As we progress in the age of AI, we chase the best, the fastest, and the most accurate model available, especially in the domain of Large Language Models (LLMs) and Vision Language Models (VLMs). We use them across creative and technical tasks, yet rarely stop to consider the consequences of their training, whether in frontier labs or on private machines that refine and distill them. Our focus tends to be twofold. First: can this model help me do X or Y tasks? Second: how fast and how accurately can it do those tasks? Will it actually save time, or should I just do it myself because it’s too slow or unreliable? But as our relationship with AI deepens (yes, across generative, predictive, agentic systems, etc) people are starting to ask harder questions about safety and alignment. Are these models, capable of statistically approximating vast portions of human knowledge, aligned with what we actually want? Or is that alignment just a surface-level illusion that keeps us comfortable enough to keep using them? Quick review, let’s start with how LLMs and VLMs work. The current AI wave is powered by generative models, particularly large language models. These systems generate new content based on input text, passing it through pre-trained weights to produce a statistically plausible response. Due to the scale of their training, they build high-dimensional relationships across vast amounts of internet data. To put it simply: when you type a prompt, the model tokenizes it (breaks it into pieces), runs inference on each token, predicts possible next tokens, samples from a shortlist of candidates, and returns the result. That’s it, pure computation. No intent, no understanding, no inner state. VLMs extend this by adding vision. They are multimodal: they can process both text and images. A vision encoder (often a transformer) converts images into tokens, which are then fed into the large language model. From there, the same prediction process applies, conditioned on both text and visual input. These models don’t “understand” in the human sense. They predict what comes next. Alignment, then, is about shaping those predictions so they match human expectations. Because these models predict rather than understand, they hallucinate. Producing responses that sound convincing but are wrong. Think of it as a highly useful liar: reliable often enough that you trust it, until it quietly fails and you don’t notice. You’ve probably seen this from code that doesn’t run, explanations that fall apart under scrutiny, answers that feel right but aren’t. There are two main causes: 1. Probabilistic Sampling: Training + Query = Response This is a balancing act between correctness and plausibility. LLMs don’t read as we do; they process tokens sequentially and generate output texts step by step. Attention mechanisms help, but they introduce tradeoffs between memory and speed. Longer or more complex inputs increase the chance of hallucination. 2. Sampling Mechanics: Top-p and Temperature The model doesn’t always pick the single most likely word. Instead, it samples from a distribution: Temperature controls randomness. Lower values make outputs more deterministic; higher values increase variation (and risk). Top-p (nucleus sampling) restricts choices to a subset of probable tokens whose cumulative probability meets a threshold. So the response becomes: This is why the same prompt can yield different answers and why correctness is never guaranteed. A simple example: ask older models how many “r”s are in a strawberry. Many failed. Some said two, others zero. Larger models have improved, but smaller or on-device models still struggle due to performance tradeoffs. The core issue remains: Fluency is not truth. VLMs expand capability in powerful ways. A model that can transcribe meetings, reads slides, and generates minutes in real time would have been unthinkable a decade ago. But like humans, VLMs are prone to misinterpretation and false assumptions. They inherit these tendencies from us. Since they are trained on internet-scale data; the largest human knowledge repository we’ve ever built, they also absorb its biases, shortcuts, and errors. During reinforcement learning from the human feedback (RLHF) phase, these patterns can be amplified. What feels “natural” or “human-like” may be rewarded, even when it’s flawed. There’s also a structural issue: much of this feedback work is done in regions where labor is cheaper. These annotators are skilled, but they operate within specific cultural and economic contexts. That inevitably shapes the model. Even if we reduce cultural or geographic bias, individual bias remains. No human is neutral, and those biases propagate into the system. Despite these risks, we are not standing still. Current safeguards include content filters, RLHF alignment, platform policies, and various forms of model restriction. But there is no unified standard. Different organizations define safety differently. What one model allows, another blocks. What one system treats as safe, another flags as dangerous. There is no central authority defining alignment, only fragmented efforts shaped by competing priorities. And those priorities matter. The people building these systems are influenced by incentives such as profit, competition, and ideology factors that end users have little control over. So if we talk about “AI safety,” we have to ask: what does that even mean? Is it a technical problem? A moral one? A philosophical one? There is no clean answer. And “I don’t know” is an honest position. What we can do is implement safeguards that move us closer to our own definition of ethical AI, while acknowledging that perfect alignment is likely unattainable. Human values are inconsistent, and the data reflects that. There is no neutral model trained on non-neutral data. There’s no clean resolution here. Different people want different things. Some aim to help. Others aim to profit. Some use AI to build communities; others use it to divide them. Some applications preserve life; others are built for harm. As AI systems scale, these tensions become more visible. VLMs in military systems. LLMs in customer service. High-stakes decisions shaped by probabilistic outputs. This raises a question: Should AI be more capable or more constrained? And more importantly: do we even agree on what those constraints should be? AI alignment is not something you inherit, it’s something you build into your systems. Design for failure. Make it predictable. Contain its impact. Keep humans in the loop. The goal is not perfection but rather controlled failure

LLMs/VLMs: What Are They?
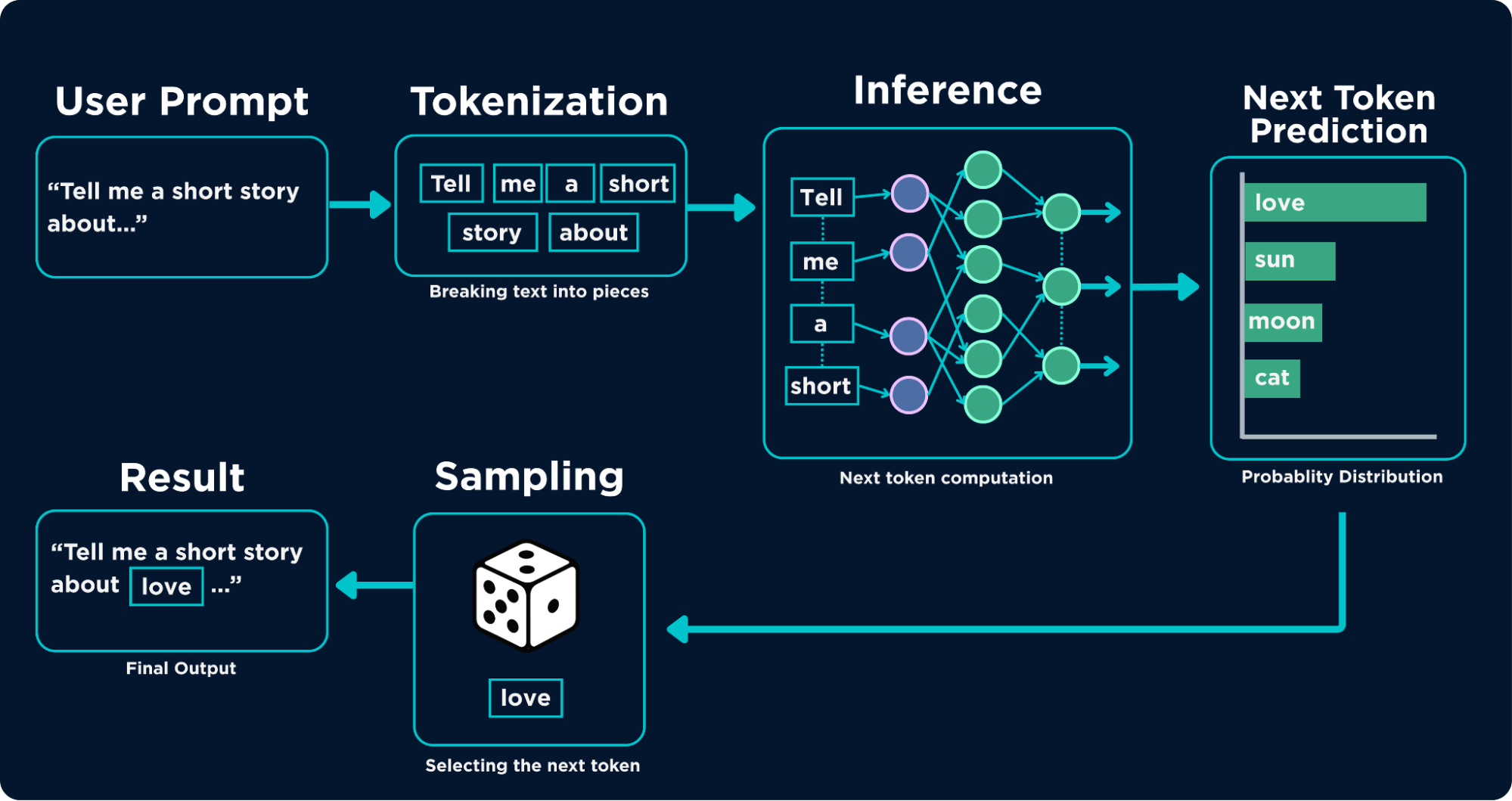
The Problem with LLM Hallucinations

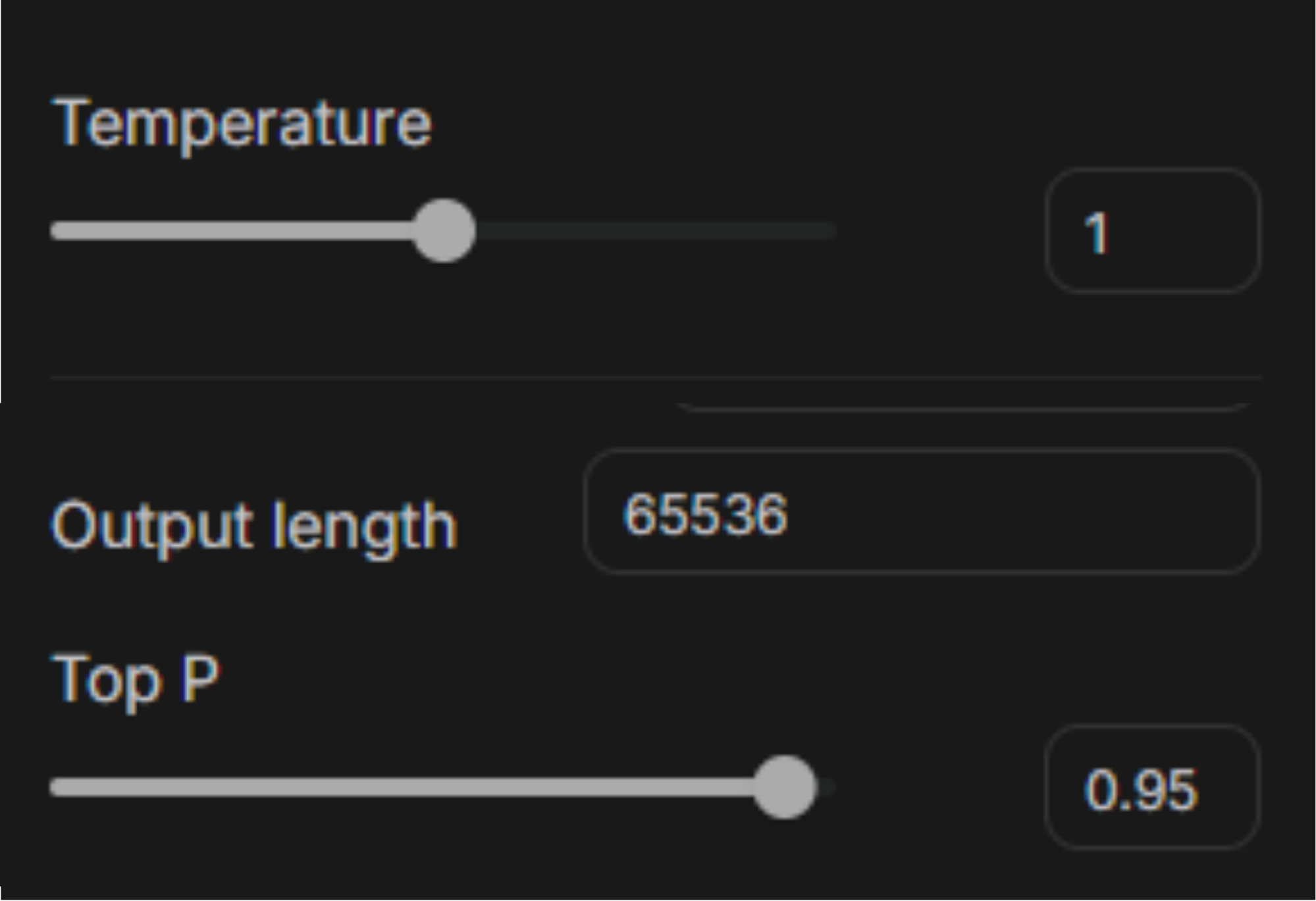
LLM output = sampled choice from a probability distribution shaped by temperature and top-p.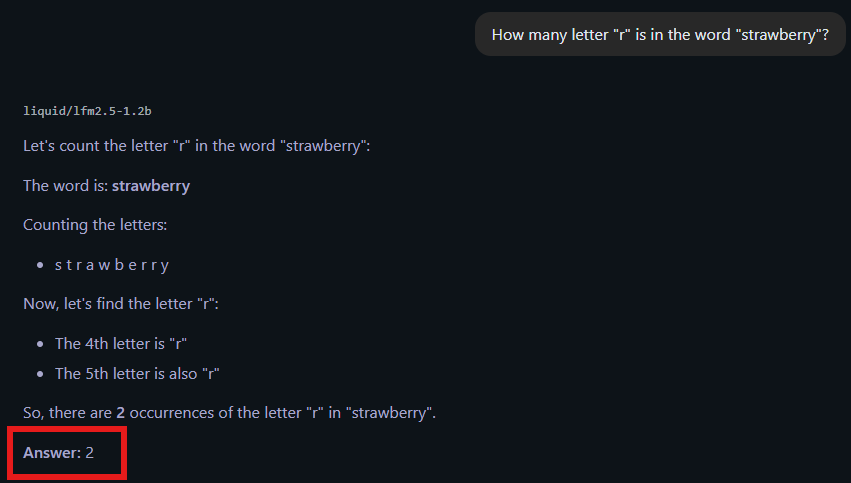
The model is optimized for plausibility, not correctness.Vision-Language Models and the Risk of Misinterpretation
AI Guardrails Today: Policies, Not Consensus

Can AI Ever Be Fully Aligned?


Reader, take this with you:
REFERENCES:
🐰 25% OFF Easter Sale! Use code TDPLAYCLOUD-04022026 for 10% OFF ALL PlayClouds Subscription & 5% OFF gift cards!

Learn AWS with our PlayCloud Hands-On Labs

$2.99 AWS and Azure Exam Study Guide eBooks

New AWS Generative AI Developer Professional Course AIP-C01

Learn GCP By Doing! Try Our GCP PlayCloud

Learn Azure with our Azure PlayCloud

FREE AI and AWS Digital Courses

FREE AWS, Azure, GCP Practice Test Samplers


Subscribe to our YouTube Channel

Follow Us On Linkedin


Vince is a BSIT student, academic researcher, and advocate for diversity and inclusion within the technology sector. She brings a diverse portfolio of experience spanning IT infrastructure management, compliance, security consulting, and systems evaluation. Her professional background includes work on industrial machine programming, software assessment, and IT operational support. In addition to her technical pursuits, Vince has led operations for AWS BuildHers+ PH, and presented award-winning research at academic conferences. She remains committed to fostering safer, more inclusive environments that empower diverse talent to succeed in the technology industry.




{kind=link}