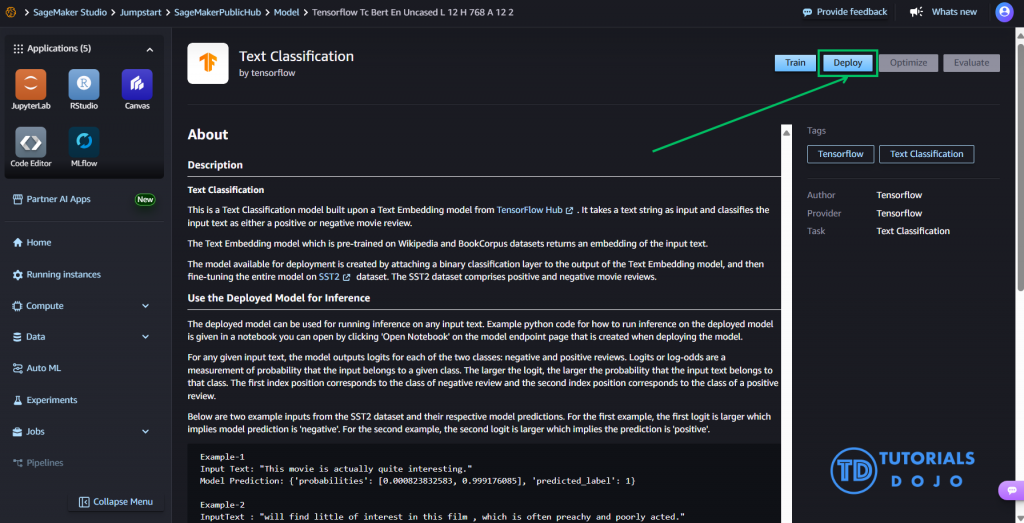
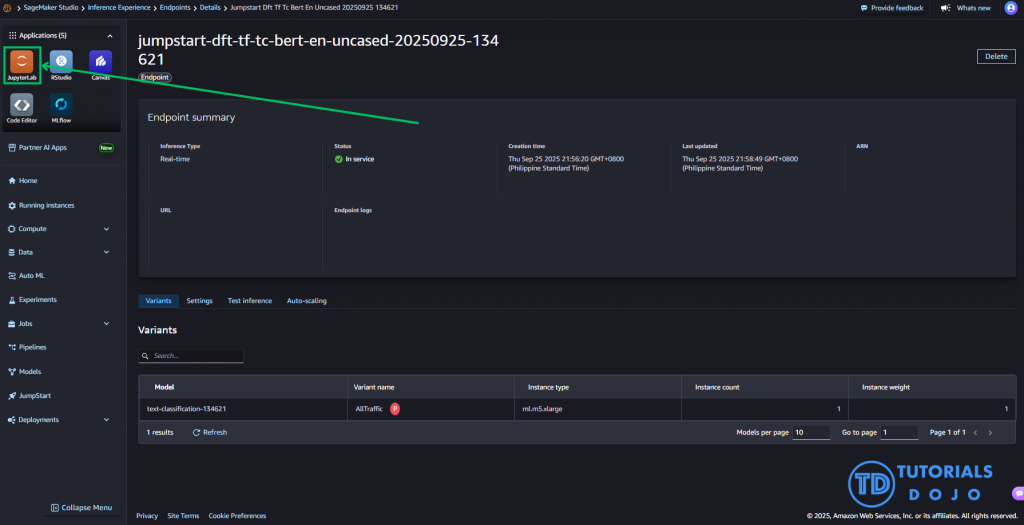
JupyterLab Application
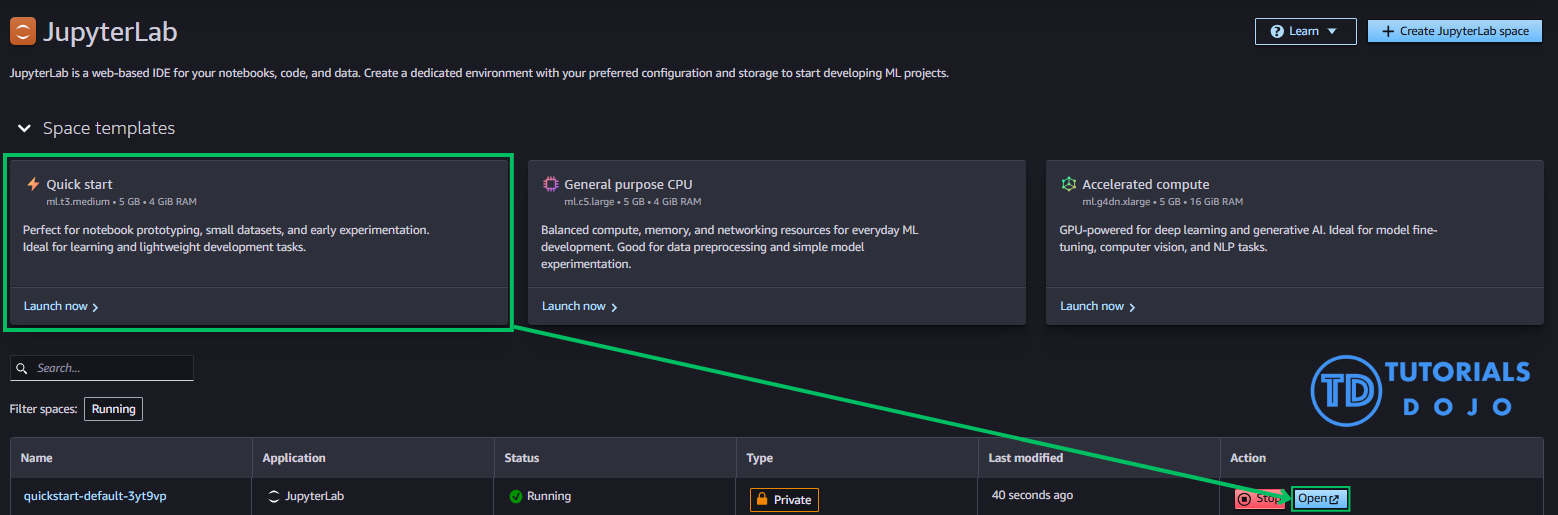
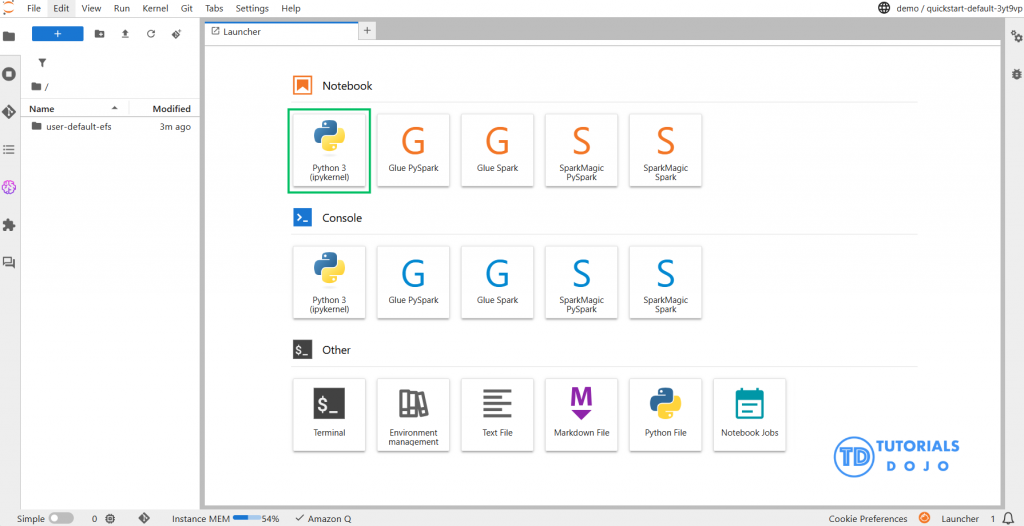
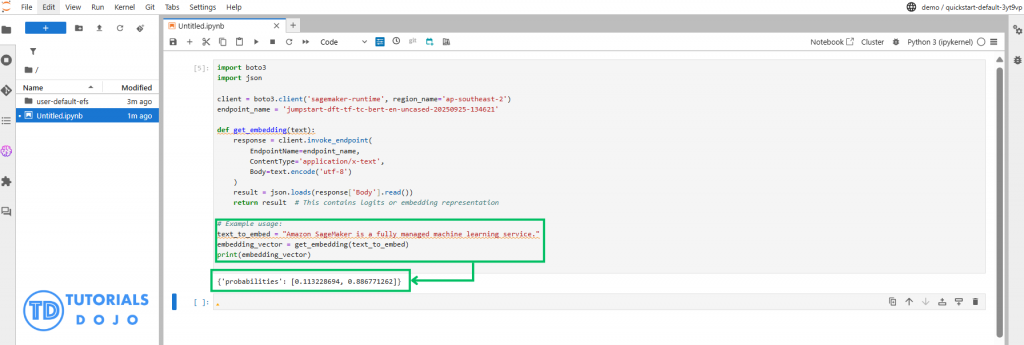
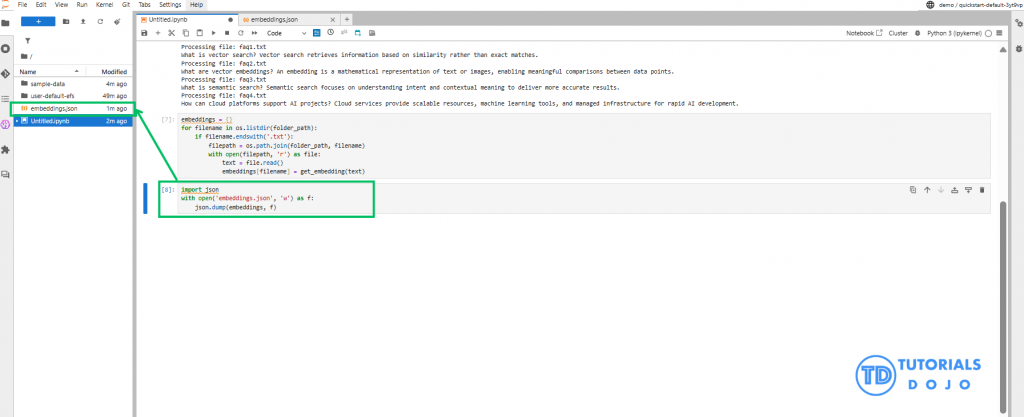
Step 4: Store Data and Embeddings in Amazon S3
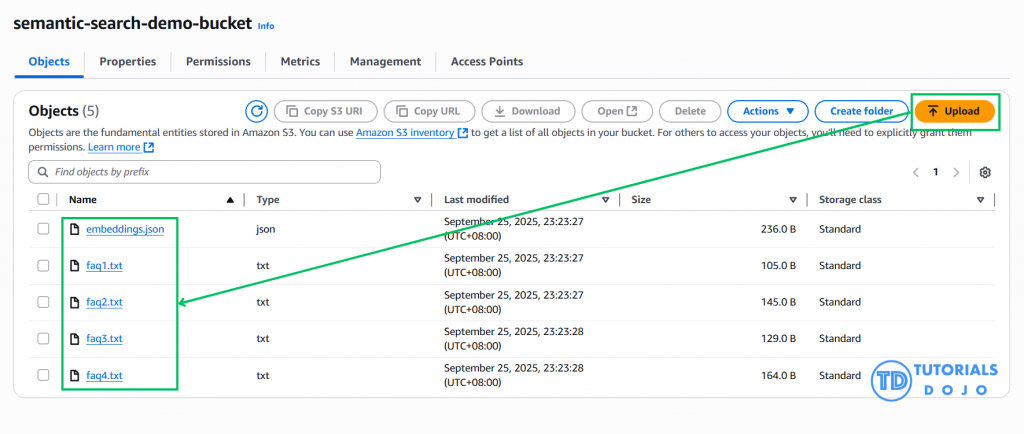
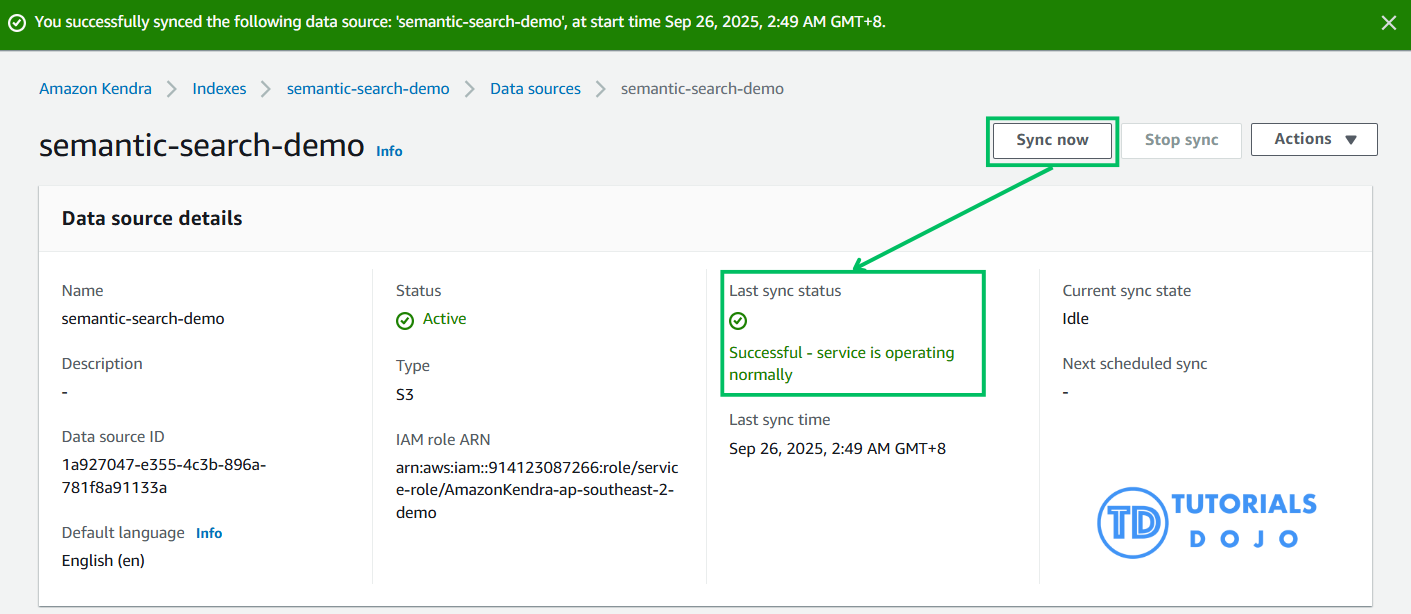
Step 5: Create an Amazon Kendra Index
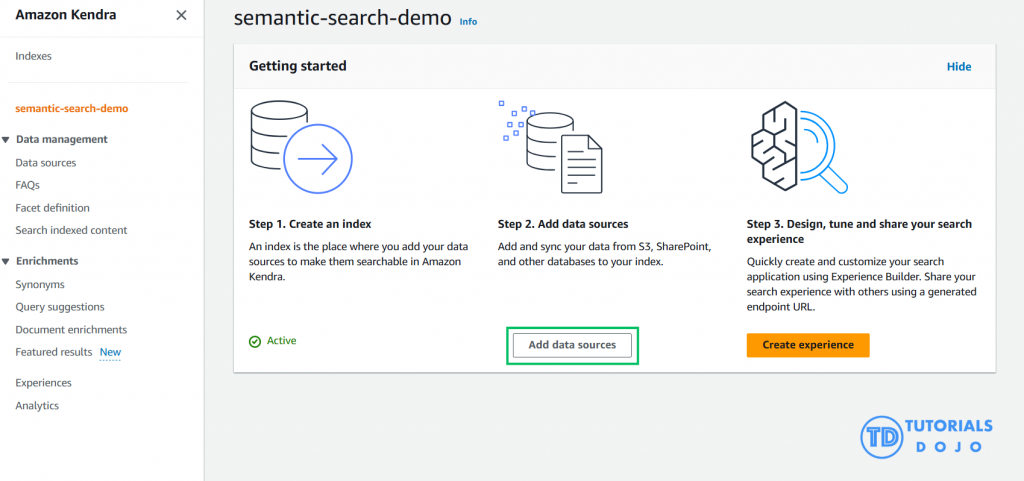
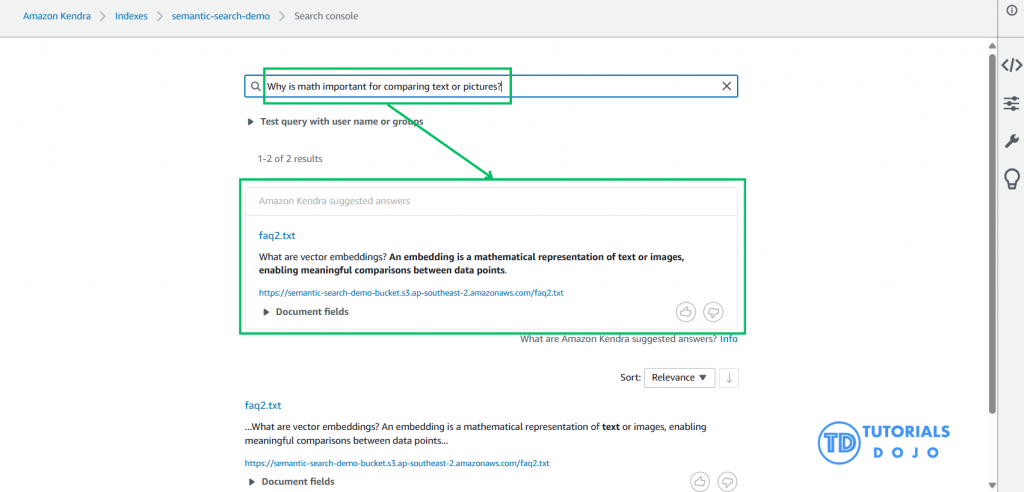
Step 6: Query Your Kendra Index for Vector Search

Step 7: Clean Up to Avoid Charges (Optimal but Recommended)
Managing Performance and Costs
Real-Life Use Cases with AWS Vector Search
Smarter Knowledge and Retail Experiences with Vector Search
Advancing Healthcare and Financial Security
Conclusion
References:
🐰 25% OFF Easter Sale! Use code TDPLAYCLOUD-04022026 for 10% OFF ALL PlayClouds Subscription & 5% OFF gift cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





