Large language models are powerful, but power alone is not enough for enterprise AI. A model may generate fluent responses, yet still miss your company’s tone, fail structured validation rules, or produce outputs that are technically correct but operationally unusable. The real challenge is not just making models smarter, it is teaching them what better means in your specific business context. This is exactly where Reinforcement Fine-Tuning (RFT) in Amazon Bedrock changes the game.

The Problem with Traditional Fine-Tuning
Most model customization strategies start with Supervised Fine-Tuning (SFT). In SFT, you provide input-output pairs that represent correct responses. The model studies those examples and adjusts its weights accordingly.
This works well for classification, summarization, and straightforward structured tasks. However, several limitations appear in production:
- First, SFT requires a large amount of labeled data. Collecting and annotating high-quality examples is expensive and time-consuming.
- Second, the model may overfit to examples and struggle when real-world inputs differ slightly from training data.
- Third, SFT teaches correctness but does not always capture human preferences such as tone, empathy, formatting standards, or reasoning depth.
- Finally, if business logic changes, retraining becomes necessary, which increases operational overhead.
For organizations building customer agents, reasoning systems, or compliance-sensitive workflows, these limitations quickly become bottlenecks.

What Is Reinforcement Fine-Tuning (RFT)?
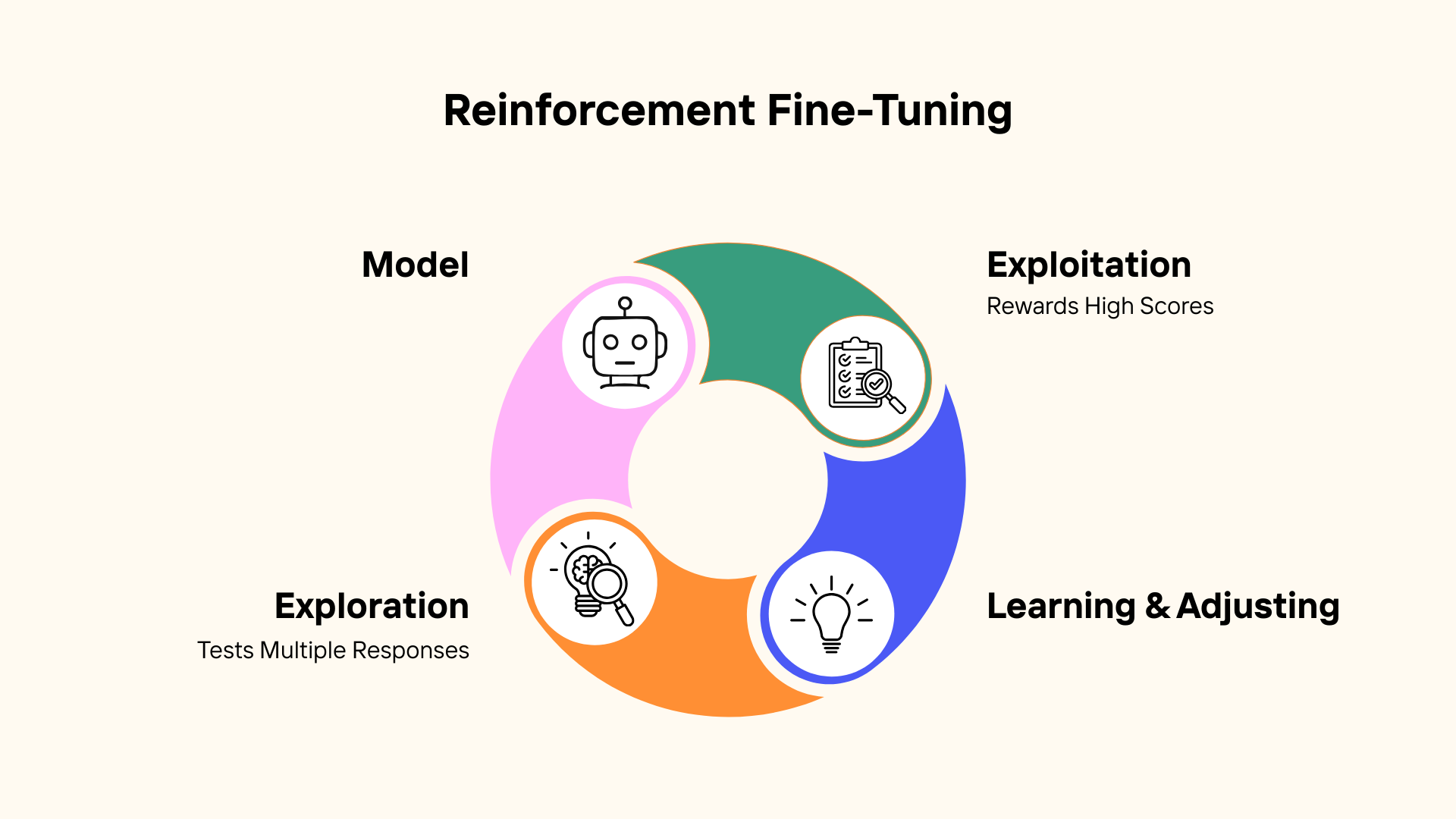
Reinforcement Fine-Tuning introduces a feedback-driven learning loop. Instead of only showing the model the “right answer,” you allow it to generate multiple candidate responses. Each response is scored using a reward function. Higher-scoring responses influence the model more strongly, gradually shifting its behavior toward outputs that meet your defined quality criteria.
Two core concepts power this approach:
- Exploration allows the model to test multiple possible responses for a given prompt.
- Exploitation strengthens patterns that consistently receive higher reward scores.

Over time, the model does not just memorize examples. It learns which patterns lead to better outcomes according to your scoring logic.
How Reinforcement Fine-Tuning Works in Amazon Bedrock
AWS designed RFT inside Amazon Bedrock to be accessible through the console, removing the need to build custom reinforcement pipelines.
The workflow is organized into three main stages.
Step 1: Provide Your Dataset
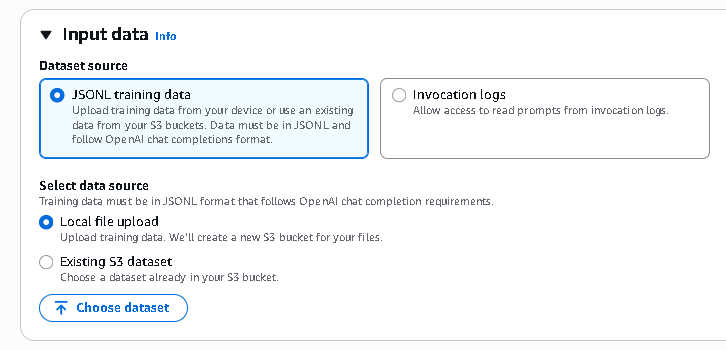
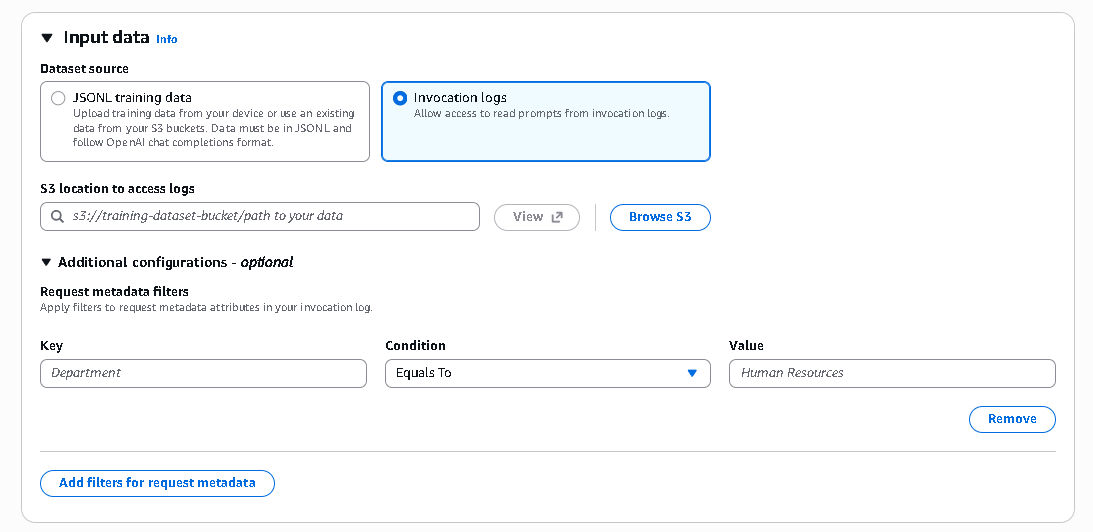
You can upload training data in JSONL format, reference datasets stored in Amazon S3, or even use invocation logs from existing model interactions.
This flexibility allows teams to reuse production data rather than creating entirely new training datasets from scratch.
Step 2: Define What “Good” Looks Like
The reward function defines how outputs are evaluated. Amazon Bedrock provides two primary approaches.
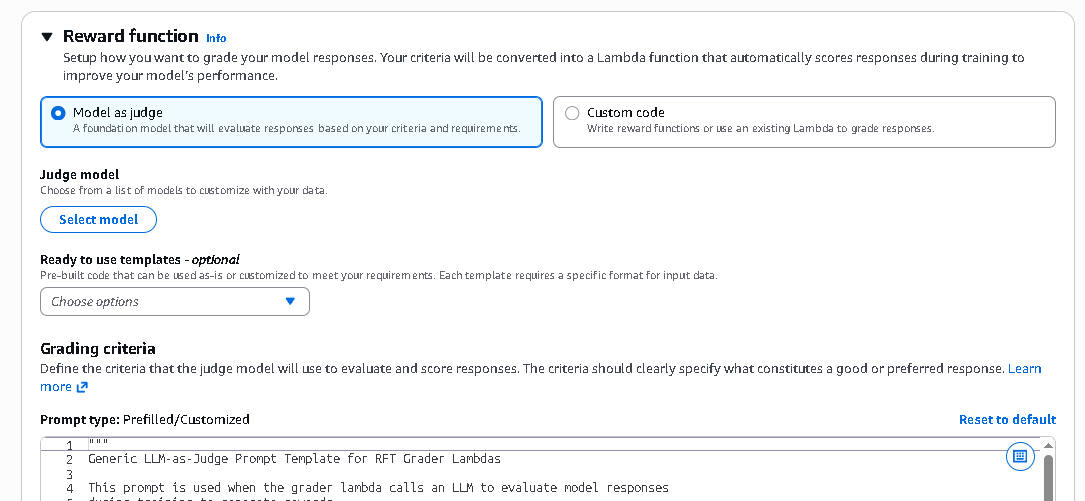
The first approach is Model-as-a-Judge templates. These templates support use cases such as instruction following, summarization quality, reasoning evaluation, and RAG faithfulness. You can edit evaluation rubrics to match your standards. A judge model evaluates candidate outputs and assigns a score.
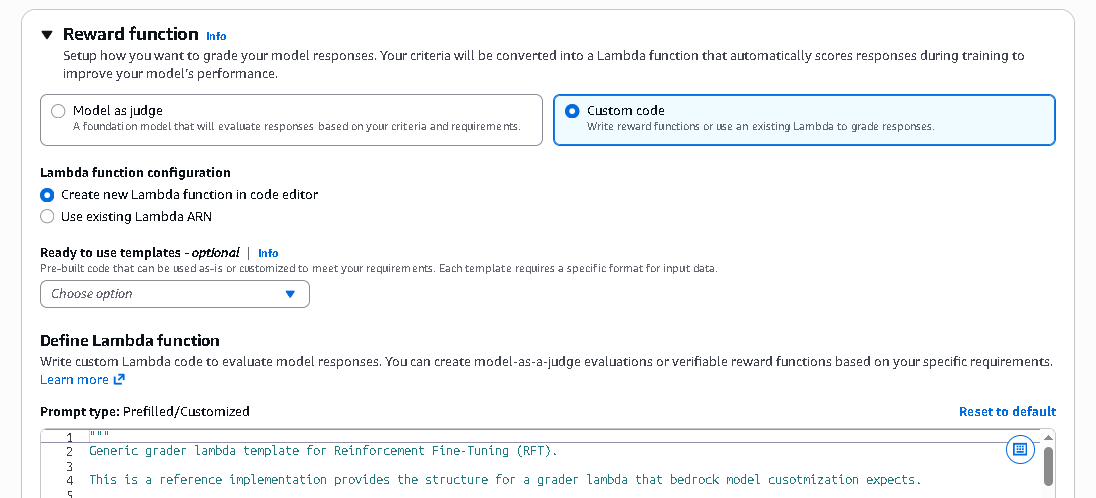
The second approach is creating a custom AWS Lambda reward function. This option gives you full control over scoring logic. You can validate structured JSON output, verify mathematical correctness, enforce formatting rules, or encode specific business constraints. The Lambda function simply returns numerical reward scores, and Bedrock handles the reinforcement loop automatically.
Step 3: Start Training
Once your reward strategy is defined, you launch the training job. Behind the scenes, the model repeatedly generates outputs, evaluates them through your reward function, and adjusts its weights accordingly.
During training, you can monitor metrics such as training rewards, validation rewards, episode lengths, and optimization indicators. This transparency provides insight into how and whether the model is improving.
Running RFT in Amazon Bedrock
To try Reinforcement Fine-Tuning in the console, follow these steps.
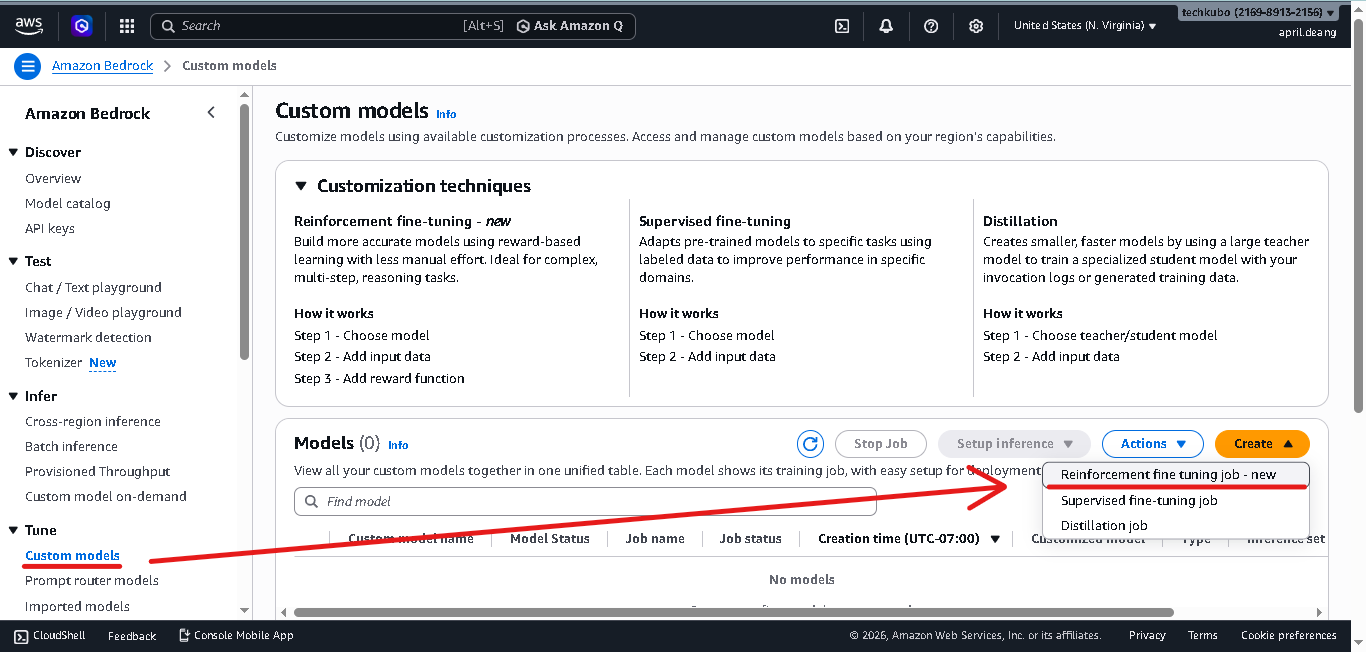
Create the Reinforcement Fine-Tuning Job
- First, navigate to Amazon Bedrock console → Tune → Custom models → Create → Reinforcement fine tuning job

- Input a unique name within your AWS account
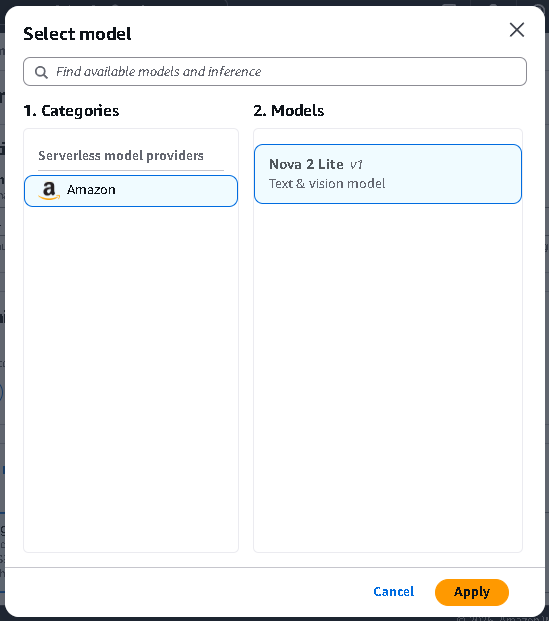
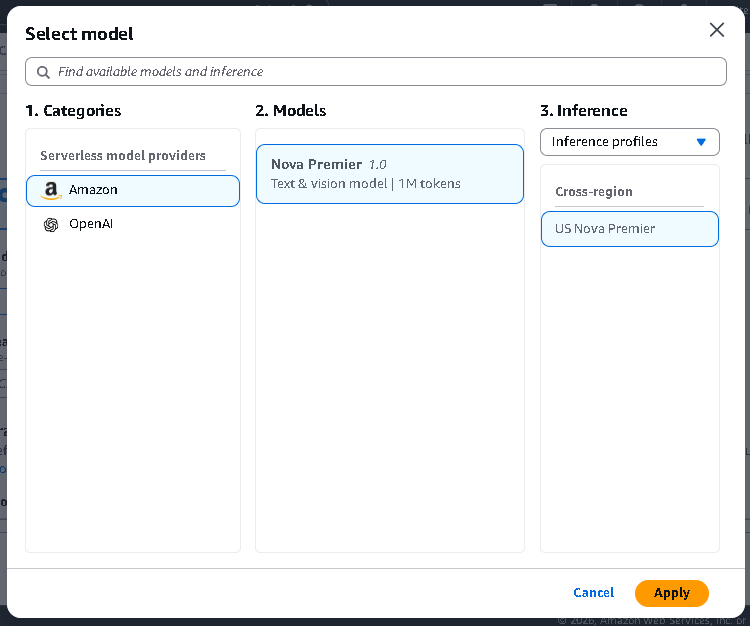
- Click Select model
- Select a model based on what type of data you are training with, and click Apply

Upload Your Training Dataset
- Next, upload your dataset either from your local machine, S3 Bucket
- Or from Invocation logs, by specifying the S3 Bucket path, and configuring Request metadata filters
Configure the Reward Function
-
This section is where you configure how responses will be evaluated. Your grading criteria are transformed into a Lambda function that runs during training. Every time the model generates candidate responses, this function assigns numerical reward scores.
Those scores guide the reinforcement loop. Higher-scoring outputs influence the model more strongly, gradually improving performance based on your defined standards.
The “Model as Judge” option allows you to use a foundation model to evaluate responses automatically. Instead of writing scoring logic manually, you describe your grading criteria. The selected judge model reads both the prompt and the generated response, then assigns a score based on how well the response satisfies your requirements.
This is useful when evaluating qualities like Instruction adherence, Clarity and completeness, Reasoning quality, Tone and professionalism, RAG faithfulness. It is ideal if you want flexible, language-aware evaluation without writing custom code. -
If your use case requires strict verification logic, you can choose “Custom Code.” This allows you to write your own AWS Lambda reward function or use an existing Lambda. Inside this function, you can implement programmatic checks such as Validating structured JSON output, Checking numerical accuracy, Verifying format constraints, Applying business rule logic, Performing regex validation
Your function must return numerical reward scores. Bedrock then uses those scores in the reinforcement loop. This option is powerful for tasks where correctness is objectively verifiable, such as financial calculations or structured API outputs.
Model as Judge
- If you choose the Model-as-Judge option, you must select which foundation model will act as the evaluator. Click Select model.
- The judge model is responsible for reading outputs and assigning scores. Different models may offer different strengths in reasoning depth or evaluation consistency. Selecting the appropriate judge model ensures your grading reflects the complexity and standards of your task.
(Optional) Use Pre-Built Reward Templates
-
Amazon Bedrock provides pre-built reward templates for common use cases. These templates include predefined Lambda logic and scoring structures. You can use them as-is or modify them to suit your needs.
Each template expects a specific input format, so your dataset must match the required structure. Templates are helpful if you want to get started quickly without building evaluation logic from scratch.
When training completes, enable on-demand inference. You can test the fine-tuned model in the Bedrock playground and even compare its outputs side by side with the base model to observe improvements.

Define Grading Criteria Clearly
-
This is where you define what qualifies as a good response.
Your criteria should be clear, measurable, and aligned with your business goals. For example, you may define that a high-quality response must Directly answer the question, Provide structured reasoning, Follow formatting guidelines, Avoid hallucinated information, and Maintain professional tone.
The more precise your grading criteria, the more effectively the reinforcement loop can optimize the model. In reinforcement fine-tuning, clarity in grading is critical. The reward signal drives learning. If the criteria are vague, improvement will also be vague.

Configure Training Settings
- Choose S3 location to store training output metrics, input data report, and error reports if any.
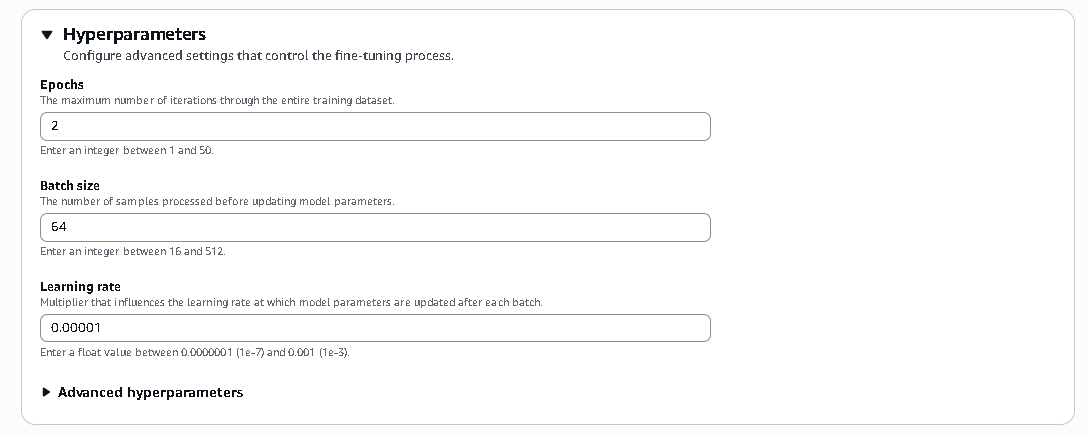
- These settings control how the model learns during fine-tuning. Epochs define how many times the model reviews the entire dataset, batch size determines how many samples are processed before updating weights, and learning rate controls how aggressively the model adjusts its parameters after each update.

Set IAM Role Permissions

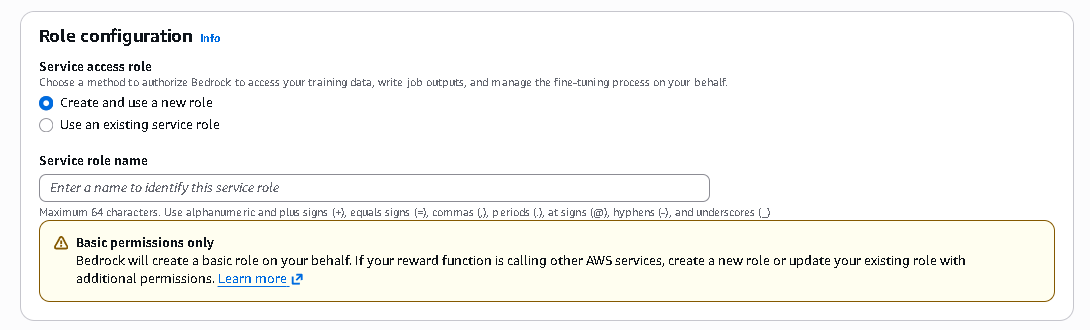
- This section defines how Amazon Bedrock is authorized to access your training data, store outputs, and manage the fine-tuning job either by automatically creating a new IAM service role or by using an existing role with the required permissions.
- Once finished, click Create.
Enterprise Example: Salesforce and RFT
A strong enterprise case comes from Salesforce and their Agentforce platform. Salesforce required models that balanced high accuracy, low latency, and cost efficiency. Rather than relying exclusively on very large frontier models, they fine-tuned smaller models using reinforcement techniques.
By combining supervised fine-tuning with reinforcement-based methods, they achieved significant improvements in instruction adherence and task completion performance. The result was competitive accuracy compared to larger models, but at lower cost and latency.
This demonstrates an important principle: Reinforcement Fine-Tuning can elevate smaller models to enterprise-grade performance levels when aligned with well-designed reward signals.
Why RFT Is Important for Developers
Reinforcement learning traditionally required deep research expertise, custom infrastructure, and complex experimentation pipelines. Amazon Bedrock abstracts this complexity.
With RFT, developers can define reward logic, launch training, monitor metrics, and deploy with on-demand inference all within a managed environment. The benefits include lower data requirements, better alignment with human preferences, improved reasoning consistency, and scalable deployment without infrastructure management.
Conclusion
Reinforcement Fine-Tuning shifts the focus of model customization from static correctness to dynamic quality alignment. Instead of asking whether the model memorized examples, organizations can now ask whether the model learned what “better” means for their specific workflows.
By integrating reinforcement learning principles into a developer-friendly console experience, Amazon Bedrock lowers the barrier to advanced model alignment. For enterprises building AI-driven agents, reasoning systems, or structured automation workflows, RFT represents a practical and powerful next step in generative AI customization.
References:
🌸 25% OFF All Reviewers on our International Women’s Month Sale! Save 10% OFF All Subscriptions Plans & 5% OFF Store Credits/Gift Cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin





